[BD] Flume
什么是Flume
- 采集日志,存在HDFS上
- 分布式、高可用、高可靠的海量日志采集、聚合和传输系统
- 支持在日志系统中定制各类数据发送方,用于收集数据
- 支持对数据进行简单处理,写到数据接收方
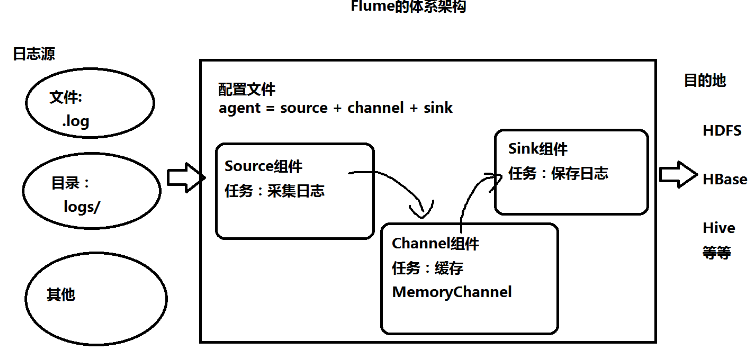
组件
- source:数据的来源
- avro:接收另一个flume的数据
- taildir:监控不断追加的日志文件
- channel:数据传输通道
- sink:数据落盘处
配置
- 配置文件


1 #bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
2 #定义agent名, source、channel、sink的名称
3 a4.sources = r1
4 a4.channels = c1
5 a4.sinks = k1
6
7 #具体定义source
8 a4.sources.r1.type = spooldir
9 a4.sources.r1.spoolDir = /root/training/logs
10
11 #具体定义channel
12 a4.channels.c1.type = memory
13 a4.channels.c1.capacity = 10000
14 a4.channels.c1.transactionCapacity = 100
15
16 #定义拦截器,为消息添加时间戳
17 a4.sources.r1.interceptors = i1
18 a4.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
19
20
21 #具体定义sink
22 a4.sinks.k1.type = hdfs
23 a4.sinks.k1.hdfs.path = hdfs://192.168.56.111:9000/flume/%Y%m%d
24 a4.sinks.k1.hdfs.filePrefix = events-
25 a4.sinks.k1.hdfs.fileType = DataStream
26
27 #不按照条数生成文件
28 a4.sinks.k1.hdfs.rollCount = 0
29 #HDFS上的文件达到128M时生成一个文件
30 a4.sinks.k1.hdfs.rollSize = 134217728
31 #HDFS上的文件达到60秒生成一个文件
32 a4.sinks.k1.hdfs.rollInterval = 60
33
34 #组装source、channel、sink
35 a4.sources.r1.channels = c1
36 a4.sinks.k1.channel = c1
命令
- 启动:bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
应用
- 采集网络传输信息
- node01安装flume,写配置文件,开启flume
- node02中telnet给node01发送信息
- 采集特定目录下新文件内容到HDFS
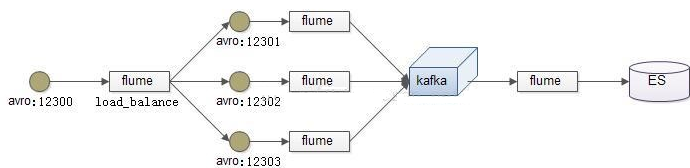
- 高可用(failover)
- agent1.sinkgroups.g1.processor.type = failover
- 停掉node02的agent,自动切换到node03上的agent
- 启动node02的agent,由于node02优先级高,自动切换回node02上的agent

- 负载均衡(load balancer)
- a1.sinkgroups.g1.processor.type = load_balance
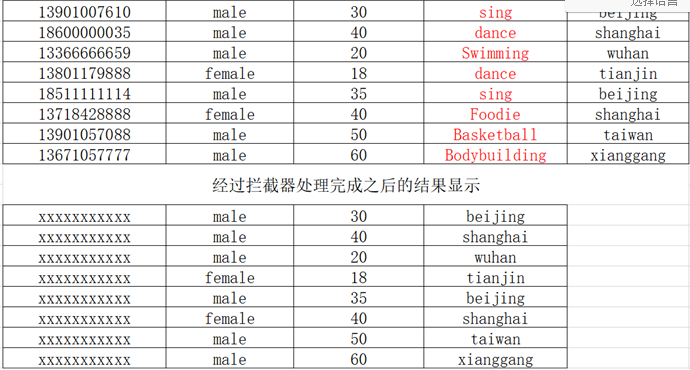
- 静态拦截器
- 将不同数据源的数据放在不同目录
- 自定义拦截器
- 数据采集后,将不需要的数据过滤掉,并将指定的第一个字段进行加密,再存到hdfs上
- a1.sources.r1.interceptors.i1.type =com.kkb.flume.interceptor.MyInterceptor$MyBuilder
- a1.sources.r1.interceptors.i1.encrypted_field_index=0
- a1.sources.r1.interceptors.i1.out_index=3



