基于MCRA-OMLSA的语音降噪(一):原理
前面的几篇文章讲了webRTC中的语音降噪。最近又用到了基于MCRA-OMLSA的语音降噪,就学习了原理并且软件实现了它。MCRA主要用于噪声估计,OMLSA是基于估计出来的噪声去做降噪。类比于webRTC中的降噪方法,也有噪声估计(分位数噪声估计法)和基于估计出来的噪声降噪(维纳滤波),MCRA就相当于分位数噪声估计法,OMLSA就相当于维纳滤波。本文先讲讲怎么用MCRA和OMLSA来做语音降噪的原理,后续会讲怎么来做软件实现。
一, MCRA
MCRA的全称是Minima Controlled Recursive Averaging(最小值控制的递归平均),是cohen提出的一种常用的噪声估计方法,具体见论文《Noise Estimation by Minima Controlled Recursive Averaging for Robust Speech Enhancement》。 从名字就可看出这个方法主要包括两部分,最小值控制和递归平均。 最小值控制用来算语音存在概率,递归平均用来做噪声估计,即基于语音存在概率做噪声估计。先定义一些名称,然后分别看这两部分。用l表示第l帧,k表示第k个频点,Y(k, l)表示带噪语音第l帧的第k个频点的幅度谱,N(k, l)表示噪声第l帧的第k个频点的幅度谱,S(k, l)表示干净语音第l帧的第k个频点的幅度谱,H0(k, l)表示第l帧的第k个频点上只有噪声,H1(k, l)表示第l帧的第k个频点上有语音。P(H1(k, l) | Y(k, l)) 表示第l帧的第k个频点上是语音的概率,P(H0(k, l) | Y(k, l)) 表示第l帧的第k个频点上是噪声的概率,显然P(H0(k, l) | Y(k, l)) + P(H1(k, l) | Y(k, l)) = 1。
1, 用最小值控制来算语音存在概率
前面的文章(webRTC中语音降噪模块ANS细节详解(四))讲过webRTC的ANS是基于似然比等来算语音存在概率。而这里是用最小值控制来算语音存在概率,即基于当前带噪语音的能量谱与指定长度帧内带噪语音的能量谱的最小值的比值来计算,具体如下:
1) 对带噪语音的能量谱做频域平滑和时域平滑
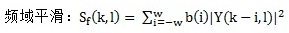
从上式可见,平滑窗的长度是奇数(2w + 1),系数是b(i)。
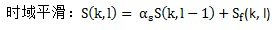
其中,αs (0 < αs < 1)是平滑因子。
2) 搜索能量谱最小值
定义Smin(k, l)和Stmp(k, l),并对它们初始化如下:

然后按频点从第一帧开始逐帧比较:
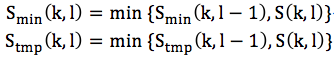
当到第L帧后:
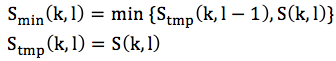
后面以L帧为一个周期,重复上面两步,得到这个周期内的Smin(k, l)和Stmp(k, l)。搜索窗的帧长度L会影响到噪声的跟踪速度,一般按照经验选0.5s~1.5s左右。
3) 计算语音存在概率
定义Sr(k, l)为当前帧相应频点的能量谱与最小值的比值,即
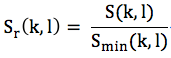
再定义二值I (k, l)如下:
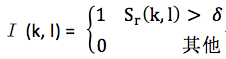
最终语音存在概率通过下式得到:
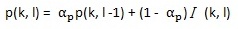
其中,αp (0 < αp < 1)是平滑因子。此处的p(k, l)就是P(H1(k, l) | Y(k, l))。为书写方便,下文用p表示P(H1(k, l) | Y(k, l)),用1-p表示P(H0(k, l) | Y(k, l))。
2, 用递归平均来估计噪声
通常认为噪声都是加性噪声,所以有下式:
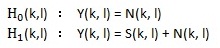
定义σ(k, l)表示第l帧的第k个频点上的噪声能量谱。这里噪声更新的思路如下:当语音不存在时更新噪声的估计,当语言存在时用前一帧的噪声估计值作为当前噪声的估计值,表示如下式:
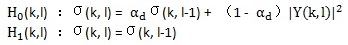
其中,αd (0 < αd < 1)是平滑因子。
