如何利用python爬虫爬取爱奇艺VIP电影?
环境:windows python3.7
思路:
1、先选取你要爬取的电影
2、用vip解析工具解析,获取地址
3、写好脚本,下载片断
4、将片断利用电脑合成
需要的python模块:
##第一个模块不要安装,第二个模块需要安装
1、from multiprocessing import Pool
2、import requests
##模块安装方法
用windows命令行终端
pip install requests
一、先选取你要爬的电影,本例随便找了个VIP电影,复制地址
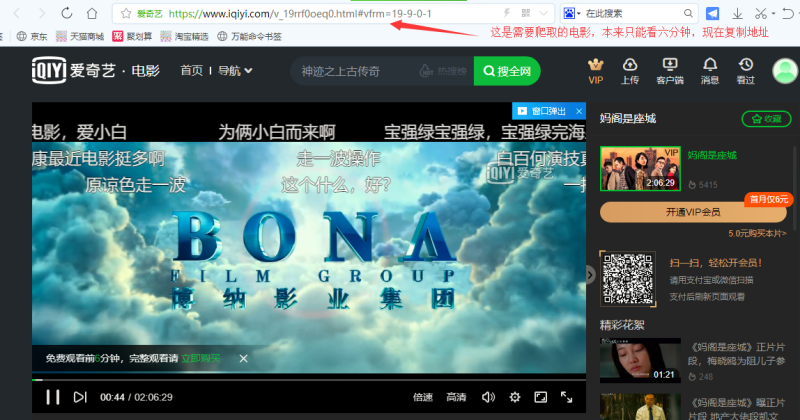
二、用vip解析工具解析,获取地址
(一)进行上网搜索,点击VIP解析
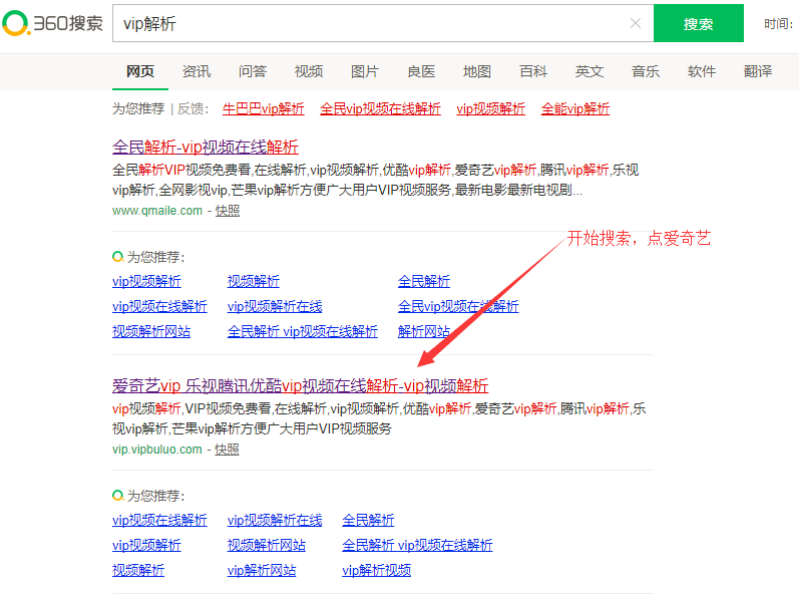
(二)、粘贴电影地址,点击播放

(三)、按下F12或者右击点检查,进入开发者工具界面,点击网络,复制地址
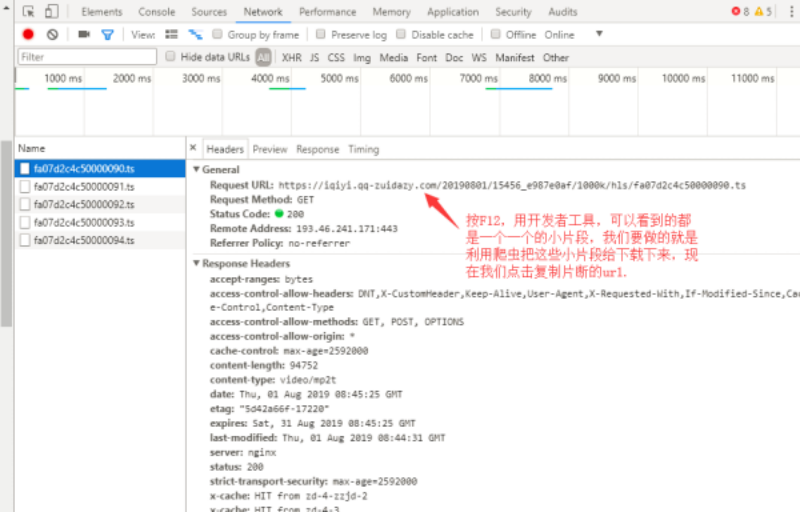
三、写好脚本,利用爬虫下载片断
##描述:该脚本目前适合下载爱奇艺,腾迅视频VIP视频
##作者:小刘
##电话:有事请写评论
##注意:只适全python爬虫的学习者,不适合专门去看电影的爱好者
##导入的两个模块,其中requests模块需要自行下载
from multiprocessing import Pool
import requests
##定义一个涵数
def demo(i):
##定义了一个url,后面%3d就是截取后面三位给他加0,以防止i的参数是1的时候参数对不上号,所以是1的时候就变成了001
url="https://vip.okokbo.com/20180114/ArVcZXQd/1000kb/hls/phJ51837151%03d.ts"%i