- 自定义source
- MySql数据采集到HDFS
参考
官方文档
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
快速入门
https://www.iteye.com/blog/manzhizhen-2298394
flume插件
https://www.cnblogs.com/mingfengshan/p/6853777.html
flume监控spoolDir日志到HDFS
https://blog.csdn.net/qq_20641565/article/details/52807776
avro sink 扩展
https://segmentfault.com/q/1010000023286882
source:avro
https://zhidao.baidu.com/question/373286862006114404.html
source:taildir
http://lxw1234.com/archives/2015/10/524.htm
[BD] Flume的更多相关文章
- flume的使用
1.flume的安装和配置 1.1 配置java_home,修改/opt/cdh/flume-1.5.0-cdh5.3.6/conf/flume-env.sh文件
- Flume1 初识Flume和虚拟机搭建Flume环境
前言: 工作中需要同步日志到hdfs,以前是找运维用rsync做同步,现在一般是用flume同步数据到hdfs.以前为了工作简单看个flume的一些东西,今天下午有时间自己利用虚拟机搭建了 ...
- Flume(4)实用环境搭建:source(spooldir)+channel(file)+sink(hdfs)方式
一.概述: 在实际的生产环境中,一般都会遇到将web服务器比如tomcat.Apache等中产生的日志倒入到HDFS中供分析使用的需求.这里的配置方式就是实现上述需求. 二.配置文件: #agent1 ...
- Flume(3)source组件之NetcatSource使用介绍
一.概述: 本节首先提供一个基于netcat的source+channel(memory)+sink(logger)的数据传输过程.然后剖析一下NetcatSource中的代码执行逻辑. 二.flum ...
- Flume(2)组件概述与列表
上一节搭建了flume的简单运行环境,并提供了一个基于netcat的演示.这一节继续对flume的整个流程进行进一步的说明. 一.flume的基本架构图: 下面这个图基本说明了flume的作用,以及f ...
- Flume(1)使用入门
一.概述: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统. 当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- flume使用示例
flume的特点: flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受 ...
随机推荐
- Java进阶专题(二十八) Service Mesh初体验
前言 ⽬前,微服务的架构⽅式在企业中得到了极⼤的发展,主要原因是其解决了传统的单体架构中存在的问题.当单体架构拆分成微服务架构就可以⾼枕⽆忧了吗? 显然不是的.微服务架构体系中同样也存在很多的挑战 ...
- Logtash 配置文件解析-转载
转载地址:https://dongbo0737.github.io/2017/06/13/logstash-config/ Logtash 配置文件解析 logstash 一个ELK架构中,专门用来进 ...
- HTML5本地存储 localStorage操作使用详解
1.html5几种存储形式 本地存储(localStorage && sessionStorage) 离线缓存(application cache) indexedDB 和 webSQ ...
- 开源服务器设计总计(plain framework2020年总计)
2020年注定会被历史铭记,世界遭受着一场前所未有的灾难,这种灾难到现在还在持续.还记得19年末的时候,那时候听到一点点消息,哪里想得到年关难过,灾难来的让人猝不及防.由于疫情防控,2020年感觉转瞬 ...
- Flowable与springBoot项目整合及出现的问题
Flowable与springBoot项目整合及出现的问题 单纯地将Flowable和springBoot整合,使用mysql作为数据库,整合中踩了两个坑,见文末. 在pom中添加依赖 <?xm ...
- starctf_2019_babyshell
starctf_2019_babyshell 有时shellcode受限,最好的方法一般就是勉强的凑出sys read系统调用来注入shellcode主体. 我们拿starctf_2019_babys ...
- 实战项目部署应用到kubernetes流程(jenkins+docker+k8s)
说明 通过jenkins构建java应用程序发布到k8s集群中 本文已一个大数据的java项目来演示构建部署过程 支持发布和回滚 支持一套模板应用不同项目 k8s基础准备 创建项目名称空间 [root ...
- 集群,lvs负载均衡的四种工作模式
集群 集群的三种分类以及用途 负载均衡: 分配流量(调度器),提升速度 高可用: 关键性业务 高性能: 开发算法,天气预报,国家安全 负载均衡的集群 lvs(适用于大规模) haproxy(适用于中型 ...
- 1-web 服务器 框架。
1.静态网页与动态网页 1.静态网页:无法与服务器进行交互的网页. 2.动态网页:能够与服务器进行交互的网页. 2.web与服务器 1.web:网页(HTML,CSS,JS) 2.服务器:能够给用户提 ...
- 【golang】golang中结构体的初始化方法(new方法)
准备工作: 定义结构体:Student import ( "fmt" "reflect") type Student struct { StudentId st ...