如何基于Jupyter notebook搭建Spark集群开发环境
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境。
本文分享自华为云社区《基于Jupyter Notebook 搭建Spark集群开发环境》,作者:apr鹏鹏。
一、概念介绍:
1、Sparkmagic:它是一个在Jupyter Notebook中的通过Livy服务器 Spark REST与远程Spark群集交互工作工具。Sparkmagic项目包括一组以多种语言交互运行Spark代码的框架和一些内核,可以使用这些内核将Jupyter Notebook中的代码转换在Spark环境运行。
2、Livy:它是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行。它提供了以下这些基本功能:提交Scala、Python或是R代码片段到远端的Spark集群上执行,提交Java、Scala、Python所编写的Spark作业到远端的Spark集群上执行和提交批处理应用在集群中运行
二、基本框架为下图所示:
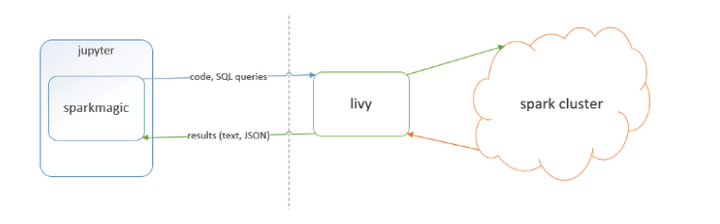
三、准备工作:
具备提供Saprk集群,自己可以搭建或者直接使用华为云上服务,如MRS,并且在集群上安装Spark客户端。同节点(可以是docker容器或者虚拟机)安装Jupyter Notebook和Livy,安装包的路径为:https://livy.incubator.apache.org/download/
四、配置并启动Livy:
修改livy.conf 参考:https://enterprise-docs.anaconda.com/en/latest/admin/advanced/config-livy-server.html
添加如下配置:
livy.spark.master = yarn
livy.spark.deploy-mode = cluster
livy.impersonation.enabled = false
livy.server.csrf-protection.enabled = false
livy.server.launch.kerberos.keytab=/opt/workspace/keytabs/user.keytab
livy.server.launch.kerberos.principal=miner
livy.superusers=miner
修改livy-env.sh, 配置SPARK_HOME、HADOOP_CONF_DIR等环境变量
export JAVA_HOME=/opt/Bigdata/client/JDK/jdk
export HADOOP_CONF_DIR=/opt/Bigdata/client/HDFS/hadoop/etc/hadoop
export SPARK_HOME=/opt/Bigdata/client/Spark2x/spark
export SPARK_CONF_DIR=/opt/Bigdata/client/Spark2x/spark/conf
export LIVY_LOG_DIR=/opt/workspace/apache-livy-0.7.0-incubating-bin/logs
export LIVY_PID_DIR=/opt/workspace/apache-livy-0.7.0-incubating-bin/pids
export LIVY_SERVER_JAVA_OPTS="-Djava.security.krb5.conf=/opt/Bigdata/client/KrbClient/kerberos/var/krb5kdc/krb5.conf -Dzookeeper.server.principal=zookeeper/hadoop.hadoop.com -Djava.security.auth.login.config=/opt/Bigdata/client/HDFS/hadoop/etc/hadoop/jaas.conf -Xmx128m"
启动Livy:
./bin/livy-server start
五、安装Jupyter Notebook和sparkmagic
Jupyter Notebook是一个开源并且使用很广泛项目,安装流程不在此赘述
sparkmagic可以理解为在Jupyter Notebook中的一种kernel,直接pip install sparkmagic。注意安装前系统必须具备gcc python-dev libkrb5-dev工具,如果没有,apt-get install或者yum install安装。安装完以后会生成$HOME/.sparkmagic/config.json文件,此文件为sparkmagic的关键配置文件,兼容spark的配置。关键配置如图所示

其中url为Livy服务的ip和端口,支持http和https两种协议
六、添加sparkmagic kernel
PYTHON3_KERNEL_DIR="$(jupyter kernelspec list | grep -w "python3" | awk '{print $2}')"
KERNELS_FOLDER="$(dirname "${PYTHON3_KERNEL_DIR}")"
SITE_PACKAGES="$(pip show sparkmagic|grep -w "Location" | awk '{print $2}')"
cp -r ${SITE_PACKAGES}/sparkmagic/kernels/pysparkkernel ${KERNELS_FOLDER}
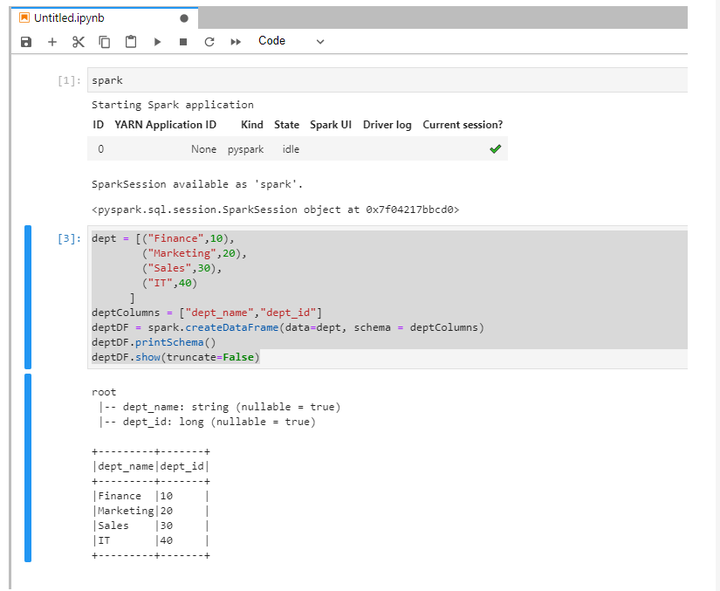
七、在Jupyter Notebook中运行spark代码验证:
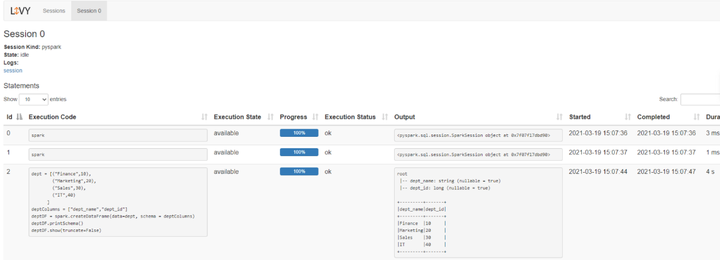
八、访问Livy查看当前session日志:
如何基于Jupyter notebook搭建Spark集群开发环境的更多相关文章
- vagrant+docker搭建consul集群开发环境
HashiCorp 公司推出的Consul是一款分布式高可用服务治理与服务配置的工具.关于其配置与使用可以参考这篇文章 consul 简介与配置说明. 一般,我们会在多台主机上安装并启动 consul ...
