基于hanlp的es分词插件
摘要:elasticsearch是使用比较广泛的分布式搜索引擎,es提供了一个的单字分词工具,还有一个分词插件ik使用比较广泛,hanlp是一个自然语言处理包,能更好的根据上下文的语义,人名,地名,组织机构名等来切分词
Elasticsearch
默认分词

输出:
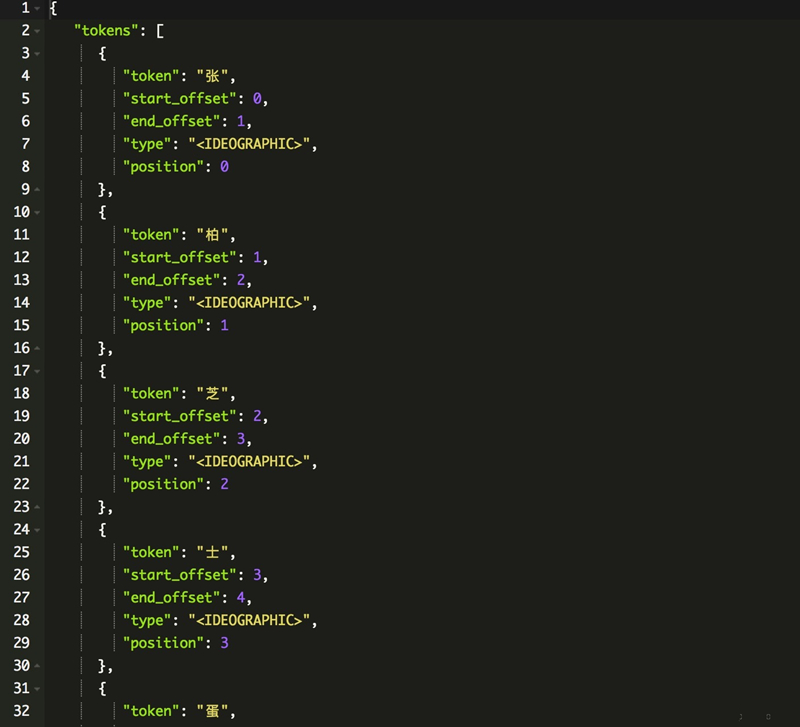
IK分词

输出:
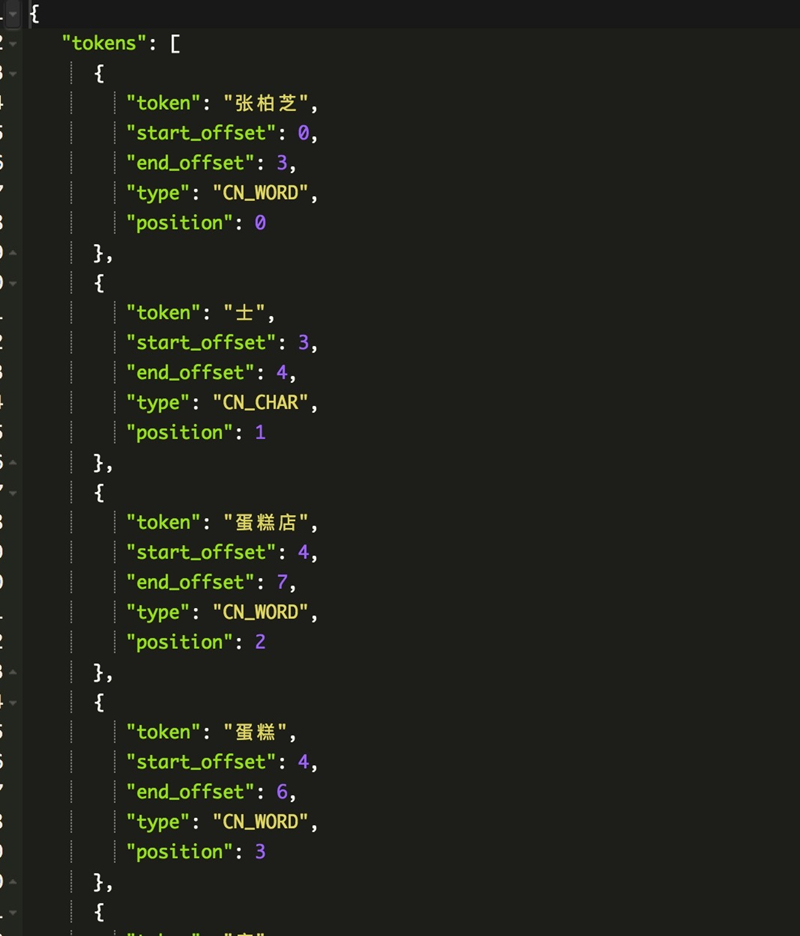
hanlp分词

输出:
ik分词没有根据句子的含义来分词,hanlp能根据语义正确的切分出词
安装步骤:
1、进入https://github.com/pengcong90/elasticsearch-analysis-hanlp,下载插件并解压到es的plugins目录下,修改analysis-hanlp目录下的hanlp.properties文件,修改root的属性,值为analysis-hanlp下的data
目录的地址
2、修改es config目录下的jvm.options文件,最后一行添加
