nodejs实现拉钩网爬虫
概述
详细
一、准备工作
1、安装最新版本的nodejs,其中npm会被自动安装
2、安装该项目需要的包
npm install cheerio jsdom mysql request -S
其中package.json中的内容为:
"dependencies": {
"cheerio": "^1.0.0-rc.1",
"jsdom": "^11.0.0",
"mysql": "^2.13.0",
"request": "^2.81.0"
}
二、程序实现
1、程序实现的目录结构如下:
2、实现思路如下:
index.js:程序主文件,各种数据清洗工作,url构造在这个文件中完成
Job.js : 用于构建Job对象,有助于写入数据库
db.js:连接数据库并写入数据
url_construct.js:可以自己配置抓取那些公司的职位信息。如阿里巴巴,百度,腾讯等。部分代码如下:
const companyNames = ["网易","阿里巴巴","百度","腾讯","去哪儿","浪潮"];
const encodedCompanyNames = [];
//转化为urlencoded
for(let i=0;i<companyNames.length;i++){
encodedCompanyNames.push(encodeURIComponent(companyNames[i]));
}
module.exports = encodedCompanyNames;
3、数据库设计截图

上面是本例子的数据库截图,其中id是主键,同时是自增的。
4、连接数据库注意点
下面的user和password的值是你安装数据库时候设置的,请自己修改
const pool = mysql.createPool({
connectionLimit:10,
database:TEST_DATABASE,
user:"root",
password:"root"
});
三、运行效果
首先cd到src目录下,然后简单的运行下面的命令就可以了:
node index.js
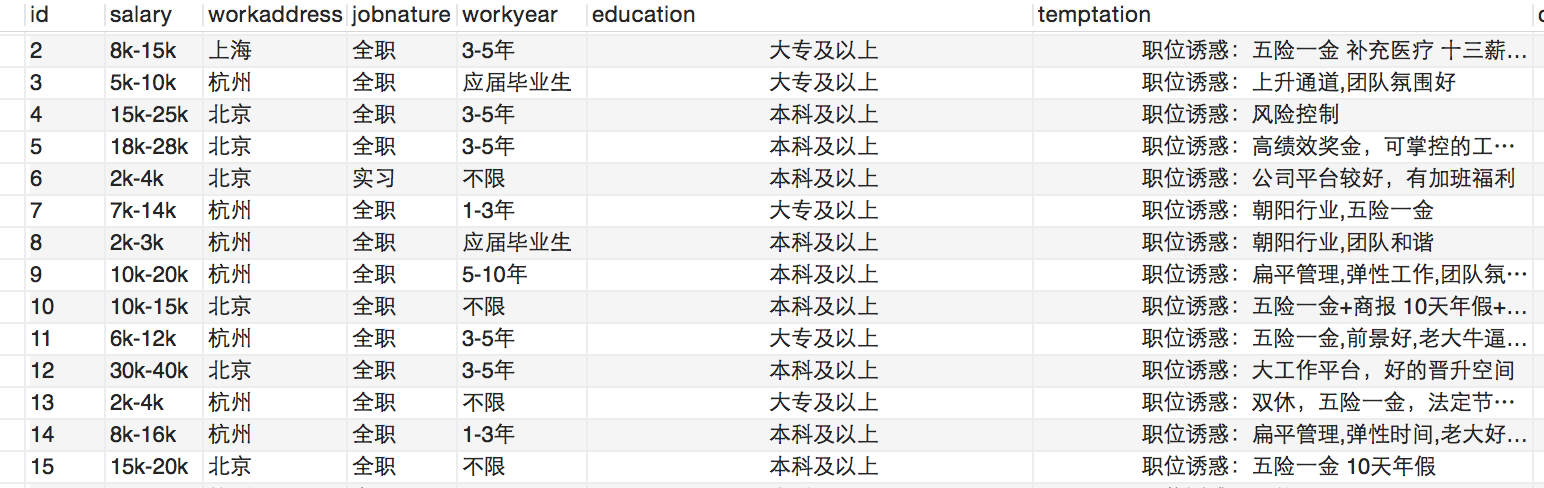
下面是数据库抓取的部分信息截图:
四、其他补充
如果你需要增加更多功能,可以在demo大师的"没有找到例子?"功能提出,我会增加例子,谢谢
注:本文著作权归作者,由demo大师发表,拒绝转载,转载需要作者授权
nodejs实现拉钩网爬虫的更多相关文章
- day 112天,爬虫(拉钩网,斗音,GitHub)第二天
提前准备工作.安装准备工作(day3用) 1. 安装scrapy https://www.cnblogs.com/wupeiqi/articles/6229292.html a. 下载twiste ...
