namenode datanode理解


除了对文件系统本身元数据的管理之外,NameNode还需要维护整个集群的机架及DataNode的信息、Lease管理以及集中式缓存引入的缓存管理等等。这几部分数据结构空间占用相对固定,且占用较小。
测试数据显示,Namespace目录和文件总量到2亿,数据块总量到3亿后,常驻内存使用量超过90GB。
DataNode负责存储和检索数据块,他受客户端和Namenode调度,并且他会定期向NameNode发送本节点上所存储的块列表,这就是为什么NameNode并不是永久保存各个节点块的信息原因了。
能看到NameNode的重要性,因为如果NameNode挂掉之后,无法根据DataNode上的数据重建文件。所以一般有两种机制进行对NameNode的容错。第一将NameNode上的元数据信息持久化到本地磁盘的同时,同时备份到一个挂载的远程网络文件系统上NFS。第二使用辅助NameNode,辅助NameNode会定期通过编辑日志合并镜像文件,防止编辑日志过大。但是他存在的问题在于总是滞后于NameNode的。所以一般可以将远程NFS的元数据复制到辅助NameNode上,辅助NameNode作为新的NameNode。
那么NameNode、DataNode、SecondaryNameNode存储结构是什么样子的呢。
NameNode存储结构:
{dfs.namenode.name.dir}
|---VERSION
|---fsimage
|---edits
首先看下VERSION里面是什么

namespaceID:代表的是文件系统唯一标识,文件系统首次格式化时产生。没有注册到namenode之前的datanode都不知道namespaceID,所以可以通过这个来检查新建的datanode
clusterID:集群ID
cTime:NameNode存储系统创建时间,首次格式化文件系统这个属性是0,当文件系统升级之后,该值会更新到升级之后的时间戳
storageType:说明该存储目录是namenode的数据结构
layoutVersion:是一个负整数,用来描述HDFS持久化数据结构的版本的。这个版本与Haoop版本号无关,当文件系统布局发生改变他就回减一,但是此时HDFS也需要升级,否则新的namenode无法使用。
blockpoolID:是当前NameNode管理的数据块池ID,对于Federation HDFS,不同的NameNode管理不同的数据块池,同一个DataNode管理多个数据块池。blockpoolID的命名方式如下:
BP-<random num><namenode ip><namenode create time(UTC)> 在dn上会有这个桐木目录来存储数据

编辑日志和镜像文件
fsimage镜像文件存储着文件系统所有目录和文件的元数据信息即inode序列化信息。每一个inode是文件或目录的元数据内部描述方式,对于文件存储比如副本级别、修改时间、块大小等等。fsimage并不存储描述datanode的信息。因为datanode加入集群后会定期向namenode发送块的映射信息。
edits编辑日志如果这样会不断增长,这样每当重启namenode时候会比较慢,这时候文件系统就处于离线状态,这并不是用户想要的。可以通过运行辅助namenode来解决。
为主Namenode中的元数据创建检查点,进行编辑日志和镜像文件合并。
(1)辅助namenode要求主namenode停止使用edits文件,暂时使用新的edits文件。
(2)辅助namenode从主namenode那里获取fsimage和edits文件
(3)辅助namenode将fsimage加入到内存,然后根据edits执行文件操作,创建新的fsimage
(4)辅助namenode将新的fsimage发送到主namenode中
(5)主namenode用新的fsimage替代原先的fsimage,并且使用(1)中的eits代替旧的edits文件。
这就是为什么SecondaryNamenode也需要一台独立服务器的原因了。他的操作和namenode差不多
这个创建检查点需要两个配置控制,第一就是dfs.namenode.checkpoint.period属性设定,每隔多长时间创建一次检查点,默认是3600即一个小时。第二就是dfs.namenode.checkpoint.txns这个hadoop1中是fs.checkpoint.size,我在hadoop2.2中没有找到与之类似,但是估计是这个,当编辑日志达到这个配置的大小即使没有到达之前配置的时间也会创建检查点。
SecondaryNameNode中的current目录与namenode的一样,因为创建检查点不仅为主namenode创建检查点数据,也是辅助namenode也有一份检查点数据,用来备份namenode元数据,尽管他不是最新的。如果主namenode挂了,并且没有NFS,可以使用SecondaryNamenode作为主namenode,当dfs.namenode.name.dir中没有元数据的时候就会从dfs.namenode.checkpoint.dir中载入检查点数据。这就是为什么两者目录为什么设计成一样的原因了,不用担心覆盖现有的元数据。
DataNode的目录结构:
{dfs.datanode.data.dir}
|--VERSION
|--BP-792156149-127.0.1.1-1431433217275
|--current
|--finalized
|--VERSION
VERSION内容与namenode类似,他的namespaceID是datanode首次向namenode访问获取的,storageID是每个datanode的id,namenode通过他来区分不同的datanode
看到BP-792156149-127.0.1.1-1431433217275这个让我明白了namendoe上面的那个blockpoolId了,这时hadoop1中没有的,在这个BP-792156149-127.0.1.1-1431433217275目录里面放着这个块池的current,里面还有一个VERSION这个VERSION才有namespaceID,而外层那个只有storageID
在hadoop2中数据块存放到块池中的finalized中以blk_为前缀,有两种类型:块文件和块文件元数据信息(以meta结尾)块文件存储数据,块文件信息存储版本号以及校验和等信息。
如果dfs.namenode.data.dir指定了不同磁盘的多个目录,数据会以轮转的方式写入到磁盘中,当同一个datanode不会存储相同的块。
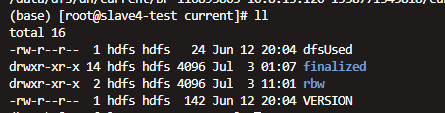
dfsused:磁盘使用率
finalized 表示数据副本状态
|
块状态 |
存储目录 |
说明 |
|
Finalized |
${BP_HOME}/current/finalized |
表示该副本已经完成了所有数据的写入。 |
|
RBW |
${BP_HOME}/current/rbw |
表示该副本正在写入或追加数据。 |
|
RWR |
${BP_HOME}/current/rbw |
如果DataNode宕机或重启,处于RBW状态的副本将转换为RWR状态,不会在接受新数据的写入。 |
|
RUR |
${BP_HOME}/current/rbw |
当租约到期,NameNode将为客户端关闭其所占用的副本,这将使该副本进入RUR状态。 |
|
Temporary |
${BP_HOME}/tmp |
表示该副本正在被创建。 |
*${BP_HOME}为${datanode.data.dir}/current/<blockpool_id>
一个数据块由两个文件组成,一个为块数据文件(以blk_为前缀),一个为该数据块的元数据文件(以.meta为后缀),该文件包括了数据块的版本、类型和一系列区域检验和。当数据目录中的块文件达到64个之后,DataNode会在该目录下建立一个子目录(subdirn),将这些块文件移动到该目录下,以避免一个目录存储过多的文件,影响了系统的性能

