RDS备份到OSS增量+全量
一.前言
阿里云的RDS备份是占用使用量的,你购买200G那备份使用量是100G左右,导致备份一般也就存半个月,2个全备份。

那半个月后之前的也就删除了,如果要持续保留更久将花费不少的金钱。所以这里用脚本获取下载到本地然后推送到OSS里,同比来说OSS便宜很多的,也会保险一些。当然本地也可以留一份,需要自行修改下脚本。
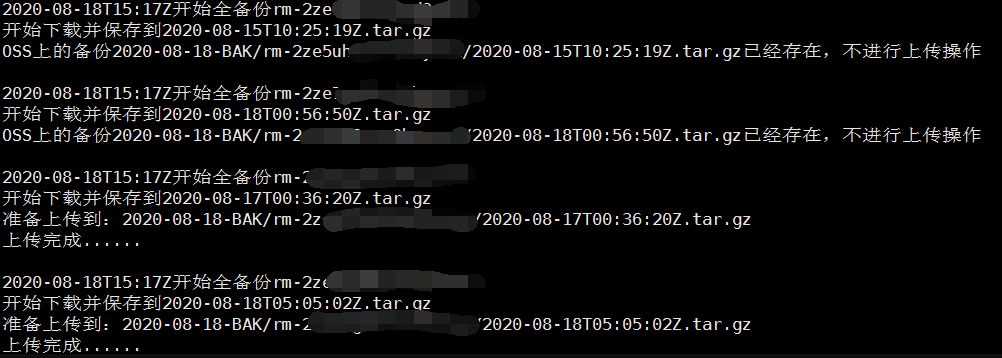
脚本功能:
1.根据配置,对RDS可以选择全量备份或者增量备份
代码地址:
https://gitee.com/rxys/script-tools/blob/master/python/rds_backups_oss.py
脚本要求:
1.需要使用Python3,默认用/usr/bin/python3
注意事项:
1.RDS会先下载到本地,若本地磁盘过于小会造成下载失败
2.RDS下载的备份是已经定时备份完的数据,不会对当前RDS造成影响
二.使用前准备
1.下载脚本
wget https://gitee.com/rxys/script-tools/raw/master/python/rds_backups_oss.py
chmod +x rds_backups_oss.py
2.修改脚本配置,将脚本如下部分进行对应修改,备份目录不存在会自动建立
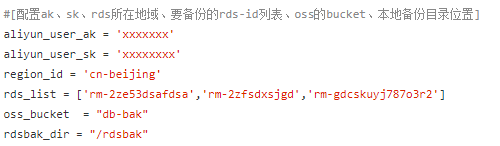
3.安装依赖包
yum -y install python-devel
pip3 install oss2 aliyun-python-sdk-core aliyun-python-sdk-rds
4.进行全量备份测试
./rds_backups_oss.py allbak
5.进行增量备份测试
./rds_backups_oss.py binlog
6.添加定时任务
crontab -e
1 23 * * 6 /usr/bin/python3 rds_backups_oss.py allbak
1 * * * * /usr/bin/python3 rds_backups_oss.py binlog
三.一些自定义配置
1.如果备份实例过多下载很久,可能过几个小时就会导致脚本进程停掉,可以将脚本多复制几份,然后每个脚本完成一部分的rds备份任务
2.如果全备份是8天或者更久才备份一次,需要修改脚本中的days=7,修改成days=x,改成间隔天数
RDS备份到OSS增量+全量的更多相关文章
- 利用ant脚本 自动构建svn增量/全量 系统程序升级包【转】
引文:我们公司是做自己使用产品,迭代更新周期短,每次都花费较多时间和精力打包做增量更新,发现了一篇文章用于 自动构建svn增量/全量 系统程序升级包,收藏之,希望可以通过学习,更加简化我们的工作. 文 ...
- Mysql备份系列(3)--innobackupex备份mysql大数据(全量+增量)操作记录
在日常的linux运维工作中,大数据量备份与还原,始终是个难点.关于mysql的备份和恢复,比较传统的是用mysqldump工具,今天这里推荐另一个备份工具innobackupex.innobacku ...
