再看Lambda架构
最*看了一本《大数据系统构建》的书,发现之前对于Lambda架构的理解还是不够深入和清晰。
之前对Lambda架构的理解
Azure文档上有一张Lambda架构的图,
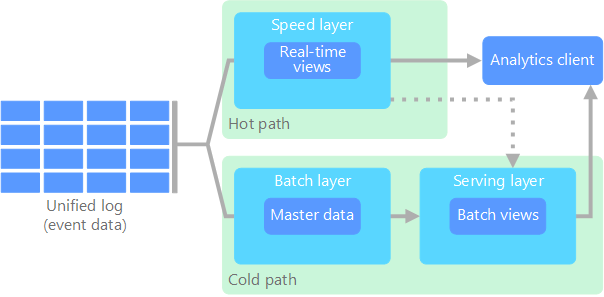
同时也配有对Lambda架构最基本的理解:
批处理层(冷路径)以原始形式存储所有传入数据,对数据进行批处理。 该处理的结果作为 批处理视图 存储。
速度层(热路径)可实时分析数据。 设计此层是为了降低延迟,但代价是准确性也会降低。
当初看Lambda架构的时候,更在意的点其实是将数据处理分成批处理层 和速度层 两个部分,批处理层 在处理大批量数据的时候是有性能优势的,而速度层 虽然在性能和准确性上会差一些,但是在时效性上有着无可取代的地位。
当初看的时候,会没有那么关注以原始形式存储 这几个关键字,虽然有概念,但是却没有那么在意。
现在对Lambda架构的理解
以原始形式存储
但是最*看完《大数据系统构建》之后,发现以原始形式存储 才是精华。
以原始形式存储 给我们带来了很好的容错能力,一个最简单的例子就是,如果是一个计算页面浏览量的分析任务,如果我们采用全增量架构 ,也就是在数据库中维护一个count来记录页面的访问量,那么一旦某一个版本,计算函数出错了,把一个页面计算了两遍,那么这些数据就会一直错误下去了。而如果我们只是存下了原始形式 的数据,那么只需要在改正bug后全量计算一遍,就可以将错误恢复了。
这个能力其实在Lambda架构中很重要,其实将数据处理分成批处理层 和速度层 两个部分,并不主要是因为他们处理速度的快慢,而是因为我们首先在思想上将大数据处理分成两种处理,一种是我可以牺牲时效性,但是要保证准确性、容错能力、算法的简洁性的批处理层 。一种是我如果还要时效性,那么就引入一个算法更复杂、准确性稍差的速度层 ,但这一切的前提是,我可以用批处理层 兜底,即使这一刻的数据是不太准确的,甚至由于代码的bug导致了数据是错误的,也没有太大影响,因为最终,都会通过批处理层 重新计算。
在洞悉了这一设计理念之后,书中的三层划分其实就很自然了,我们可以再引入一个增量批处理层 也就是将批处理再划分成2部分,一个是全量重新计算层 ,一个是增量计算层 ,增量计算的算法会同速度层 差不多,不过由于是批计算,所以吞吐量会更高一些,这一层才是当初我所理解的批处理层 。
联系Event Sourcing
再提一点,其实Event Sourcing也有以原始形式存储 的优势所在,如果业务系统采用Event Sourcing的方式来构建,那么一旦某个版本的bug导致了快照出现了问题,可以很轻易地通过无bug的新版本来更正快照。
同时Event Sourcing也为后续的Lambda架构提供了很充分的支持。
做数据接入避免不了选择接入的方式:全量接入、增量接入、WAL接入。它们又分别有着自己的优缺点:
全量接入:
每天使用select * from tableXXX来获取tableXXX的数据
优点:
- 可以捕获所有的数据变化,包括硬删除。
- 对业务侧的表设计没有任何要求。
缺点:
- 对业务侧的造成的压力大。
- 存储压力大,重复的数据多(这一点可以可以通过一些处理手段,将数据处理成增量形式)。
- 如果一条数据一天内变更了多次,只能获取到每天的最新状态。
所以全量接入只能考虑全表数据量比较小的一些表。
增量接入:
通过修改时间的字段来确定每天需要接入的数据。比如select * from tableXXX where date_format(optime,'%Y%m%d')='20000101'
优点:
- 对业务侧造成的压力小,只需要获取部分数据。
缺点:
- 业务侧硬删除的数据无法感知到,要求业务侧只进行软删除。
- 如果一条数据一天内变更了多次,只能获取到每天的最新状态。
- 要求业务侧记录数据变更的时间字段
WAL接入
通过同步Write-Ahead Log,并通过这些log来接入数据。比如MySQL的所有操作都会先写binlog,再更新数据,我们只需要订阅binlog,就可以还原数据了。
优点:
- 不像前两种接入,WAL接入能捕获所有的更新。
- 数据延迟小,可以达到秒级延
缺点:
- 技术门槛较高,需要理解binlog、考虑数据传输过程中端到端的一致性
- 业务表中需要有主键
Event Sourcing + 增量接入 + Lambda 架构
看完这几种接入方式,如果这个时候我们将增量接入配合上Event Sourcing。会发现这个方案真香:
针对缺点业务侧硬删除的数据无法感知到,要求业务侧只进行软删除。 ,由于Event Sourcing中,删除也是以事件的形式存储的,所以完美契合了。
针对缺点如果一条数据一天内变更了多次,只能获取到每天的最新状态。 ,由于所有的变更也都是以时间的形式存储的,所以没有变更会丢失。
同时,Lambda架构中想要的以原始形式存储的前提也被一并满足了。
联系推荐系统
推荐系统中,最典型的架构就是Netflix的离线、*线、在线三层架构。
其实其中的思想是类似的,用离线数据进行离线模型训练,用增量学*进行*线层处理,在线层 则处理一些预测、排序等实时性要求高的操作。
再看Lambda架构的更多相关文章
- web前端体系-了解前端,深入前端,架构前端,再看前端。大体系-知识-小细节
1.了解前端,深入前端,架构前端,再看前端.大体系-知识-小细节 个人认为:前端发展最终的导向是前端工程化,智能化,模块化,组件化,层次化. 2.面试第一关:理论知识. 2-1.http标准 2-2. ...
