RabbitMQ多消费者顺序性消费消息实现
最近起了个项目消息中心,用来中转各个系统中产生的消息,用到的是RabbitMQ,由于UAT环境、生产环境每台消费者服务都是多台,有些消息要求按顺序消费,所以需要采取一定的措施保证消息的顺序消费,下面讲下我们不断优化的三种方法:
1、我们最开始考虑的比较简单,采用的direct交换机,指定特定消费者服务器监听队列,其他消费者服务器不监听。比如现在有C1、C2、C3三台消费者机器,我们决定C1消费消息,C2、C3不监听。我们在启动C1的时候,启动脚本中添加C1_IP,在代码中做处理,消费者服务器启动时,如果当前服务器IP就是启动脚本的C1_IP,那就会由这台C1来监听并消费消息。这种方式有个单点故障问题,如果C1服务器宕机,那么整个消息中心剩余两个节点都无法消费这个队列,导致队列消息堆积。如果有丰富的监控措施,那么监控到C1宕机后,可通过手动配置C2_IP(或者C3_IP)到启动脚本,重启C2服务器(C3服务器)消费消息。
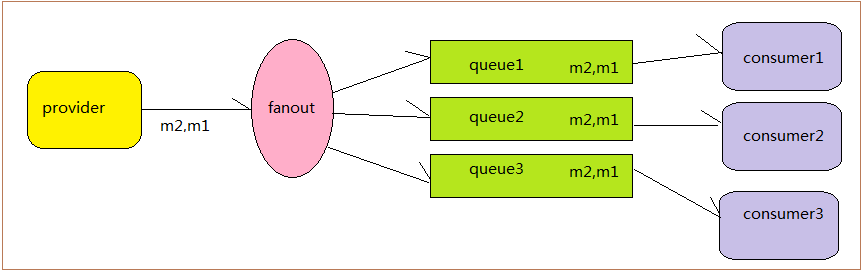
2、为了解决单点故障问题,我们采用了fanout交换机,每个消费者创建一个专用的queue,这样如果生产者产生两条有先后顺序的消息m1和m2(它们有公共的批次号batchNo和唯一的消息编号msgID),就会给每个queue都推送,如下图所示。同时消费者消费的时候需要配合数据库共同实施,消费者监听到消息后就入库(落库内容包括m1消息信息和消费者IP),根据msgID唯一索引性如果入库了则自己抛弃消息,消费m2时,需要从库表中取出m1的消费者IP是否是当前IP,如果不是则抛弃消息。但是这个方案有个缺点:如果consumer1消费了m1后挂掉了,m2只能等到consumer1正常后才能消费,无法转移到其他消费者进行消费,这样会对一些业务场景不友好(当然这个地方可以考虑死信交换机死信队列进行转移,只不过架构更复杂了)。
3.第三种方式跟第二种类似,采用fanout交换机,每个消费者创建一个专用的queue。但是没有借助数据库,而是通过访问rabbitMQ的API接口,获取这三个队列的所有消费者的IP放到list中,消费者监听到消息后,判断自己的ip是否是ip集合里面的最小值,如果是则消费,如果否则抛弃消息。一旦最小IP的消费者宕机后,则list种就会只剩下两个IP,后续的消息选定的消费者就会从这两个IP中选择最小IP消费。同理它也有第二种方案的缺点。
最后附上通过rabbitmq的api获取minIP的代码(入参consumerIps是初始size=0的list),如下:
private String findUsefulMinIP(List<String> consumerIps) {
String minIp = null;
SimpleClientHttpRequestFactory requestFactory = new SimpleClientHttpRequestFactory();
requestFactory.setConnectTimeout(20000);
try {
RestTemplate rest = new RestTemplateBuilder().basicAuthentication(username, password).build();
rest.setRequestFactory(requestFactory);
JSONArray result2 = rest.getForObject(moccMQApiUrl, JSONArray.class);
if(result2 != null && result2.size() > 0) {
log.info("===clear the ips===new query start===");
consumerIps.clear();
}
for(int m=0; m<result2.size(); m++) {
LinkedHashMap itmap = (LinkedHashMap) result2.get(m);
LinkedHashMap queueMap = (LinkedHashMap)itmap.get("queue");
if(!queueMap.values().stream().anyMatch(v -> v.toString().indexOf(moccQueue)>=0)) {
continue;
}
LinkedHashMap consumerMap = (LinkedHashMap)itmap.get("channel_details");
consumerIps.add((String)consumerMap.get("peer_host"));
}
log.info("===query from mq===consumerIps={}", consumerIps);
} catch (RestClientException e) {
log.error(e.getMessage(), e);
}
minIp = Collections.min(consumerIps);
return minIp;
}
RabbitMQ多消费者顺序性消费消息实现的更多相关文章
- 2.RABBITMQ 入门 - WINDOWS - 生产和消费消息 一个完整案例
关于安装和配置,见上一篇 1.RABBITMQ 入门 - WINDOWS - 获取,安装,配置 公司有需求,要求使用winform开发这个东西(消息中间件),另外还要求开发一个日志中间件,但是也是要求 ...