##定义了请求头信息
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36"}
##构建自定义请求对象
req=requests.get(url,headers=headers)
##将文件保存在当前目录的mp4文件中,名字以url后十位数起名
with open('./mp4/ {}'.format(url[-10:]), 'wb') as f:
f.write(req.content) ##程序代码的入口
if __name__=='__main__':
##定义一个进程池,可以同时执行二十个任务,不然一个一个下载太慢
pool = Pool(20)
##执行任务的代码
for i in range(100):
pool.apply_async(demo, (i,)) pool.close()
pool.join()
四、将片断利用电脑合成
(一)、复制电影存放的路径

(二)、用进入windows命令行模式,粘贴地址
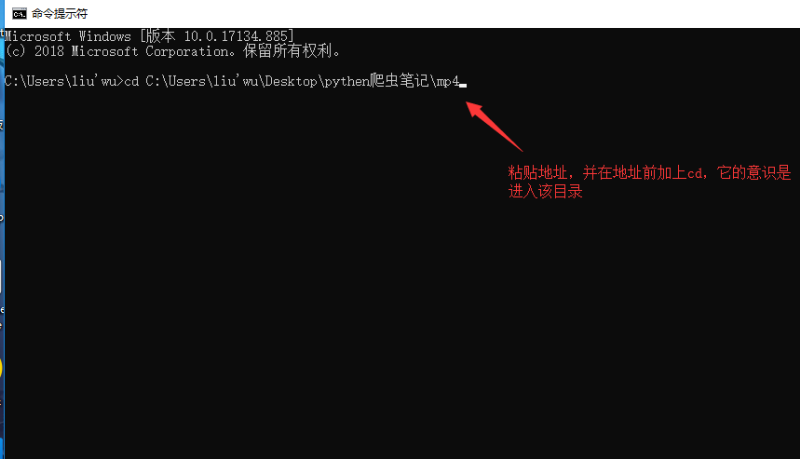
(三)、复制该目录下所有以*.ts结尾的文件,复制成一个文件

(四)、进行合并
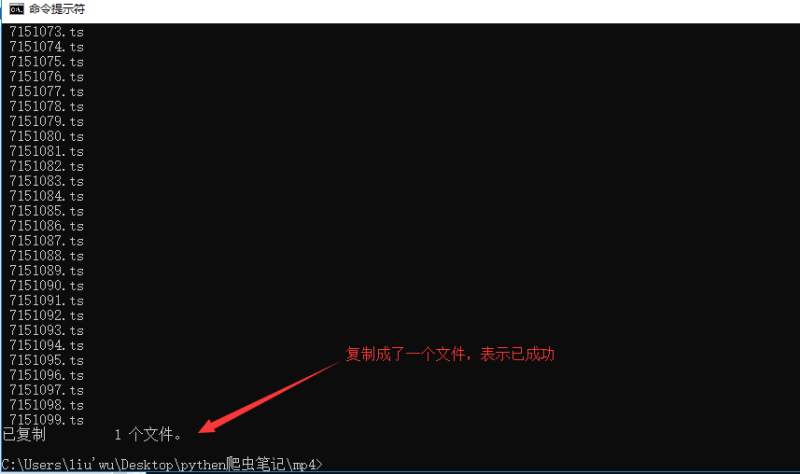
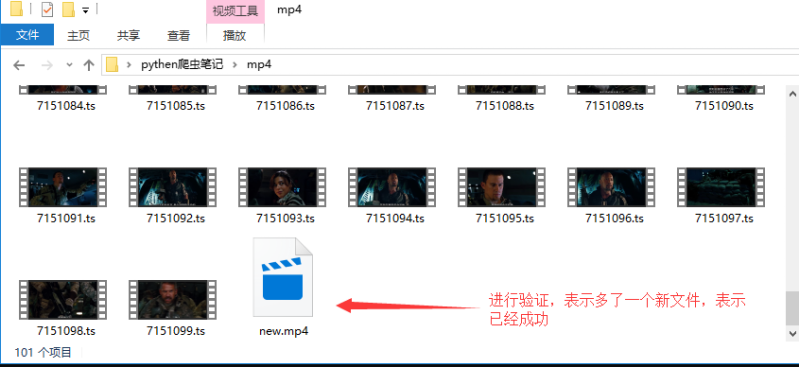
(五)、进行验证
(
五、有疑问请留言
如何利用python爬虫爬取爱奇艺VIP电影?的更多相关文章
- Python爬虫实战案例:爬取爱奇艺VIP视频
一.实战背景 爱奇艺的VIP视频只有会员能看,普通用户只能看前6分钟.比如加勒比海盗5的URL:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1 ...
