大数据笔记(七)——Mapreduce程序的开发
一.分析Mapreduce程序开发的流程
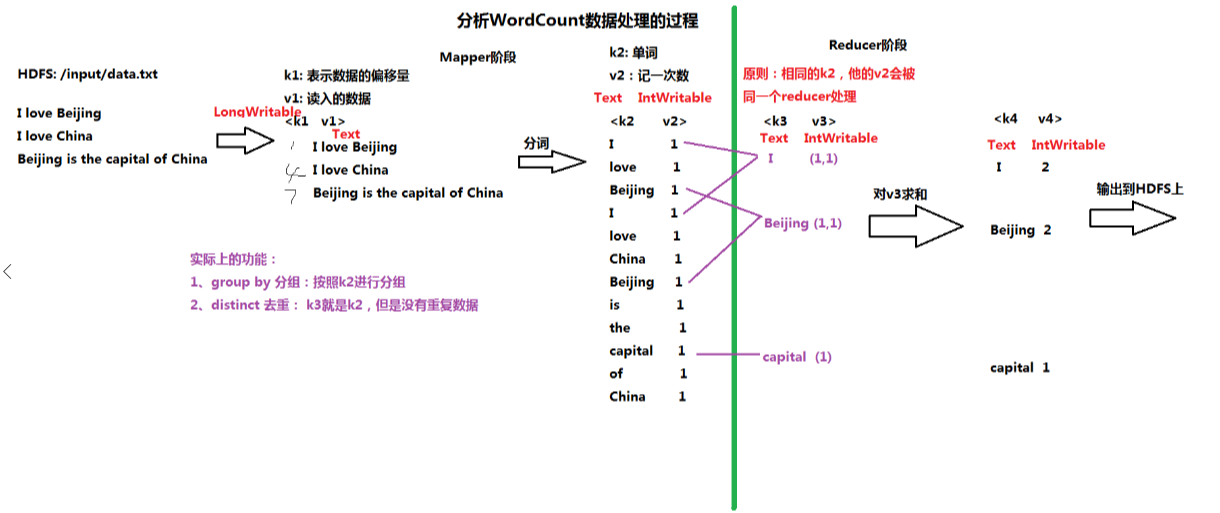
1.图示过程
输入:HDFS文件 /input/data.txt
Mapper阶段:
K1:数据偏移量(以单词记)V1:行数据
K2:单词 V2:记一次数
Reducer阶段 :
K3:单词(=K2) V3:V2计数的集合
K4:单词 V4:V3集合中元素累加和
输出:HDFS
2.开发WordCount程序需要的jar
/root/training/hadoop-2.7.3/share/hadoop/common
/root/training/hadoop-2.7.3/share/hadoop/common/lib /root/training/hadoop-2.7.3/share/hadoop/mapreduce
/root/training/hadoop-2.7.3/share/hadoop/mapreduce/lib
3.WordCountMapper.java
package demo.wc; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException { //Context代表Mapper的上下文 上文:HDFS 下文:Mapper
//取出数据: I love beijing
String data = v1.toString(); //分词
String[] words = data.split(" "); //输出K2 V2
for (String w : words) {
context.write(new Text(w), new LongWritable(1));
} } }
4.WordCountReducer.java
package demo.wc; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ @Override
protected void reduce(Text k3, Iterable<LongWritable> v3,
Context context) throws IOException, InterruptedException {
//context 代表Reduce的上下文 上文:Mapper 下文:HDFS
long total = 0;
for (LongWritable l : v3) {
//对v3求和
total = total + l.get();
} //输出K4 V4
context.write(k3, new LongWritable(total));
} }
5.WordCountMain.java
package demo.wc; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountMain { public static void main(String[] args) throws Exception {
//创建一个job = mapper + reducer
Job job = Job.getInstance(new Configuration());
//ָ指定任务的入口
job.setJarByClass(WordCountMain.class); //ָ指定任务的mapper和输出的数据类型
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);//指定k2
