大数据笔记(八)——Mapreduce的高级特性(A)
一.序列化
类似于Java的序列化:将对象——>文件
如果一个类实现了Serializable接口,这个类的对象就可以输出为文件
同理,如果一个类实现了的Hadoop的序列化机制(接口:Writable),这个类的对象就可以作为输入和输出的值
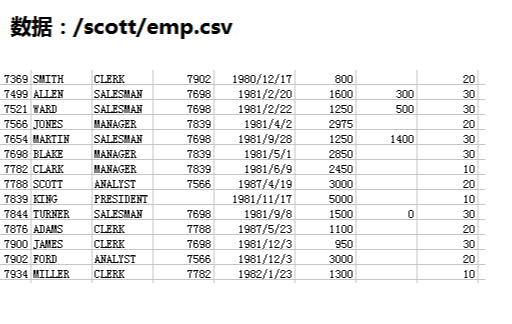
例子:使用序列化 求每个部门的工资总额
数据:在map阶段输出k2部门号 v2是Employee对象
reduce阶段:k4部门号 v3.getSal()得到薪水求和——>v4
Employee.java:封装的员工属性
package saltotal; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable; //定义员工的属性: 7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
public class Employee implements Writable{ private int empno;//员工号
private String ename;//员工姓名
private String job;//ְ职位
private int mgr;//经理的员工号
private String hiredate;//入职日期
private int sal;//月薪
private int comm;//奖金
private int deptno;// 部门号 @Override
public String toString() {
return "["+this.empno+"\t"+this.ename+"\t"+this.sal+"\t"+this.deptno+"]";
} @Override
public void write(DataOutput output) throws IOException {
// 代表序列化过程:输出
output.writeInt(this.empno);
output.writeUTF(this.ename);
output.writeUTF(this.job);
output.writeInt(this.mgr);
output.writeUTF(this.hiredate);
output.writeInt(this.sal);
output.writeInt(this.comm);
output.writeInt(this.deptno);
} @Override
public void readFields(DataInput input) throws IOException {
// 代表反序列化:输入
//注意:序列化和反序列化的顺序要一致
this.empno = input.readInt();
this.ename = input.readUTF();
this.job = input.readUTF();
this.mgr = input.readInt();
this.hiredate = input.readUTF();
this.sal = input.readInt();
this.comm = input.readInt();
this.deptno = input.readInt();
} public int getEmpno() {
return empno;
}
public void setEmpno(int empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public int getMgr() {
return mgr;
}
public void setMgr(int mgr) {
this.mgr = mgr;
}
public String getHiredate() {
return hiredate;
}
public void setHiredate(String hiredate) {
this.hiredate = hiredate;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public int getComm() {
return comm;
}
public void setComm(int comm) {
this.comm = comm;
}
public int getDeptno() {
return deptno;
}
public void setDeptno(int deptno) {
this.deptno = deptno;
} }
EmployeeMapper.java
package saltotal; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import saltotal.Employee;
//k2 部门号 v2 员工对象
public class SalaryTotalMapper extends Mapper<LongWritable, Text, IntWritable, Employee>{ @Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
// 数据:MARTIN,SALEsMAN,7698,1981/9/28,1250,1400,30
String data = v1.toString(); //分词
String[] words = data.split(","); //创建员工的对象
Employee e = new Employee(); //设置员工号
e.setEmpno(Integer.parseInt(words[0]));
//姓名
e.setEname(words[1]); //职位
e.setJob(words[2]); //经理号:有些没有
try{
e.setMgr(Integer.parseInt(words[3]));
}catch(Exception ex){
//空值设0
e.setMgr(0);
} //入职日期
e.setHiredate(words[4]); //月薪
e.setSal(Integer.parseInt(words[5])); //奖金:有的没有
try{
e.setComm(Integer.parseInt(words[6]));
}catch(Exception ex){
e.setComm(0);
} //部门
e.setDeptno(Integer.parseInt(words[7])); //输出 部门号 员工对象
context.write(new IntWritable(e.getDeptno()), e);
} }
SalaryTotalReducer.java
