《机器学习实战(基于scikit-learn和TensorFlow)》第七章内容学习心得
本章主要讲述了“集成学习”和“随机森林”两个方面。
重点关注:bagging/pasting、boosting、stacking三个方法。
首先,提出一个思想,如果想提升预测的准确率,一个很好的方法就是用集成的方法。让多种预测器尽可能相互独立,使用不同的算法进行训练。最后以预测器中的预测结果的多数作为最终结果或者将平均概率最高的结果作为最后的结果。
还有没有其他的方法呢,有的。
- Bagging/Pasting方法:每个预测器使用的算法相同,但是在不同的训练集随机子集上进行训练,采样时将样本放回就是bagging方法,采样时样本不放回就是pasting方法。下图就是一个pasting/bagging训练集采样和训练。
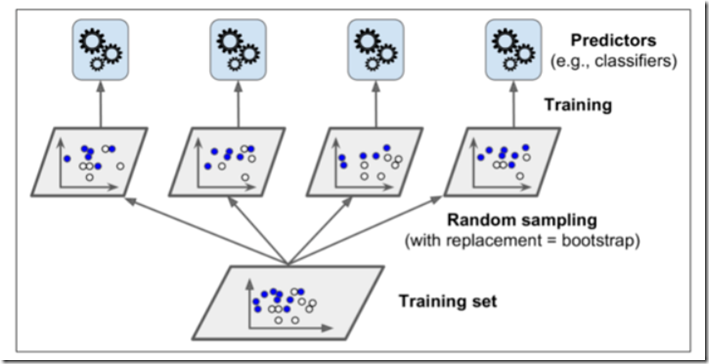
当训练完成后,我们的集成函数一般就采用统计的方法即可。显然,我们可以得出这样的结论,就是每个预测器单独的偏差都高于在原始训练集上的偏差,但是通过聚合集成,我们将会降低偏差与方差,得出更精准的答案。决策树一般采用上述方法进行训练。当然,随机森林也可以采用上述方法。
sklearn中有相关bagging与pasting的工具包,这里不再做赘述,请自行查阅相关文档。提示:使用BaggingClassifier类进行调用。
- Boosting方法:是指几个弱学习器合成一个强学习器的任意的集成方式。目前最流行的方法就是AdaBoost(自适应提升法)和梯度提升法。
Adaboost方法,思想就是更多地关注前序拟合不足地训练实例。从而使得新地预测器不断地越来越专注于难缠的问题。可以发现,该方法是一种存在时序关系的方法,我们必须要得到前者地训练的情况,然后对数据中对前者状态的分类器拟合不好的数据再次进行训练,然后循环往复。故此,可以得出,这个方法不能并行计算,在拓展方面,不如bagging、boosting。
相关推导,请看Scorpio.Lu博主的文章:https://www.cnblogs.com/ScorpioLu/p/8295990.html
梯度提升法:该方法是逐步在集成中添加预测器,每个都对其前序做出改正,让新的预测器对前一个的预测器的残差进行拟合。具体的推导,请见刘建平Pinard博主的文章:https://www.cnblogs.com/pinard/p/6140514.html
- Stacking方法:训练一个模型执行聚合集成所有预测器的预测,然后以预测器的预测作为输入再进行最后的预测。训练混合器的常用方式就是使用留存集。首先,将训练集分为两个子集,第一个子集训练第一层的预测器。然后,用第一层的预测器在第二个子集上进行预测。然后将在第二个子集上预测的值作为输入特征,创建一个新的训练集,保留目标值。在新的训练集上训练混合器,让其学习根据第一层的预测来预测目标值。通过该方法,可以训练多种不同的混合器。
《机器学习实战(基于scikit-learn和TensorFlow)》第七章内容学习心得的更多相关文章
- 《机器学习实战(基于scikit-learn和TensorFlow)》第六章内容学习心得
本章讲决策树 决策树,一种多功能且强大的机器学习算法.它实现了分类和回归任务,甚至多输出任务. 决策树的组合就是随机森林. 本章的代码部分不做说明,具体请到我的GitHub上自行获取. 决策树的每个节 ...