job.setMapOutputValueClass(LongWritable.class);//指定v2
//ָ指定任务的reducer和输出的数据类型
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//ָ指定输入的路径(map)、输出的路径(reduce)
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//ִ执行任务
job.waitForCompletion(true);
}
}
打包,传到HDFS上:

运行任务:
hadoop jar wc.jar /input/data.txt /output/day0228/wc
日志信息:
18/03/01 00:14:00 INFO client.RMProxy: Connecting to ResourceManager at bigdata11/192.168.153.11:8032
18/03/01 00:14:01 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/03/01 00:14:01 INFO input.FileInputFormat: Total input paths to process : 1
18/03/01 00:14:01 INFO mapreduce.JobSubmitter: number of splits:1
18/03/01 00:14:02 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1519833888534_0001
18/03/01 00:14:02 INFO impl.YarnClientImpl: Submitted application application_1519833888534_0001
18/03/01 00:14:02 INFO mapreduce.Job: The url to track the job: http://bigdata11:8088/proxy/application_1519833888534_0001/
18/03/01 00:14:02 INFO mapreduce.Job: Running job: job_1519833888534_0001
18/03/01 00:14:16 INFO mapreduce.Job: Job job_1519833888534_0001 running in uber mode : false
18/03/01 00:14:16 INFO mapreduce.Job: map 0% reduce 0%
18/03/01 00:14:24 INFO mapreduce.Job: map 100% reduce 0%
18/03/01 00:14:31 INFO mapreduce.Job: map 100% reduce 100%
查看结果:
hdfs dfs -ls /output/day0228/wc

hdfs dfs -cat /output/day0228/wc/part-r-00000

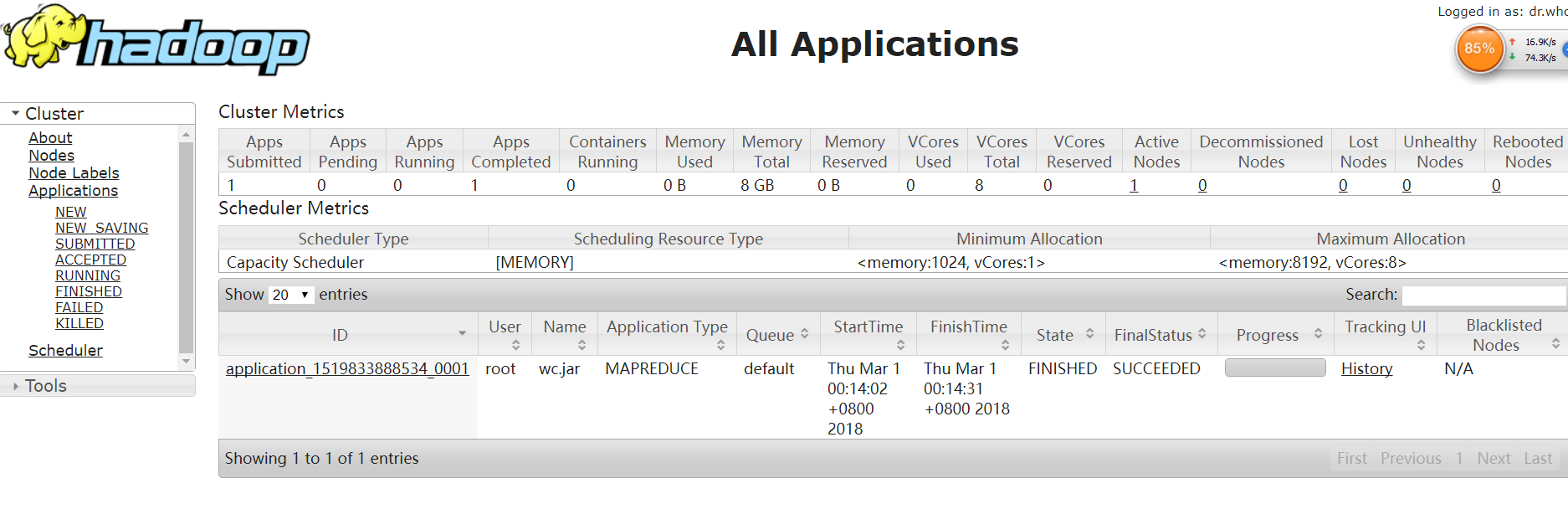
Web Console通过8088端口查看:
大数据笔记(七)——Mapreduce程序的开发的更多相关文章
- 大数据篇:MapReduce
MapReduce MapReduce是什么? MapReduce源自于Google发表于2004年12月的MapReduce论文,是面向大数据并行处理的计算模型.框架和平台,而Hadoop MapR ...