所以噪声能量谱的估计如下式(p = P(H1(k, l) | Y(k, l)),为语音存在概率):
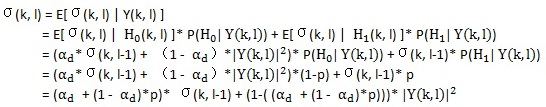
αd是tuning出来的,每个频点上的语音存在概率是上面基于最小控制的方法算出来的,上一帧估计出来的噪声能量谱σ(k, l-1)和当前帧的带噪语音的能量谱均已知,这样当前帧的估计出来的噪声的能量谱就可求出了。
通常令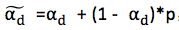 ,这样上式就可写成下式:
,这样上式就可写成下式:
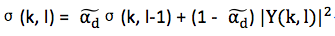
这就是噪声估计的数学表达式。
二, OMLSA
噪声估计出来后就要基于它做降噪了。这里用的是OMLSA(Optimally Modified Log-Spectral Amplitude Estimator,最优修正的对数幅度谱估计),依旧是cohen提出来的,论文是《Optimal Speech Enhancement Under Signal Presence Uncertainty Using Log-Spectral Amplitude Estimator》。OMLSA是MMSE-LSA的改进算法,目的是得到增益gain。算法推导有些复杂,这里只给出gain的表达式,如下:
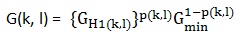
其中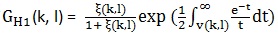 ,Gmin为预先设定的值,p(k, l)是语音存在概率。这里
,Gmin为预先设定的值,p(k, l)是语音存在概率。这里 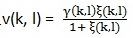 , ξ(k, l)是先验性噪比,γ(k, l)是后验性噪比。先验性噪比和后验性噪比在文章(webRTC中语音降噪模块ANS细节详解(一))中讲过。后验性噪比的计算基于上面用MCRA估计出来的噪声,
, ξ(k, l)是先验性噪比,γ(k, l)是后验性噪比。先验性噪比和后验性噪比在文章(webRTC中语音降噪模块ANS细节详解(一))中讲过。后验性噪比的计算基于上面用MCRA估计出来的噪声, , 先验性噪比计算依旧用文章(webRTC中语音降噪模块ANS细节详解(三))中提到的DD方法,表达式如下:
, 先验性噪比计算依旧用文章(webRTC中语音降噪模块ANS细节详解(三))中提到的DD方法,表达式如下:
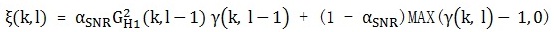
其中,αSNR (0 < αSNR < 1)是平滑因子。
G(k, l)得到后,降噪后干净语音的每个频点的幅度谱可通过下式得到:
S(k, l) = G(K, l)Y(k, l)
以上就是基于MCRA-OMLSA的语音降噪原理。这里需要指出的是噪声估计和语音降噪相对独立,有不同的组合方式来降噪,比如MCRA也可以和维纳滤波结合来降噪。
基于MCRA-OMLSA的语音降噪(一):原理的更多相关文章
- webRTC中语音降噪模块ANS细节详解(一)
ANS(adaptive noise suppression) 是webRTC中音频相关的核心模块之一,为众多公司所使用.从2015年开始,我在几个产品中使用了webRTC的3A(AEC/ANS/AG ...
- 基于MCRA-OMLSA的语音降噪(二):实现
上篇文章(基于MCRA-OMLSA的语音降噪(一):原理)讲了基于MCRA-OMLSA降噪的原理,本篇讲怎么做软件实现.软件实现有多种方式.单纯看降噪效果可用python,因为python有丰富的库可 ...
- 基于MCRA-OMLSA的语音降噪(三):实现(续)
上篇文章(基于MCRA-OMLSA的语音降噪(二):实现)讲了基于MCRA-OMLSA的语音降噪的软件实现.本篇继续讲,主要讲C语言下怎么对数学库里的求平方根(sqrt()).求自然指数(exp()) ...
- 语音降噪论文“A Hybrid Approach for Speech Enhancement Using MoG Model and Neural Network Phoneme Classifier”的研读
最近认真的研读了这篇关于降噪的论文.它是一种利用混合模型降噪的方法,即既利用了生成模型(MoG高斯模型),也利用了判别模型(神经网络NN模型).本文根据自己的理解对原理做了梳理. 论文是基于" ...