- 使用selenium 多线程爬取爱奇艺电影信息
使用selenium 多线程爬取爱奇艺电影信息 转载请注明出处. 爬取目标:每个电影的评分.名称.时长.主演.和类型 爬取思路: 源文件:(有注释) from selenium import webd ...
- Python 爬虫实例(5)—— 爬取爱奇艺视频电视剧的链接(2017-06-30 10:37)
1. 我们找到 爱奇艺电视剧的链接地址 http://list.iqiyi.com/www/2/-------------11-1-1-iqiyi--.html 我们点击翻页发现爱奇艺的链接是这样的 ...
- Python爬取爱奇艺资源
像iqiyi这种视频网站,现在下载视频都需要下载相应的客户端.那么如何不用下载客户端,直接下载非vip视频? 选择你想要爬取的内容 该安装的程序以及运行环境都配置好 下面这段代码就是我在爱奇艺里搜素“ ...
- Python爬虫爬取BT之家找电影资源
一.写在前面 最近看新闻说圣城家园(SCG)倒了,之前BT天堂倒了,暴风影音也不行了,可以说看个电影越来越费力,国内大厂如企鹅和爱奇艺最近也出现一些幺蛾子,虽然目前版权意识虽然越来越强,但是很多资源在 ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- 利用Python爬虫爬取指定天猫店铺全店商品信息
本编博客是关于爬取天猫店铺中指定店铺的所有商品基础信息的爬虫,爬虫运行只需要输入相应店铺的域名名称即可,信息将以csv表格的形式保存,可以单店爬取也可以增加一个循环进行同时爬取. 源码展示 首先还是完 ...
- Python爬取爱奇艺【老子传奇】评论数据
# -*- coding: utf-8 -*- import requests import os import csv import time import random base_url = 'h ...
- 爬取爱奇艺电视剧url
----因为需要顺序,所有就用串行了---- import requests from requests.exceptions import RequestException import re im ...
随机推荐
- 如何写出好的PRD(产品需求文档)(转)
作者:Cherry,2007年进入腾讯公司,一直从事互联网广告产品管理工作,目前在SNG/效果广告平台部从事效果广告的产品运营工作. PRD(Product Requirement Document, ...
- csp-s模拟80(b)
头一次中午考试,上来一看三个题目以为是三个板子,但一看数据范围就不对劲. T1: 考场上的想法是:找出循环节,对于数组一头一尾的不在循环节中的,维护出以某数结尾/开头的上升序列,对于中间的循环部分只取 ...
- Qt事件机制浅析
Qt事件机制 Qt程序是事件驱动的, 程序的每个动作都是由幕后某个事件所触发.. Qt事件的发生和处理成为程序运行的主线,存在于程序整个生命周期. Qt事件的类型很多, 常见的qt的事件如下: 键盘事 ...
- bootstrp的datetimepicker插件获取选定日期
碰到一个日期选择,并将日期存储到数据库的需求,需要利用bootstrp的datetimepicker插件获取选定日期,并将其转换为指定字符窜,简单记录下实现的过程. 1. datetimepicker ...
- 图及其衍生算法(Graphs and graph algorithms)
1. 图的相关概念 树是一种特殊的图,相比树,图更能用来表示现实世界中的的实体,如路线图,网络节点图,课程体系图等,一旦能用图来描述实体,能模拟和解决一些非常复杂的任务.图的相关概念和词汇如下: 顶点 ...
- 手把手教你用蒲公英获取udid
如果需要获取udid,但是拥有手机的测试用户身边没有mac电脑和xcode环境, 今天就分享一个快捷的在线获得udid的方法 利用蒲公英网站的获取udid功能 手机浏览器访问 http://www.p ...
- 升级到Android Studio3.x遇到的问题及解决方案
升级到Android Studio3.x遇到的问题及解决方案 转 https://www.2cto.com/kf/201711/695736.html 升级到Android Studio3.0遇到的问 ...
- selenium 学习中遇到的问题汇总
1.使用document.getByClassName时无click事件,然后就不知道怎么办了,也不太懂前端,与开发大哥确认,div 中class实现展开和收起是通过隐藏和显示这种方式实现的,在编写时 ...
- django中iframe问题
因为在django中无法识别我们普通的url格式,比如使用<iframe src="articles.html"></iframe>,这种格式django无 ...
- Linux下四款常见远程工具比较
摘要:Linux远程可不像Windows下那么方便,主要是连接的速度.显示的画质不能令人满意(延迟.撕裂).本文只是说一下我用过的四款远程工具.Anydesk官网:https://anydesk.co ...