Hadoop的HDFS和MapReduce的安装(三台伪分布式集群)
一、创建虚拟机
1、从网上下载一个Centos6.X的镜像(http://vault.centos.org/)
2、安装一台虚拟机配置如下:cpu1个、内存1G、磁盘分配20G(看个人配置和需求,本人配置有点低所以参数有点低)
3、虚拟机安装建议去挑战minidesktop,分区自己创建有/boot(300)、swap(300)、/(分配全部空间)。
二、集群环境配置
1.准备Linux环境
设置一个IP地址,先将虚拟机的网络模式选为NAT模式,对应vmnet1和vmnet8,保证能ping通VMNet8和网络 例:www.baidu.com
修改主机名
#vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME= hadoop01
修改IP
两种方式:
第一种:通过Linux图形界面进行修改
进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.35.100 子网掩码:255.255.255.0 (网关:192.168.1.1) -> apply
第二种:修改配置文件方式
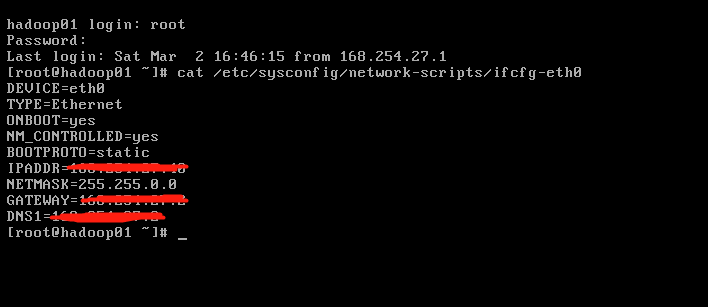
#vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static"
ONBOOT="yes"
TYPE="Ethernet"
IPADDR="192.168.35.100"
NETMASK="255.255.255.0"
修改主机名和IP的映射关系
#vim /etc/hosts
192.168.35.100 hadoop01
192.168.35.101 hadoop02
关闭linux的防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动 开启防火墙 on
chkconfig iptables off
关闭window的防火墙
进入到windows的控制面板-> 找到window防火墙 -> 点击关闭windwos防火墙,全部关闭
开启或关闭linux服务器的图形界面:
vi /etc/inittab
重启Linux : reboot
2.安装JDK
上传JDK (上传工具 wincp ,securecrt ,vmtools)
解压jdk
tar -zxvf jdk-7u80-linux-x64.tar.gz -C /usr/local (一般在linux里放公共的系统使用的文件)
将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/usr/local/jdk1..0_80
export PATH=$PATH:$JAVA_HOME/bin
#刷新配置
source /etc/profile
Java -sersion验证一下
三、Hadoop环境搭建(在这里我将HDFS和YARN的配置信息放在了一起)
1、安装hadoop2.8.5
创建一个目录mkdir /bigdata,先上传hadoop的安装包到服务器上去/bigdata,解压hadoop工具到/bigdata文件中,tar -zxvf hadoop-2.6.4.tar.gz -C /bigdata
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
伪分布式需要修改5个配置文件
2、配置hadoop核心文件
<!--第一个:hadoop-env.sh->
vim hadoop-env.sh
#第27行
export JAVA_HOME=/usr/local/jdk1.7.0_80
<!--第二个:core-site.xml->
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
<!--必须配置了hosts,要不然就是ip-?
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop-2.6.4/data</value>
</property>
<!--第三个:hdfs-site.xml->
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value> 3
</property>
<!--第四个:mapred-site.xml 系统没有直接提供,需要修改模板文件 mv mapred-site.xml.template mapred-site.xml vim mapred-site.xml ->
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 第五个:yarn-site.xml->
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
将hadoop添加到环境变量
vim /etc/proflie
export JAVA_HOME=/usr/local/jdk1..0_80
export HADOOP_HOME=/bigdata/hadoop-2.6.