- innobackupex在线备份及恢复(全量和增量)
Xtrabackup是由percona开发的一个开源软件,它是innodb热备工具ibbackup(收费的商业软件)的一个开源替代品.Xtrabackup由个部分组成:xtrabackup和innob ...
- HBase备份还原OpenTSDB数据之Export/Import(增量+全量)
前言 本文基于伪分布式搭建 hadoop+zookeeper+hbase+opentsdb之后,文章链接:https://www.cnblogs.com/yybrhr/p/11128149.html, ...
- 增量+全量备份SVN服务器
#!/bin/bash # 获取当前是星期几 DAY=$(date +%w) # 获取当前的日期 DATE=$(date '+%Y-%m-%d-%H-%M') # 获取当前版本库中最新的版本 CURR ...
- 利用ant脚本 自动构建svn增量/全量 系统程序升级包
首先请允许我这样说,作为开发或测试,你一定要具备这种 本领.你可以手动打包.部署你的工程,但这不是最好的方法.最好的方式就是全自动化的方式.开发人员提交了代码后,可以自动构建.打包.部署到测试环境. ...
- solr-DIH:dataimport增量全量创建索引
索引创建完毕,就要考虑怎么定时的去重建, 除了写solrj,可以定时调用下面两条url进行增量或者全量创建索引 全量:http://ip:port/webapp_name/core_name/da ...
- [MySQL] innobackupex在线备份及恢复(全量和增量)
安装percona-xtrabackup 方法1: percona-xtrabackup-2.1.9-744-Linux-x86_64.tar.gz(D:\share\src\linux-mysql) ...
- orcale增量全量实时同步mysql可支持多库使用Kettle实现数据实时增量同步
1. 时间戳增量回滚同步 假定在源数据表中有一个字段会记录数据的新增或修改时间,可以通过它对数据在时间维度上进行排序.通过中间表记录每次更新的时间戳,在下一个同步周期时,通过这个时间戳同步该时间戳以后 ...
随机推荐
- Python 爬取 房天下
... import requests from requests import ConnectionError from bs4 import BeautifulSoup import pymong ...
- PAT A1107——并查集
Social Clusters When register on a social network, you are always asked to specify your hobbies in ...
- Exploring Matrix
import java.util.Scanner; public class J714 { /** * @taking input from user */ public static void ma ...
- Java-ASM框架学习-java概念转字节码概念
前言 当我们操作字节码的时候,都是和字节码的概念打交道,这让我们很困扰,asm也想到了这点,为了方便,它提供了一个可以把java概念转化为字节码概念的类 import org.objectweb.as ...
- System.Web.Optimization
项目中引用了 System.Web.Optimization 这个程序集,缺少程序集会报错: 命名空间"System.Web"中不存在类型或命名空间名"Optimizat ...
- 洛谷 P4272 - [CTSC2009]序列变换(堆)
洛谷题面传送门 u1s1 在我完成这篇题解之前,全网总共两篇题解,一篇使用的平衡树,一篇使用的就是这篇题解讲解的这个做法,但特判掉了一个点,把特判去掉在 BZOJ 上会 WA 一个点. 两篇题解都异常 ...
- Kubernetes(K8s)部署 SpringCloud 服务实战
1. 概述 老话说的好:有可能性就不要放弃,要敢于尝试. 言归正传,之前我们聊了一下如何在 Kubernetes(K8s)中部署容器,今天我们来聊一下如何将 SpringCloud 的服务部署到 Ku ...
- ggplot 画堆叠柱状图
1. 关注下方公众号可获得更多精彩
- Nginx nginx: [emerg] using regex "\.php$" requires PCRE library 或 编译nginx错误:make[1]: *** [/pcre//Makefile] Error 127
nginx: [emerg] using regex "\.php$" requires PCRE library 或 编译nginx错误:make[1]: *** [/pcre ...
- R shinydashboard ——2. 结构
目录 1.Shiny和HTML 2.结构 3. 标题Header 4. 侧边栏Siderbar 5.主体/正文Body box tabBox infoBox valueBox Layouts 1.Sh ...