- Python3网络爬虫之requests动态爬虫:拉钩网
操作环境: Windows10.Python3.6.Pycharm.谷歌浏览器目标网址: https://www.lagou.com/jobs/list_Python/p-city_0?px=defa ...
- Python3 Scrapy + Selenium + 阿布云爬取拉钩网学习笔记
1 需求分析 想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称.职位名称.薪资待遇.学历要求.岗位需求等信息.该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息, ...
- 拉钩网爬取所有python职位信息
最近在找工作,所以爬取了拉钩网的全部python职位,以便给自己提供一个方向.拉钩网的数据还是比较容易爬取的,得到json数据直接解析就行,废话不多说, 直接贴代码: import json impo ...
- 使用request爬取拉钩网信息
通过cookies信息爬取 分析header和cookies 通过subtext粘贴处理header和cookies信息 处理后,方便粘贴到代码中 爬取拉钩信息代码 import requests c ...
- selelinum+PhantomJS 爬取拉钩网职位
使用selenium+PhantomJS爬取拉钩网职位信息,保存在csv文件至本地磁盘 拉钩网的职位页面,点击下一页,职位信息加载,但是浏览器的url的不变,说明数据不是发送get请求得到的. 我们不 ...
- 爬取拉钩网上所有的python职位
# 2.爬取拉钩网上的所有python职位. from urllib import request,parse import json,random def user_agent(page): #浏览 ...
- Python 爬取拉钩网工作岗位
如果拉钩网html页面做了调整,需要重新调整代码 代码如下 #/usr/bin/env python3 #coding:utf-8 import sys import json import requ ...
- ruby 爬虫爬取拉钩网职位信息,产生词云报告
思路:1.获取拉勾网搜索到职位的页数 2.调用接口获取职位id 3.根据职位id访问页面,匹配出关键字 url访问采用unirest,由于拉钩反爬虫,短时间内频繁访问会被限制访问,所以没有采用多线程, ...
随机推荐
- Matlab注释多行和取消多行注释的快捷键
matlab里注释符号是%,只是单行注释,可是没有多行注释符号,就像C/C++/Java中都有多行注释符号/* */. 如果利用单行注释的方式手工注释一段程序会很麻烦,matlab软件自带快捷键支持 ...
- 【BZOJ】【1014】【JLOI2008】火星人prefix
Splay/二分/Hash 看了网上的题目关键字(都不用点进去看……我也是醉了)了解到做法= =那就上呗,前面做了好几道Splay的题就是为了练手搞这个的. Hash判断字符串是否相同应该很好理解吧? ...
- 【BestCoder】【Round#42】
模拟+链表+DP Orz AK爷faebdc A Growin要跟全部的n个人握手共2n杯香槟,再加上每对关系的两杯香槟,直接统计邻接矩阵中1的个数,再加2n就是answer //BestCoder ...
- 应用Flume+HBase采集和存储日志数据
1. 在本方案中,我们要将数据存储到HBase中,所以使用flume中提供的hbase sink,同时,为了清洗转换日志数据,我们实现自己的AsyncHbaseEventSerializer. pac ...
- Visual GC(监控垃圾回收器)
Java VisualVM默认没有安装Visual GC插件,需要手动安装,JDK的安装目录的bin目露下双击jvisualvm.exe,即可打开Java VisualVM,点击菜单栏 工具-> ...
- convert-a-number-to-hexadecimal
https://leetcode.com/problems/convert-a-number-to-hexadecimal/ // https://discuss.leetcode.com/topic ...
- WebViewClient 简介 API 案例
代码位置:https://github.com/baiqiantao/WebViewTest.git 设计思想理解 在WebView的设计中,不是什么事都要WebView类干的,有相当多的杂事是分给其 ...
- $.jsonp()的简单使用
// jsonp 获取 json 数据: $.jsonp({ url: GLOBAL.baseUrl + '/company/mobi_getposter.action', callback: 'ca ...
- GoLang中如何使用多参数属性传参
我们常常因为传入的参数不确定而头疼不已,golang 为我们提供了接入多值参数用于解决这个问题.但是一般我们直接写已知代码即所有的值都知道一个一个塞进去就好了,但是绝大部分我们是得到用户的大量输入想通 ...
- c语言中pthread的理解和使用
在头文件中看到#typedef unsigned long int pthread_t这句话怎么理解,pthread_t是一个什么类型呢? 相当于pthread_t实际是个unsigned long ...