- 《机器学习实战(基于scikit-learn和TensorFlow)》第五章内容学习心得
本章在讲支持向量机(Support Vector Machine). 支持向量机,一个功能强大的机器学习模型,能够执行线性或非线性数据的分类.回归甚至异常值检测的任务.它适用于中小型数据集的分类. 线 ...
- 分享《机器学习实战基于Scikit-Learn和TensorFlow》中英文PDF源代码+《深度学习之TensorFlow入门原理与进阶实战》PDF+源代码
下载:https://pan.baidu.com/s/1qKaDd9PSUUGbBQNB3tkDzw <机器学习实战:基于Scikit-Learn和TensorFlow>高清中文版PDF+ ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Vue实战狗尾草博客后台管理系统第七章
Vue实战狗尾草博客后台管理平台第七章 本章内容为借助模块化来阐述Vuex的进阶使用. 在复杂项目的架构中,对于数据的处理是一个非常头疼的问题.处理不当,不仅对维护增加相当的工作负担,也给开发增加巨大 ...
- 机器学习实战:基于Scikit-Learn和TensorFlow 读书笔记 第6章 决策树
数据挖掘作业,要实现决策树,现记录学习过程 win10系统,Python 3.7.0 构建一个决策树,在鸢尾花数据集上训练一个DecisionTreeClassifier: from sklearn. ...
- 机器学习实战:基于Scikit-Learn和TensorFlow 第5章 支持向量机 学习笔记(硬间隔)
数据挖掘作业,需要实现支持向量机进行分类,记录学习记录 环境:win10,Python 3.7.0 SVM的基本思想:在类别之间拟合可能的最宽的间距,也叫作最大间隔分类 书上提供的源代码绘制了两个图, ...
- 集成算法(chapter 7 - Hands on machine learning with scikit learn and tensorflow)
Voting classifier 多种分类器分别训练,然后分别对输入(新数据)预测/分类,各个分类器的结果视为投票,投出最终结果: 训练: 投票: 为什么三个臭皮匠顶一个诸葛亮.通过大数定律直观地解 ...
随机推荐
- python json模块小技巧
python的json模块通常用于与序列化数据,如 def get_user_info(user_id): res = {"user_id": 190013234,"ni ...
- 【转】css样式的书写顺序及原理——很重要!
记得刚开始学习前端的时候,每次写css样式都是用到什么就在样式表后添加什么,完全没有考虑到样式属性的书写顺序对网页加载代码的影响.后来逐渐才知道正确的样式顺序不仅易于查看,并且也属于css样式优化的一 ...
- SQL Server 基础:ADO.NET
序言 Connection 主要提供与数据库的连接功能 Command 用于返回数据.修改数据.运行存储过程以及发送或检索参数信息的数据库命令 CommandType 获取或设置Command对象要执 ...
- single-pass单遍聚类方法
一.通常关于文本聚类也都是针对已有的一堆历史数据进行聚类,比如常用的方法有kmeans,dbscan等.如果有个需求需要针对流式文本进行聚类(即来一条聚一条),那么这些方法都不太适用了,当然也有很多其 ...
- JS 小脚本汇聚
根据文件length展示文件大小 if (bytes === 0) return '0 B'; var k = 1024, sizes = ['B', 'KB', 'MB', 'GB', 'TB', ...
- log4j.properties log4j.xml 路径问题
- Linux命令(用户管理、组和时间管理)
用户管理 Linux系统是一个多用用户的系统 用户分为三类: 超级用户(root)用户的id是0 伪用户 用户的id是1----499,虽然存在,但不能被登录 ...
- SPOJ AMR12B 720
这个题应该是个优先队列的模版题 当时比赛的时候没时间做先贴一下大神的代码好好学习学习 B - Gandalf vs the Balrog Time Limit:2000MS Memory Li ...
- selenium 右侧滚动条操作
对于web上有右侧滚动条的操作 可用使用JS语句执行 拖到底部 js = "var q=document.documentElement.scrollTop=10000"brows ...
- centos7 防火墙开启 (重点)
如果在自己服务器上想开启远端访问功能,需要开启防火墙 1.通过systemctl status firewalld查看firewalld状态,发现当前是dead状态,即防火墙未开启. 2.通过syst ...