-Djava.security.policy=../plugins/analysis-hanlp/plugin-security.policy
重启es
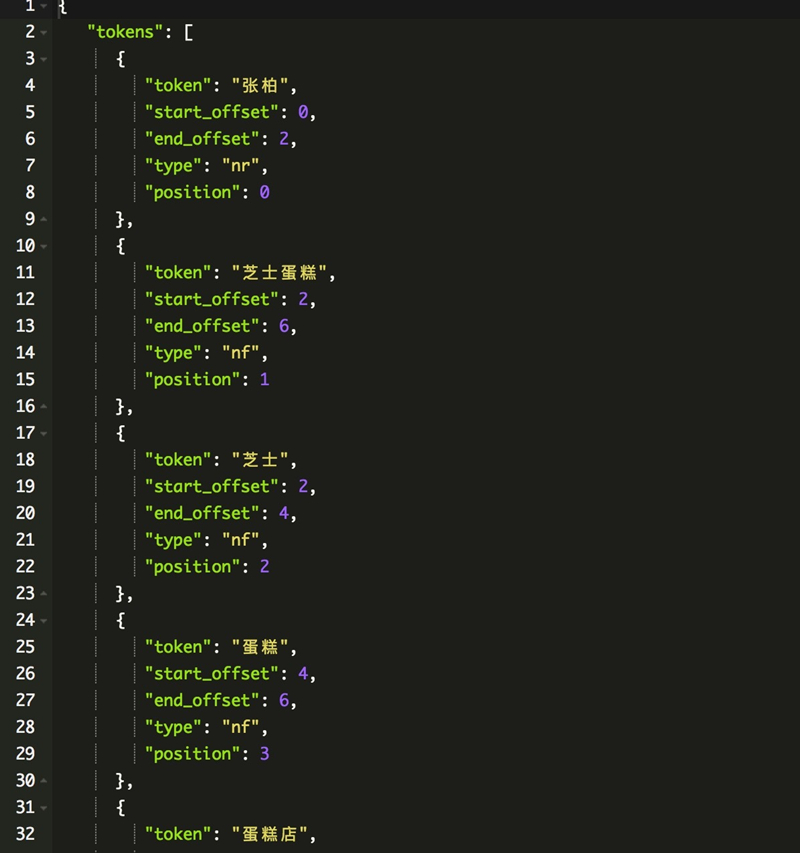
GET /_analyze?analyzer=hanlp-index&pretty=true
{
“text”:”张柏芝士蛋糕店”
}
测试是否安装成功
analyzer有hanlp-index(索引模式)和hanlp-smart(智能模式)
自定义词典
修改plugins/analysis-hanlp/data/dictionary/custom下的 我的词典.txt文件
格式遵从[单词] [词性A] [A的频次]
修改完后删除同目录下的CustomDictionary.txt.bin文件
重启es服务
基于hanlp的es分词插件的更多相关文章
- MapReduce实现与自定义词典文件基于hanLP的中文分词详解
前言: 文本分类任务的第1步,就是对语料进行分词.在单机模式下,可以选择python jieba分词,使用起来较方便.但是如果希望在Hadoop集群上通过mapreduce程序来进行分词,则hanLP ...