package saltotal; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import saltotal.Employee;
// k3 部门号 v3员工对象 k4部门号 v4 工资总额
public class SalaryTotalReducer extends Reducer<IntWritable, Employee, IntWritable, IntWritable>{ @Override
protected void reduce(IntWritable k3, Iterable<Employee> v3,Context context)
throws IOException, InterruptedException {
//对v3求和
int total = 0;
for (Employee e : v3) {
total = total + e.getSal();
} //输出
context.write(k3, new IntWritable(total));
} }
SalaryTotalMain.java
package saltotal; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class SalaryTotalMain {
public static void main(String[] args) throws Exception {
//创建一个job = map + reduce
Job job = Job.getInstance(new Configuration());
//ָ指定任务的入口
job.setJarByClass(SalaryTotalMain.class); //ָ指定任务的Mapper和输出的数据类型k2 v2
job.setMapperClass(SalaryTotalMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Employee.class); //ָ指定任务的Reducer和输出的数据类型k4 v4
job.setReducerClass(SalaryTotalReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class); //ָ指定输入输出的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); //执行任务
job.waitForCompletion(true);
}
}
输出jar文件,传到Linux上temp文件夹下,然后执行任务:
hadoop jar temp/s3.jar /scott/emp.csv /output/day0301/s3

二.排序
1.数字的排序
默认:按照key2进行升序排序
现在HDFS上有一个文件,里面的数据如下:

开发MapReduce程序进行排序:
NumberMapper.java
package mr.number; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class NumberMapper extends Mapper<LongWritable, Text, LongWritable, NullWritable>{ @Override
protected void map(LongWritable key1, Text value1, Context context)
throws IOException, InterruptedException {
//数字:10
String data = value1.toString().trim(); //输出:把数字作为k2
context.write(new LongWritable(Long.parseLong(data)), NullWritable.get());
}
}
NumberMain.java
package mr.number; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class NumberMain { public static void main(String[] args) throws Exception {
// 创建一个job = map + reduce
Job job = Job.getInstance(new Configuration());
//ָ指定任务入口
job.setJarByClass(NumberMain.class); //ָ指定mapper和输出的数据类型:k2 v2
job.setMapperClass(NumberMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(NullWritable.class); //job.setSortComparatorClass(MyNumberComparator.class); //ָ指定输入和输出的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); //执行任务
job.waitForCompletion(true);
} }
执行任务后看到结果:
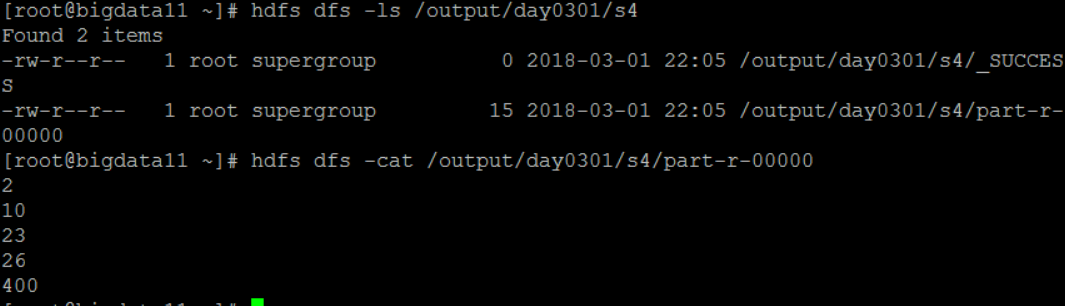
如果要改变默认的排序规则,需要创建一个自己的比较器
定义一个降序比较器类 MyNumberComparator.java
package mr.number; import org.apache.hadoop.io.LongWritable; //自己定义的比较器
public class MyNumberComparator extends LongWritable.Comparator{ @Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
// 使用降序排序
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
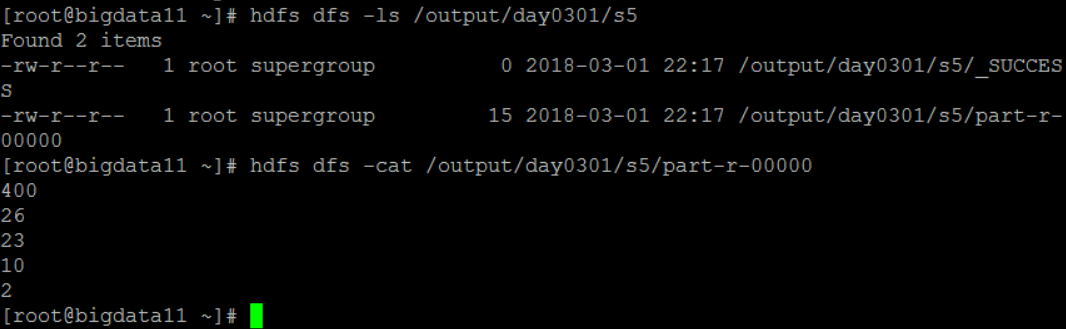
将NumberMain.java的这句话放开:
job.setSortComparatorClass(MyNumberComparator.class);
然后重新打包执行任务之后可看到如下结果:
大数据笔记(八)——Mapreduce的高级特性(A)的更多相关文章
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- 大数据篇:MapReduce
MapReduce MapReduce是什么? MapReduce源自于Google发表于2004年12月的MapReduce论文,是面向大数据并行处理的计算模型.框架和平台,而Hadoop MapR ...