namenode datanode理解的更多相关文章
- HDFS Namenode&Datanode
HDFS Namenode&Datanode HDFS 机制粗略示意图 客户端写入文件流程: NN && DN Namenode(NN)工作机制 NN是整个文件系统的管理节点. ...
- hadoop stop-dfs.sh 无法停止 namenode datanode
原因: HADOOP_PID_DIR 默认为 /tmp 目录,如果长期不访问/tmp/目录下的文件,文件会被自动清理,因此 stop-dfs.sh 无法根据 pid 停止 namenode, data ...
- NameNode & DataNode
NameNode类位于org.apache.hadoop.hdfs.server.namenode包下. NameNode serves as both directory namespace man ...
- Hadoop学习笔记(老版本,YARN之前),MapReduce任务Namenode DataNode Jobtracker Tasktracker之间的关系
一.基本概念 在MapReduce中,一个准备提交执行的应用程序称为“作业(job)”,而从一个作业划分出的运行于各个计算节点的工作单元称为“任务(task)”.此外,Hadoop提供的分布式文件系统 ...
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
- 【Hadoop】hdfs的秘密,namenode,datanode,yarn,安全模式,fsimage,edits...
1.bin/hdfs namenode -format ** 注意事项 1.在配置好了配置文件之后,首次启动之前,做初始化操作 2.在后续启动的时候,不需要再初始化 3.初始化的一些影响 一.初始化操 ...
- [Hadoop异常处理] Namenode和Datanode都正常启动,但是web页面不显示
异常 namenode和data都正常启动 但是web页面却不显示,都为零 解决办法一: 在hdfs-site.xml配置文件中,加入 <property> <name>dfs ...
- HDFS体系结构(NameNode、DataNode详解)
hadoop项目地址:http://hadoop.apache.org/ NameNode.DataNode详解 (一)分布式文件系统概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配 ...
- datanode与namenode的通信
在分析DataNode时, 因为DataNode上保存的是数据块, 因此DataNode主要是对数据块进行操作. A. DataNode的主要工作流程1. 客户端和DataNode的通信: 客户端向D ...
随机推荐
- 使用Aria2+Aria2Ng+OneIndex+OneDrive建立不限流量/离线BT下载/在线观看网盘/在线存储分享平台
获取OneDrive 自行搜索或者宝购买 安装 1.安装宝塔 #Centos系统 yum install -y wget && wget -O install.sh http://do ...
- LC 425. Word Squares 【lock,hard】
Given a set of words (without duplicates), find all word squares you can build from them. A sequence ...
- javascript之DOM(Document Object Model) 文档对象模型
<html> <head> <meta http-equiv="Content-Type" content="text/html; char ...
- AXIS 1.4 自定义序列化/反序列化类
axis1.4的CalendarDeserializer 使用的时区是GMT,导致日期显示不准确 private static SimpleDateFormat zulu = new SimpleDa ...
- 提升键盘可访问性和AT可访问性
概述 很多地方比如官网中需要提升 html 的可访问性,我参考 element-ui,总结了一套提升可访问性的方案,记录下来,供以后开发时参考,相信对其他人也有用. 可访问性 可访问性基本上分为 2 ...
- C基础知识(12):可变参数
该功能需要使用<stdarg.h>.函数的最后一个参数写成省略号,即三个点号(...),省略号之前的那个参数是int,代表了要传递的可变参数的总数.该文件提供了实现可变参数功能的函数和宏. ...
- python-Web-数据库-Redis
概述: >>>安装: >>>数据类型: string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合) &g ...
- 微信小程序-T
微信小程序安装完毕后,真机调试及预览(打开调试模式)有数据,其他类型无数据在微信公众号-开发-域名信息中绑定正确的域名即可 配置微信小程序合法域名微信公众号-开发微擎应用-基础设置微信app-site ...
- 【POJ - 3087】Shuffle'm Up(模拟)
Shuffle'm Up 直接写中文了 Descriptions: 给定两个长度为len的字符串s1和s2, 接着给出一个长度为len*2的字符串s12. 将字符串s1和s2通过一定的变换变成s12, ...
- BP原理 - 前向计算与反向传播实例
Outline 前向计算 反向传播 很多事情不是需要聪明一点,而是需要耐心一点,踏下心来认真看真的很简单的. 假设有这样一个网络层: 第一层是输入层,包含两个神经元i1 i2和截距b1: 第二层是隐含 ...