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
刷新配置文件
source /etc/profile
格式化namenode(是对namenode进行初始化) 格式化文件系统
hdfs namenode -format(历史命令 hadoop namenode -format)
启动hadoop
先启动HDFS
sbin/start-dfs.sh
再启动YARN
sbin/start-yarn.sh
验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
通过网页验证
http://192.168.35.100:50070 (HDFS管理界面)
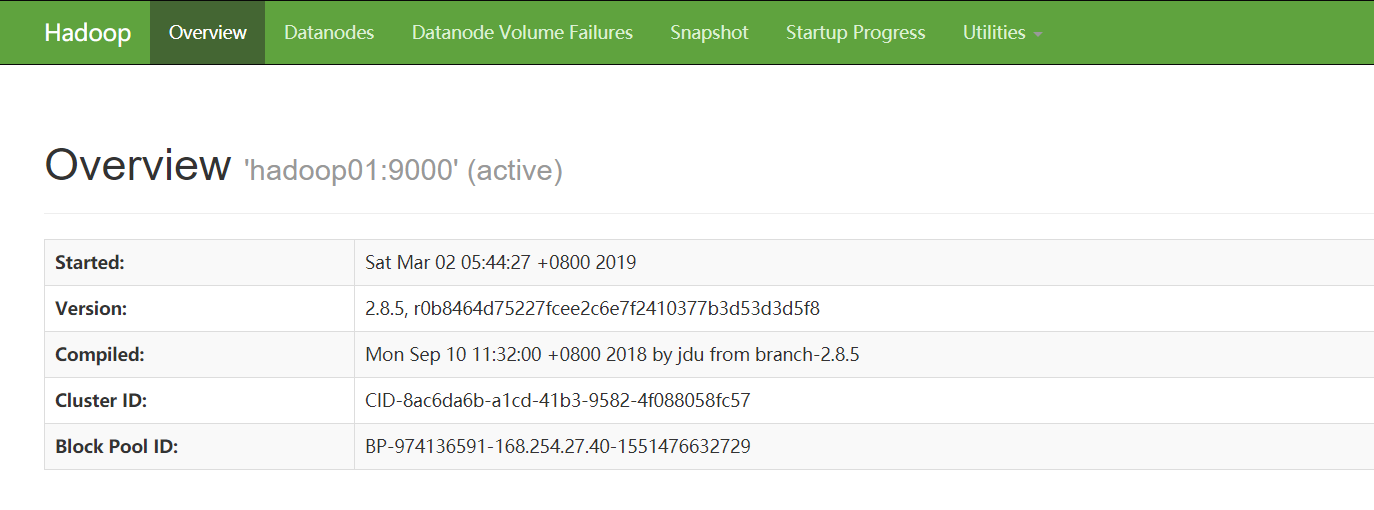
http://192.168.35.100:8088 (MR管理界面)

3、配置ssh免登陆
#生成ssh免登陆密钥
#进入到我的home目录
cd ~/.ssh
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上
ssh-copy-id localhost
到此HDFS和MapReduce搭建完成,有任何出错或疑问可以私信留言也可以关注微信公众号;关于Hadoop的后续还会陆续给大家一一讲解,谢谢阅读。

Hadoop的HDFS和MapReduce的安装(三台伪分布式集群)的更多相关文章
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- Linux单机环境下HDFS伪分布式集群安装操作步骤v1.0
公司平台的分布式文件系统基于Hadoop HDFS技术构建,为开发人员学习及后续项目中Hadoop HDFS相关操作提供技术参考特编写此文档.本文档描述了Linux单机环境下Hadoop HDFS伪分 ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop(二)搭建伪分布式集群
前言 前面只是大概介绍了一下Hadoop,现在就开始搭建集群了.我们下尝试一下搭建一个最简单的集群.之后为什么要这样搭建会慢慢的分享,先要看一下效果吧! 一.Hadoop的三种运行模式(启动模式) 1 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- Hadoop伪分布式集群
一.HDFS伪分布式环境搭建 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时, ...
随机推荐
- idapython 开发
调试方法 使用 pydevd 然后在需要调试处加入调试代码 GetOperandValue 作用 参数1: ea 虚拟地址 参数2: 操作数号 返回指令的操作数的被解析过的值 文档 def GetOp ...
- java 对象
对象可以看成是静态属性和动态属性的封装体.静态属性——成员变量:动态属性——方法. 1.汇编语言是对机器语言的抽象. 2.面向过程的语言是对汇编语言的抽象.属性和方法分离,不是封装在一起的,复用性 ...
- centos7.2+php7.2+nginx1.12.0+mysql5.7配置
一. 源码安装php7.2 选择需要的php版本 从 php官网: http://cn2.php.net/downloads.php 选择需要的php版本,选择.tar.gz 的下载包,点击进入,选择 ...
- ASP.NET中使用UpdatePanel时用Response输出出现错误的解决方法
asp.net中执行到Response.write("xx");之类语句或Microsoft JScript 运行时错误: Sys.WebForms.PageRequestMana ...
- viedo formats vs file formats
web的视频世界,有两个概念非常容易搞混淆,即:视频文件的格式,比如.mp4,.flv,.ogv等等,以及视频本身的格式,就是指的codec算法名称,比如h.264,mpeg-4等. http://w ...
- Entity Framework之DB First方式
EF(Entity Framework的简称,下同)有三种方式,分别是:DataBase First. Model First和Code First. 下面是Db First的方式: 1. 数据库库中 ...
- 细说C#继承
简介 继承(封装.多态)是面向对象编程三大特性之一,继承的思想就是摈弃代码的冗余,实现更好的重用性. 继承从字面上理解,无外乎让人想到某人继承某人的某些东西,一个给一个拿.这个语义在生活中,就像 家族 ...
- Linux 系统其他重要文件
其他重要目录 /usr /usr/local 通过源码安装,没有特别指定,就在这个文件下用户自编译软件存放地方 /usr/src 源代码程序 + 内核源代码程序存放目录 /var /var/log/m ...
- CVE-2013-2551漏洞成因与利用分析(ISCC2014 PWN6)
CVE-2013-2551漏洞成因与利用分析 1. 简介 VUPEN在Pwn2Own2013上利用此漏洞攻破了Win8+IE10,5月22日VUPEN在其博客上公布了漏洞的细节.它是一个ORG数组整数 ...
- vue弹出框的封装
依旧是百度不到自己想要的,就自己动手丰衣足食 弹出框做成单独的组件confirm.vue; <template> <transition name="mask-bg-fad ...