- 大数据笔记(二十六)——Scala语言的高级特性
===================== Scala语言的高级特性 ========================一.Scala的集合 1.可变集合mutable 不可变集合immutable / ...
- 《OD大数据实战》MapReduce实战
一.github使用手册 1. 我也用github(2)——关联本地工程到github 2. Git错误non-fast-forward后的冲突解决 3. Git中从远程的分支获取最新的版本到本地 4 ...
- 大数据笔记01:大数据之Hadoop简介
1. 背景 随着大数据时代来临,人们发现数据越来越多.但是如何对大数据进行存储与分析呢? 单机PC存储和分析数据存在很多瓶颈,包括存储容量.读写速率.计算效率等等,这些单机PC无法满足要求. 2. ...
- 【大数据系列】MapReduce详解
MapReduce是hadoop中的一个计算框架,用来处理大数据.所谓大数据处理,即以价值为导向,对大数据加工,挖掘和优化等各种处理. MapReduce擅长处理大数据,这是由MapReduce的设计 ...
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 大数据【八】Flume部署
如果说大数据中分布式收集日志用的是什么,你完全可以回答Flume!(面试小心问到哦) 首先说一个复制本服务器文件到目标服务器上,需要目标服务器的ip和密码: 命令: scp filename i ...
- 大数据笔记(一)——Hadoop的起源与背景知识
一.大数据的5个特征(IBM提出): Volume(大量) Velocity(高速) Variety(多样) Value(价值) Varacity(真实性) 二.OLTP与OLAP 1.OLTP:联机 ...
随机推荐
- [Web 前端] 022 js 的基本数据类型及使用
1. Javascript 基本数据类型 1.1 分类 类型 释义 boolean 布尔类型,分 true 与 false number 整型,浮点型 string 字符类型 object 对象类型 ...
- 全新一台node节点加入到集群中
目录 前言 对新节点做解析 方法一 hosts 文件解析 方法二 bind 解析 测试 分发密钥对 推送 CA 证书 flanneld 部署 推送flanneld二进制命令 推送flanneld秘钥 ...
- PhoneGap学习网址
官网:http://app-framework-software.intel.com/ 下载地址:http://download.csdn.net/download/haozq2012/7635951
- spring @Value 获取配置文件为 null 常见的几种方式
第一种方式: xx.properties 属性名称错误,未与@Value("${xxx}") 进行对应 第二种方式: 该类未注入到spring bean容器中 @Component ...
- qt undefined reference to `vtable for subClass'
1. 建立一个console工程 QT -= gui CONFIG += c++ console CONFIG -= app_bundle # The following define makes y ...
- Luogu P4562 [JXOI2018]游戏
题目 我们用埃氏筛从\(l,r\)筛一遍,每次把没有被筛掉的数的倍数筛掉. 易知最后剩下来的数(这个集合记为\(S\))的个数就是我们需要选的数,设有\(s\)个,令\(n=r-l+1\). 记\(f ...
- Django @csrf_exempt不能在类视图中工作(Django @csrf_exempt not working in class View)
我在Django 1.9中有一个使用SessionMiddleware的应用程序.我想在同一个项目中为这个应用程序创建一个API,但是在做一个POST请求时,它不能使用@csrf_exempt注释. ...
- 模板 - SG函数
https://scut.online/p/93 每次取走的石子是b的幂次.打表暴力发现规律. #include <bits/stdc++.h> using namespace std; ...
- 如何遍历div里面的文本内容,用each方法,
如何遍历div里面的文本内容,然后进行匹配传来的数据,进行选中div,并进行CSS样式处理, for(i = 0; i< $(".itemMenuRowBox").child ...
- Servlet&Http&Request笔记
# 今日内容: 1. Servlet 2. HTTP协议 3. Request ## Servlet: 1. 概念 2. 步骤 3. 执行原理 ...