SLAM的数学基础(4):先验概率、后验概率、贝叶斯准则
假设有事件A和事件B,可以同时发生但不是完全同时发生,如以下韦恩图所示:
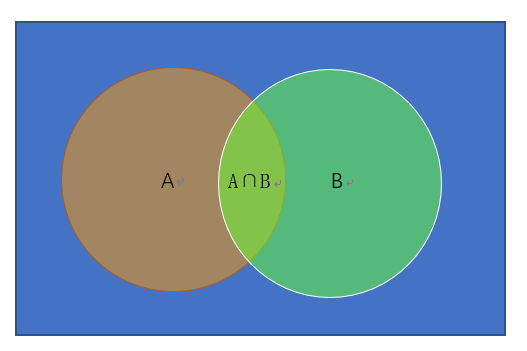
其中,A∩B表示A和B的并集,即A和B同时发生的概率。
如此,我们很容易得出,在事件B发生的情况下,事件A发生的概率为:
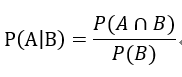
这个P(A|B)就是条件概率(Conditional Probability)。
同理,在事件A发生的情况下,事件B发生的概率为:

由以上式子可得:
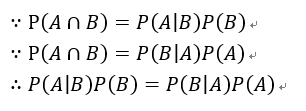
再调整一下,变成:
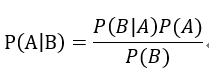
这个就是著名的贝叶斯公式的基本形态了,其中:
P(A|B)叫做后验概率(Posterior Probability)
P(A)叫做先验概率(Prior Probability)
P(B|A)/P(B)叫做似然度(Likelihood)
那么我们可以看出,贝叶斯定理可以比较简单的归纳为:
后验概率=先验概率*似然度
在日常使用中,如贝叶斯分类、贝叶斯回归、贝叶斯滤波等算法,普遍使用迭代和归一化的方法来计算似然度,为了更好的了解归一化的方法,这里还有一个基础概念,叫全概率公式。
接着之前的说法,很明显有

OK,先举几个经典的例子来帮助理解:
一座别墅在过去的 20 年里一共发生过 2 次被盗,别墅的主人有一条狗,狗平均每周晚上叫 3 次,假设在盗贼入侵时狗叫的概率被估计为 0.9,问题是:在狗叫的时候发生入侵的概率是多少?
我们假设:
事件A:狗在晚上叫
事件B:盗贼入侵
以天为单位统计,有:
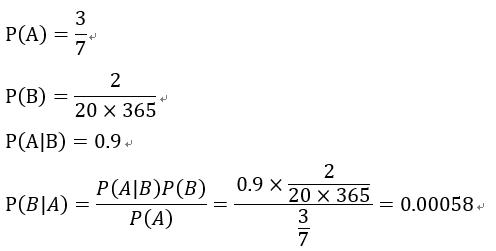
可以看到,最终的结果基本是不可能。
这只是一个最简单的例子,其中,别墅在过去的20年中被盗2次、狗平均每周晚上叫3次这些都是先验统计,而在现实应用中往往是根据上一步的事件去推断下一步的事件,这个迭代的过程往往是很多算法实现的基础。
下面,我们举一个更复杂一些的例子:
假设有两个各装了100个球的箱子,A箱子中有70个红球,30个蓝球,B箱子中有30个红球,70个蓝球。假设随机选择其中一个箱子,从中拿出一个球记下球色再放回原箱子,如此重复12次,记录得到8次红球,4次蓝球。问题来了,你认为被选择的箱子是A箱子的概率有多大?
我们假设得到小球的结果顺序如下:红红红红红红红红蓝蓝蓝蓝,用C++实现:
#include <iostream>
#include <cmath>
#include <iomanip>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <limits> class balls_case_problem
{
private:
double p_a;
double p_b;
double p_red_in_a;
double p_blue_in_a;
double p_red_in_b;
double p_blue_in_b; public:
balls_case_problem(int red_balls_in_a, int blue_balls_in_a, int red_balls_in_b, int blue_balls_in_b)
{
p_a = 0.5;
p_b = 1 - p_a; p_red_in_a = (double)red_balls_in_a / (double)(red_balls_in_a + blue_balls_in_a);
p_blue_in_a = 1 - p_red_in_a; p_red_in_b = (double)red_balls_in_b / (double)(red_balls_in_b + blue_balls_in_b);
p_blue_in_b = 1 - p_red_in_b;
} ~balls_case_problem(){}; void got_red()
{
p_a = (p_red_in_a * p_a) / ((p_red_in_a * p_a) + (p_red_in_b * p_b));
p_b = 1 - p_a;
} void got_blue()
{
p_a = (p_blue_in_a * p_a) / ((p_blue_in_a * p_a) + (p_blue_in_b * p_b));
p_b = 1 - p_a;
} double get_p_a()
{
return p_a;
} double get_p_b()
{
return p_b;
}
}; int main()
{
int red_ball_results[] = {1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0};
balls_case_problem problem(70, 30, 30, 70); for(int i = 0; i < sizeof(red_ball_results) / sizeof(int); i++)
{
if(red_ball_results[i] == 1)
{
problem.got_red();
}else{
problem.got_blue();
}
std::cout << "Probility of chose case A: " << problem.get_p_a() << std::endl;
} return 0;
}
运行结果为:
Probility of chose case A: 0.7
Probility of chose case A: 0.844828
Probility of chose case A: 0.927027
Probility of chose case A: 0.967365
Probility of chose case A: 0.985748
Probility of chose case A: 0.993842
Probility of chose case A: 0.997351
Probility of chose case A: 0.998863
Probility of chose case A: 0.997351
Probility of chose case A: 0.993842
Probility of chose case A: 0.985748
Probility of chose case A: 0.967365
SLAM的数学基础(4):先验概率、后验概率、贝叶斯准则的更多相关文章
- 贝叶斯推断 && 概率编程初探
1. 写在之前的话 0x1:贝叶斯推断的思想 我们从一个例子开始我们本文的讨论.小明是一个编程老手,但是依然坚信bug仍有可能在代码中存在.于是,在实现了一段特别难的算法之后,他开始决定先来一个简单的 ...