- webRTC中语音降噪模块ANS细节详解(二)
上篇(webRTC中语音降噪模块ANS细节详解(一))讲了维纳滤波的基本原理.本篇先给出webRTC中ANS的基本处理过程,然后讲其中两步(即时域转频域和频域转时域)中的一些处理细节. ANS的基本处 ...
- webRTC中语音降噪模块ANS细节详解(三)
上篇(webRTC中语音降噪模块ANS细节详解(二))讲了ANS的处理流程和语音在时域和频域的相互转换.本篇开始讲语音降噪的核心部分,首先讲噪声的初始估计以及基于估计出来的噪声算先验信噪比和后验信噪比 ...
- webRTC中语音降噪模块ANS细节详解(四)
上篇(webRTC中语音降噪模块ANS细节详解(三))讲了噪声的初始估计方法以及怎么算先验SNR和后验SNR. 本篇开始讲基于带噪语音和特征的语音和噪声的概率计算方法和噪声估计更新以及基于维纳滤波的降 ...
- 基于简单sql语句的sql解析原理及在大数据中的应用
基于简单sql语句的sql解析原理及在大数据中的应用 李万鸿 老百姓呼吁打土豪分田地.共同富裕,总有一天会实现. 全面了解你所不知道的外星人和宇宙真想:http://pan.baidu.com/s/1 ...
- 基于LNMP(fastcgi协议)环境部署、原理介绍以及fastcgi_cache配置以及upstream模块负载均衡讲解
ngx_http_proxy_module只能反向代理后端使用HTTP协议的主机.而ngx_http_fastcgi_module只能反向代理后端使用FPM或者使用FastCGI协议的客户端. 一.部 ...
随机推荐
- [noi1773]function
以统计x坐标的数量为例:x为下标建一棵线段树,然后对每一个区间按照y坐标建一棵可持久化线段树(每一个x只保留最大的一个y),询问时,二分找到这个区间内最大的y以前的点并统计,复杂度为$o(nlog^{ ...
- App 端自动化的最佳方案,完全解放双手!
1. 前言 大家好,我是安果! 之前写过一篇文章,文中提出了一种方案,可以实现每天自动给微信群群发新闻早报 如何利用 Python 爬虫实现给微信群发新闻早报?(详细) 但是对于很多人来说,首先编写一 ...
- Ubuntu压缩和解压缩
1.常用的压缩格式 tar tar.bz2 tar.gz 2.gzip压缩 gzip xxx //压缩 gzip -d xxx.gz //解压缩 gzip对文件夹的压缩 gzip -r xxx //文 ...
- dart系列之:时间你慢点走,我要在dart中抓住你
目录 简介 DateTime Duration 总结 简介 时间和日期是我们经常会在程序中使用到的对象.但是对时间和日期的处理因为有不同时区的原因,所以一直以来都不是很好用.就像在java中,为时间和 ...
- OI省选算法汇总及学习计划(转)
1.1 基本数据结构 数组(√) 链表(√),双向链表(√) 队列(√),单调队列(√),双端队列(√) 栈(√),单调栈(√) 1.2 中级数据结构 堆(√) 并查集与带权并查集(√) hash 表 ...
- Xpath解析库的使用
### Xpath常用规则 ## nodename 选取此节点的所有子节点 ## / 从当前节点选取直接子节点 ## // 从当前节点选取子孙节点 ## . 选取当前节点 ## .. 选取当前节点的父 ...
- MybatisPlus入门程序
参考资料:MybatisPlus官网 环境搭建 创建数据库 CREATE DATABASE `mybatisplus` USE `mybatisplus` CREATE TABLE `user ...
- 日常Java 2021/10/1
正则表达式 \cx匹配由x指明的控制字符.例如,lcM匹配一个Control-M或回车符.x的值必须为A-Z或a-z之一.否则,将c视为一个原义的'℃'字符.\f匹配--个换页符.等价于\xOc和\c ...
- 学习java 7.9
学习内容: Date类 Date类常用方法 SimpleDateFormat 1.格式化(从Date到String) public final String format(Date date) 将日期 ...
- [云原生]Docker - 安装&卸载
目录 系统要求 卸载旧版本 安装Docker 方法一:通过repo安装 设置Repository 安装Docker Engine 升级Docker Engine 方法二:通过package安装 方法三 ...