- Lambda架构
转载:https://blog.csdn.net/brucesea/article/details/45937875 1.Lambda架构背景介绍 Lambda架构是由Storm的作者Nathan M ...
- lambda架构简介
1.Lambda架构背景介绍 Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理框架.Marz在Twitter工作期间开发了著名的实时大数据处理框架Storm,Lamb ...
- 大数据处理中的Lambda架构和Kappa架构
首先我们来看一个典型的互联网大数据平台的架构,如下图所示: 在这张架构图中,大数据平台里面向用户的在线业务处理组件用褐色标示出来,这部分是属于互联网在线应用的部分,其他蓝色的部分属于大数据相关组件,使 ...
- 深入理解大数据架构之——Lambda架构
目录 传统系统的问题 Lambda架构简介 Lambda架构关键特性 数据系统的本质 Lambda的三层架构 Lambda架构组件选型 总结 原文链接:https://jiang-hao.com/ar ...
- 聊聊Lambda架构
定义 在数据分析场景中,我们可能会遇到这样的问题.例如,我们要做一个推荐系统,如果我们用批处理任务去做,一天或者一小时的推荐频次明显延迟太大.如果用流处理任务,虽然延迟的问题解决了,然而只用实时数据而 ...
- [转帖]万字详解Oracle架构、原理、进程,学会世间再无复杂架构
万字详解Oracle架构.原理.进程,学会世间再无复杂架构 http://www.itpub.net/2019/04/24/1694/ 里面的图特别好 数据和云 2019-04-24 09:11:59 ...
- Others-大数据平台Lambda架构浅析(全量计算+增量计算)
大数据平台Lambda架构浅析(全量计算+增量计算) 2016年12月23日 22:50:53 scuter_victor 阅读数:1642 标签: spark大数据lambda 更多 个人分类: 造 ...
- 带有Apache Spark的Lambda架构
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 目标 市场上的许多玩家已经建立了成功的MapReduce工作流程来每天处理以TB计的历史数据.但是谁愿意等待24小时才能获得最新的分析结果? ...
随机推荐
- 二进制格式安装MySQL
二进制格式安装MySQL 下载二进制格式的mysql软件包 下载二进制格式的 mysql 软件包 [root@localhost ~]# cd /usr/src/ [root@localhost sr ...
- mysql有关配置
mysql有关配置 mysql安装 mysql安装方式有三种 源代码:编译安装 二进制格式的程序包:展开至特定路径,并经过简单配置后即可使用 程序包管理器管理的程序包: rpm:有两种 OS Vend ...
- 3.13eval函数
eval 函数 eval() 函数十分强大 -- 将字符串 当成 有效的表达式 来求值 并 返回计算结果 ```python 基本的数学计算 In [1]: eval("1 + 1" ...
- 7.7-9 chage、chpasswd、su
7.7 chage:修改用户密码有效期 chage命令用于查看或修改用户密码的有效期,有些参数和passwd的功能相同. -d 设置上一次密码更改的日期 -E 账号过期的日期.日期格式 ...
- Relay外部库使用
Relay外部库使用 本文介绍如何将cuDNN或cuBLAS等外部库与Relay一起使用. Relay内部使用TVM生成目标特定的代码.例如,使用cuda后端,TVM为用户提供的网络中的所有层生成cu ...
- 大尺寸卫星图像目标检测:yoloT
大尺寸卫星图像目标检测:yoloT 1. 前言 YOLT论文全称「You Only Look Twice: Rapid Multi-Scale Object Detection In Satellit ...
- Java 将PPT幻灯片转为HTML
本文以Java程序代码为例展示如何通过格式转换的方式将PPT幻灯片文档转为HTML文件.这里的PPT幻灯片可以是.ppt/.pptx/.pps/.ppsx/.potx等格式. 代码实现思路:[加载PP ...
- vscode使用版本控制git commit unstaged时提示对话框的设置
使用 vscode 版本控制提交代码时,如果有 unstaged file,会有一个弹出框: 选择 always 或者 never ,这个框下次就不再弹出了. 如果你想让他再次出现,请去setting ...
- 用Java如何设计一个阻塞队列,然后说说ArrayBlockingQueue和LinkedBlockingQueue
前言 用Java如何设计一个阻塞队列,这个问题是在面滴滴的时候被问到的.当时确实没回答好,只是说了用个List,然后消费者再用个死循环一直去监控list的是否有值,有值的话就处理List里面的内容.回 ...
- 【NX二次开发】体素特征相关函数(块、柱、锥、球)
NX Open允许用户创建和查询所有基本体素特征,通过API函数建立基本体素特征返回的是相应的特征标识,如果需要可以通过函数UG_MODL_ask_feat_body()获得特征对应的实体对象标识.基 ...