- ES之一:Elasticsearch6.4 windows安装 head插件ik分词插件安装
准备安装目标:1.Elasticsearch6.42.head插件3.ik分词插件 第一步:安装Elasticsearch6.4 下载方式:1.官网下载 https://www.elastic.co/ ...
- elasticsearch分词插件的安装
IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Luen ...
- Elasticsearch1.x 和Elasticsearch2.x 拼音分词插件lc-pinyin安装教程
Elasticsearch1.x 基于lc-pinyin和ik分词实现 中文.拼音.同义词搜索 https://blog.csdn.net/chennanymy/article/category/60 ...
- Elasticsearch如何安装中文分词插件ik
elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库. 安装步骤: 1.到github网站下载源代码,网站地址为:https://github.com/medcl/ ...
- Hive基于UDF进行文本分词
本文大纲 UDF 简介 Hive作为一个sql查询引擎,自带了一些基本的函数,比如count(计数),sum(求和),有时候这些基本函数满足不了我们的需求,这时候就要写hive hdf(user de ...
- Elasticsearch安装ik中文分词插件(四)
一.IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Lu ...
- elasticsearch之分词插件使用
elasticsearch对英文会拆成单个单词,对中文会拆分成单个字.下面来看看是不是这样. 首先测试一下英文: GET /blog/_analyze { "text": &quo ...
- ElasticSearch(三) ElasticSearch中文分词插件IK的安装
正因为Elasticsearch 内置的分词器对中文不友好,会把中文分成单个字来进行全文检索,所以我们需要借助中文分词插件来解决这个问题. 一.安装maven管理工具 Elasticsearch 要使 ...
随机推荐
- JSP大文件分片上传
核心原理: 该项目核心就是文件分块上传.前后端要高度配合,需要双方约定好一些数据,才能完成大文件分块,我们在项目中要重点解决的以下问题. * 如何分片: * 如何合成一个文件: * 中断了从哪个分片开 ...
- [Linux]awk RSTART,RLENGTH
转自 http://blog.sina.com.cn/s/blog_6d76c7e20102v381.html awk 是一门非常优秀的文本处理工具,甚至可以上升作为一门程序设计语言. 它处理文本的速 ...
- [dos]切换工作目录
dos切换目录: 最快速的方法: cd /d D:\your\heart 常规步骤: 1. d: 先必须切换盘符 2. cd D:\your\heart,其次切换工作目录
- JVM GC之垃圾收集器
简述 如果说收集算法时内存回收的方法论,那么垃圾收集器就是内存回收的具体实现.这里我们讨论的垃圾收集器是基于JKD1.7之后的Hotspot虚拟机,这个虚拟机包含的所有收集器如图: Serial 收集 ...
- tracert命令与tracert (IP地址)-d有什么区别?
他们的意义基本相同,都是路由追踪,返回从源到目标的路由情况:但tracert -d不解析各路由器的名称,只返回路由器的IP地址.而tracert 不仅返回各路由器的IP地址,而且返回其名称.简单来说, ...
- 焦虑的 BAT、不安的编程语言,揭秘程序员技术圈生存现状!
[程序人生编者按]在迭代不休的技术圈中,仅在过去的一个月期间,我们见证了有史以来第一张黑洞照片的诞生:经历了为让人义愤填膺的 996:思考了作为程序员的年龄之槛:膜拜了技术大神的成长历程:追逐了如编程 ...
- dubbo中的group与version的存在意义
公司每周五都要给线上系统发布一个版本,我将本周新开发的业务模块直接提交到svn的主干上(当然本机已经测试通过),在公司的测试环境部署运行正常,测试人员业务测试通过.但是在部署到准生产环境上后出现了意想 ...
- 使用聚集索引和非聚集索引对MySQL分页查询的优化
内容摘录来源:MSSQL123 ,lujun9972.github.io/blog/2018/03/13/如何编写bash-completion-script/ 一.先公布下结论: 1.如果分页排序字 ...
- webpack4 打包 library 遇到的坑
output: { publicPath: '/', path: path.join(__dirname, 'lib'), filename: 'chart.js', library: 'tchart ...
- mysql主从复制原理及步骤
原理: 1master开启bin-log功能,日志文件用于记录数据库的读写增删2需要开启3个线程,master IO线程,slave开启 IO线程 SQL线程,3Slave 通过IO线程连接maste ...