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- 实验室中搭建Spark集群和PyCUDA开发环境
1.安装CUDA 1.1安装前工作 1.1.1选取实验器材 实验中的每台计算机均装有双系统.选择其中一台计算机作为master节点,配置有GeForce GTX 650显卡,拥有384个CUDA核心. ...
- 从0到1搭建spark集群---企业集群搭建
今天分享一篇从0到1搭建Spark集群的步骤,企业中大家亦可以参照次集群搭建自己的Spark集群. 一.下载Spark安装包 可以从官网下载,本集群选择的版本是spark-1.6.0-bin-hado ...
- 搭建spark集群
搭建spark集群 spark1.6和hadoop2.61.准备hadoop环境:2.准备下载包:3.解压安装包:tar -xf spark-1.6.0-bin-hadoop2.6.tgz4.修改配置 ...
- hadoop-2.6.0集群开发环境配置
hadoop-2.6.0集群开发环境配置 一.环境说明 1.1安装环境说明 本例中,操作系统为CentOS 6.6, JDK版本号为JDK 1.7,Hadoop版本号为Apache Hadoop 2. ...
- 基于zookeeper+leveldb搭建activemq集群--转载
原地址:http://www.open-open.com/lib/view/open1410569018211.html 自从activemq5.9.0开始,activemq的集群实现方式取消了传统的 ...
- 大数据平台搭建-spark集群安装
版本要求 java 版本:1.8.*(1.8.0_60) 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- 03.搭建Spark集群(CentOS7+Spark2.1.1+Hadoop2.8.0)
接上一篇:https://www.cnblogs.com/yjm0330/p/10077076.html 一.下载安装scala 1.官网下载 2.spar01和02都建立/opt/scala目录,解 ...
随机推荐
- JDBC中级篇(MYSQL)——在JDBC中如何获得表中的,自增长的字段值
注意:其中的JdbcUtil是我自定义的连接工具类:代码例子链接: package c_increment; import java.sql.Connection; import java.sql.P ...
- 转:C语言自增自減问题总结
C语言自增自減问题总结 在程序设计中,经常遇到"i=i+1"和"i=i-1"这两种极为常用的操作.C语言为这种操作提供了两个更为简洁的运算符,即++和--,分别 ...
- RapidSVN设置diff和edit工具
菜单栏 -> View -> Preferences -> Programs选择相应的配置页即可 需要配置的路径,默认都在 /usr/bin目录下的 editor可以用ged ...
- Python:MySQL拒绝从远程访问的解决方法
MySQL连接数据库 #!/usr/bin/python # -*- coding: UTF-8 -*- import pymysql # 打开数据库连接 db = pymysql.connect(& ...
- Install Percona XtraDb Cluster 5.6.20 on CentOS 6.5
http://blog.51cto.com/hj192837/1546149 You should have odd number of real nodes. node #1hostname: pe ...
- Springboot 日志、配置文件、接口数据如何脱敏?老鸟们都是这样玩的!
一.前言 核心隐私数据无论对于企业还是用户来说尤其重要,因此要想办法杜绝各种隐私数据的泄漏.下面陈某带大家从以下三个方面讲解一下隐私数据如何脱敏,也是日常开发中需要注意的: 配置文件数据脱敏 接口返回 ...
- Mac超好用的软件合集和系统设置
软件篇 这些软件好像只有动态壁纸是收费的. 推荐的都是特别小巧,更加专注特定功能,没那么多花里胡哨.当然你们有什么更好用的也可以推荐. 简单,好用才是我最喜欢的. Bob Github开源,Bob 是 ...
- hyperf从零开始构建微服务(一)——构建服务提供者
阅读目录 什么是服务 构建服务提供者 1.创建数据表 2.构建服务提供者 3.安装json rpc依赖 4.安装rpc server组件 5.修改server配置 6.配置数据库 7.编写基础代码 7 ...
- 洛谷P1083 借教室 题解
题目 [NOIP2012 提高组] 借教室 题解 这道题是几周之前做到的一道题,本来不想讲的,因为这道题也是用到了二分答案的方法,这类题目之前已经发布过两篇题解了.但这道题还运用了差分数组这个思想,所 ...
- Hounter
这题是概率与期望,不是很熟,所以冲了两篇题解才来写总结. 首先可以发现1猎人死的轮数是他之前死了的列人数加一. 那么题目转化为求先于一号猎人死的猎人数的期望值. 考虑这样一个事情,就是 ...