- rocketmq的以集群模式MessageModel.CLUSTERING实现消费者集群消费消息,实现负载均衡
package com.bfxy.rocketmq.model; import java.util.List; import org.apache.rocketmq.client.consumer.D ...
- Pulsar の 保证消息的顺序性、幂等性和可靠性
原文链接:Pulsar の 保证消息的顺序性.幂等性和可靠性 一.背景 前面两篇文章,已经介绍了关于Pulsar消费者的详细使用和自研的Pulsar组件. 接下来,将简单分析如何保证消息的顺序性.幂等 ...
- RabbitMQ保证消息的顺序性
当我们的系统中引入了MQ之后,不得不考虑的一个问题是如何保证消息的顺序性,这是一个至关重要的事情,如果顺序错乱了,就会导致数据的不一致. 比如:业务场景是这样的:我们需要根据mysql的b ...
- Kafka如何保证消息的顺序性
1. 问题 比如说我们建了一个 topic,有三个 partition.生产者在写的时候,其实可以指定一个 key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到 ...
- kafka如何保证消息得顺序性
1. 问题 比如说我们建了一个 topic,有三个 partition.生产者在写的时候,其实可以指定一个 key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到 ...
- RabbitMQ 消费消息
1, 创建一个 springboot 项目, 导入依赖(和生产者一致) 2, application.properties (基础配置和生产者一致, 消费者需要再额外配置一些) # rabbitmq ...
- MQ如何解决消息的顺序性
一.消息的顺序性 1.延迟队列:设置一个全局变量index,根据实际情况一次按照index++的逻辑一次给消息队列设置延迟时间段,可以是0.5s,甚至1s; 弊端:如果A,B,C..消息队列消费时间不 ...
- 分布式场景下Kafka消息顺序性的思考
如果业务中,对于kafka发送消息异步消费的场景,在业务上需要实现在消费时实现顺序消费, 利用kafka在partition内消息有序的特点,消息消费时的有序性. 1.在发送消息时,通过指定parti ...
随机推荐
- 优雅地创建未定义类PHP对象
在PHP中,如果没有事先准备好类,需要创建一个未定义类的对象,我们可以采用下面三种方式: new stdClass() new class{} (object)[] 首先是stdClass,这个类是一 ...
- PHP中比较数组的时候发生了什么?
首先还是从代码来看,我们通过比较运算符号来对两个数组进行比较: var_dump([1, 2] == [2, 1]); // false var_dump([1, 2, 3] > [3, 2, ...
- Java基础系列(2)- Java开发环境搭建
JDK下载与安装 安装JDK 1.百度搜素JDK8,找到下载地址 2.下载电脑对应的版本 3.双击安装JDK 4.记住安装的路径,可以自定义,默认路径如图 卸载JDK 删除Java安装目录 删除环境变 ...
- gin 源码阅读(1) - gin 与 net/http 的关系
gin 是目前 Go 里面使用最广泛的框架之一了,弄清楚 gin 框架的原理,有助于我们更好的使用 gin. 这个系列 gin 源码阅读会逐步讲明白 gin 的原理. gin 概览 想弄清楚 gin, ...
- vue 熟悉项目结构 创建第一个自己的组件
* vue开发环境搭建 * 项目入口文件 ./src/main.js // The Vue build version to load with the `import` command // (ru ...
- Kafka 性能篇:为何 Kafka 这么快?
『码哥』的 Redis 系列文章有一篇讲透了 Redis 的性能优化 --<Redis 核心篇:唯快不破的秘密>.深入地从 IO.线程.数据结构.编码等方面剖析了 Redis " ...
- P1791-[国家集训队]人员雇佣【最大权闭合图】
正题 题目链接:https://www.luogu.com.cn/problem/P1791 题目大意 有\(n\)个人,雇佣第\(i\)个需要\(A_i\)的费用,对于\(E_{i,j}\)表示如果 ...
- YbtOJ#643-机器决斗【贪心,李超树】
正题 题目链接:https://www.ybtoj.com.cn/problem/643 题目大意 \(n\)个机器人,第\(i\)个攻击力为\(A_i\),防御为\(D_i\). 然后你每次可以对一 ...
- Python3入门系列之-----循环语句(for/while)
前言 for循环在Python中是用的比较多的一种循环方法,小伙伴需要熟练掌握它的使用 本章节将为大家介绍 Python 循环语句的使用.Python 中的循环语句有 for 和 while for循 ...
- Fortran学习笔记:01 基本格式与变量声明
Fortran学习笔记目录 01 基本格式与变量声明 格式 固定格式(Fixed Format):Fortran77 程序需要满足一种特定的格式要求,具体形式参考教材 自由格式(Free Format ...