- 【cs229-Lecture5】生成学习算法:1)高斯判别分析(GDA);2)朴素贝叶斯(NB)
参考: cs229讲义 机器学习(一):生成学习算法Generative Learning algorithms:http://www.cnblogs.com/zjgtan/archive/2013/ ...
- 机器学习算法实践:朴素贝叶斯 (Naive Bayes)(转载)
前言 上一篇<机器学习算法实践:决策树 (Decision Tree)>总结了决策树的实现,本文中我将一步步实现一个朴素贝叶斯分类器,并采用SMS垃圾短信语料库中的数据进行模型训练,对垃圾 ...
- 朴素贝叶斯python小样本实例
朴素贝叶斯优点:在数据较少的情况下仍然有效,可以处理多类别问题缺点:对于输入数据的准备方式较为敏感适用数据类型:标称型数据朴素贝叶斯决策理论的核心思想:选择具有最高概率的决策朴素贝叶斯的一般过程(1) ...
- 【机器学习实战】第4章 朴素贝叶斯(Naive Bayes)
第4章 基于概率论的分类方法:朴素贝叶斯 朴素贝叶斯 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类.本章首先介绍贝叶斯分类算法的基础——贝叶斯定理.最后,我们 ...
- 贝叶斯推断之最大后验概率(MAP)
贝叶斯推断之最大后验概率(MAP) 本文详细记录贝叶斯后验概率分布的数学原理,基于贝叶斯后验概率实现一个二分类问题,谈谈我对贝叶斯推断的理解. 1. 二分类问题 给定N个样本的数据集,用\(X\)来表 ...
- Java实现基于朴素贝叶斯的情感词分析
朴素贝叶斯(Naive Bayesian)是一种基于贝叶斯定理和特征条件独立假设的分类方法,它是基于概率论的一种有监督学习方法,被广泛应用于自然语言处理,并在机器学习领域中占据了非常重要的地位.在之前 ...
- 从贝叶斯到粒子滤波——Round 1
粒子滤波确实是一个挺复杂的东西,从接触粒子滤波到现在半个多月,博主哦勒哇看了N多篇文章,查略了嗨多资料,很多内容都是看了又看,细细斟酌.今日,便在这里验证一下自己的修炼成果,请各位英雄好汉多多指教. ...
- 朴素贝叶斯(NB)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合 内容: 1.算法概述 贝叶斯分类算法是统计学的一种分类方法,其分类原理就是利用贝叶斯公式根据某 ...
随机推荐
- ISP算法高水平分析(下)
ISP算法高水平分析(下) 十.LSC(Lens Shade Correction)------镜头阴影矫正 Lens Shading指画面四角由于入射光线不足形成的暗角,同时,由于不同频率的光折射 ...
- AI芯片体系结构目标图形处理
AI芯片体系结构目标图形处理 AI chip architecture targets graph processing 可编程图形流处理器(GSP)能够执行"直接图形处理.片上任务图管理和 ...
- 77GHz 和24GHz Radar性能解析
77GHz 和24GHz Radar性能解析 一.77GHz MRR 77GHz MRR Automotive Collision Warning Radar Application MRR – Fo ...
- TinyML设备设计的Arm内核
TinyML设备设计的Arm内核 Arm cores designed for TinyML devices Arm推出了两个新的IP核,旨在为终端设备.物联网设备和其低功耗.成本敏感的应用程序提供机 ...
- Java IO学习笔记一:为什么带Buffer的比不带Buffer的快
作者:Grey 原文地址:Java IO学习笔记一:为什么带Buffer的比不带Buffer的快 Java中为什么BufferedReader,BufferedWriter要比FileReader 和 ...
- java后端知识点梳理——Redis
redis都支持哪些数据类型?应用场景有哪些? redis支持五种数据类型作为其Value,redis的Key都是字符串类型的. string:redis 中字符串 value 最大可为512M.可以 ...
- CentOS 30分钟部署 .net core 在线客服系统
前段时间我发表了一系列文章,开始介绍基于 .net core 的在线客服系统开发过程.期间有一些朋友希望能够给出 Linux 环境的安装部署指导,本文基于 CentOS 8.3 来安装部署.在本文中我 ...
- 三、部署被监控主机-Zabbix Agent
三.部署被监控主机-Zabbix Agent 1) 源码安装Zabbix agent软件 在2.100和2.200做相同操作(以zabbixclient web1为例). [root@zabbixcl ...
- linux远程和软件包的管理
远程管理 ssh 用户名@对方IP地址 -X 在本地可以运行对方的图形程序 端口 22 [root@room9pc01 ~]# ssh root@172.25.0.11 [root@serve ...
- 分布式系统ID的生成方法之UUID、数据库、算法、Redis、Leaf方案
一般单机或者单数据库的项目可能规模比较小,适应的场景也比较有限,平台的访问量和业务量都较小,业务ID的生成方式比较原始但是够用,它并没有给这样的系统带来问题和瓶颈,所以这种情况下我们并没有对此给予太多 ...