- 《OD大数据实战》MapReduce实战
一.github使用手册 1. 我也用github(2)——关联本地工程到github 2. Git错误non-fast-forward后的冲突解决 3. Git中从远程的分支获取最新的版本到本地 4 ...
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- 大数据笔记(十)——Shuffle与MapReduce编程案例(A)
一.什么是Shuffle yarn-site.xml文件配置的时候有这个参数:yarn.nodemanage.aux-services:mapreduce_shuffle 因为mapreduce程序运 ...
- 大数据笔记(八)——Mapreduce的高级特性(A)
一.序列化 类似于Java的序列化:将对象——>文件 如果一个类实现了Serializable接口,这个类的对象就可以输出为文件 同理,如果一个类实现了的Hadoop的序列化机制(接口:Writ ...
- 基于Hbase数据的Mapreduce程序环境开发
一.实验目标 编写Mapreduce程序,以Hbase表数据为Map输入源,计算结果输出到HDFS或者Hbase表中. 在非CDH5的Hadoop集群环境中,将编写好的Mapreduce程序整个工程打 ...
- 大数据基础总结---MapReduce和YARN技术原理
Map Reduce和YARN技术原理 学习目标 熟悉MapReduce和YARN是什么 掌握MapReduce使用的场景及其原理 掌握MapReduce和YARN功能与架构 熟悉YARN的新特性 M ...
- 大数据笔记01:大数据之Hadoop简介
1. 背景 随着大数据时代来临,人们发现数据越来越多.但是如何对大数据进行存储与分析呢? 单机PC存储和分析数据存在很多瓶颈,包括存储容量.读写速率.计算效率等等,这些单机PC无法满足要求. 2. ...
- 大数据IDEA调试flink程序
Flink在IDEA中开发是一件比较困难的事情,网上没有参考资料,就算就业说的太过笼统,不知道是会了不说还是不会瞎说,为了解决flink这个问题,本人特别做了一遍开发的简单说明.主要考虑两个问题,1. ...
随机推荐
- adb常用命令和抓取log的方法
一 adb常用的几个命令1. 查看设备adb devices这个命令是查看当前连接的设备, 连接到计算机的android设备或者模拟器将会列出显示 C:\Documents and Settings\ ...
- MyBatis逆向工程无效
在Taget目录下修改的东西无法逆向, 在源代码目录就可以
- Aliyun-Centos 7 LNMP安装(最新版LNMP)
linux装软件方式:1.源码安装:下载wget-->解压tar -zxvf -->配置 ./configure --->编译make -->安装 make install 2 ...
- CSRF Failed: CSRF token missing or incorrect
Django设置本身没有关闭CSRF Django设置已经关闭CSRF,可能是由于两个项目都使用同一个端口,调试的时候就会出现Cookie里面csrftoken重用的问题,清理Cookie就好
- PBOC第八部分和第十一部分关于TYPEA总结(一)——初始化和防冲突(ISO14443-3)
PBOC第八部分和第十一部分关于TYPEA总结(一) ——初始化和防冲突(ISO14443-3) 第八部分 与应用无关的非接触式规范 ISO14443(1~4) 第十一部分 非接触式IC卡通讯规范 在 ...
- idea无法使用注解@Data解决方法
@Data相关依赖 <dependency> <groupId>org.projectlombok</groupId> <artifactId>lomb ...
- vue中获取滚动table的可视页面宽度,调整表头与列对齐(每列宽度不都相同)
mounted() { // 在mounted中监听表格scroll事件 this.$refs.scrollTable.addEventListener( 'scroll',(event) => ...
- GROUP BY关键字优化
1.group by实质是先排序后进行分组,遵照索引建的最佳左前缀 2.当无法使用索引列,增大max_length_for_sort_data参数的设置+增大sort_buffer_size参数的设置 ...
- Spring基础18——通过注解配置bean之间的关联关系
1.组件装配 <context:component-scan>元素还会自动注册AutowiredAnnotaionBeanPostProcessor实例,这是一个bean的后置处理器,该实 ...
- Nginx 服务器配置
include:实现对配置文件所包含的文件设定 default_type:默认类型二进制流,当文件类型未定义使用这种方式,用浏览器访问 PHP 文件会出现 下载窗口 log_format:指定日志输出 ...