Spark之命令
Spark之命令
1.spark运行模式有4种:
a.local 多有用测试,
b. standalone:spark 集群模式,使用spark自己的调度方式。
c. Yarn: 对MapreduceV1升级的经典版本,支持spark。
d.Mesos:类似Yarn的资源调度框架,提供了有效的、跨分布式应用或框架的资源隔离和共享,可以运行hadoop、spark等框架
2.spark local 模式(shell )
Spark local模式(shell运行)
windows:
执行spark-shell.cmd Linux:
执行spark-shell 参数指定: • MASTER=local[4] ADD_JARS=code.jar ./spark-shell • MASTER=spark://host:port • 指定executor内存:export SPARK_MEM=25g
3. spark standalone 模式
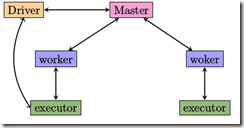
Spark standalone加载数据(shell运行spark-shell)
读取本地文件:
var file = sc.textFile("/root/test.txt").collect
加载远程hdfs文件:
var files = sc.textFile("hdfs://192.168.2.2:8020/user/superman").collect
(读取hdfs数据时使用的还是inputFormat)
standalone WordCount
sc.textFile("/root/test.txt").flatMap(_.split("\\t")).map(x=>(x,1)).reduceByKey(_+_).collect
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
Spark standalone保存结果集数据
保存数据到本地:
result.saveAsTextFile("/root/tmp") (tmp文件夹必须不存在)
保存数据到远程hdfs文件:
result.saveAsTextFile("hdfs://192.168.122.212:8020/user/superman/tmp")
(tmp文件夹必须不存在)
设置输出结果集文件数量:
result.repartition(1).saveAsTextFile
任务提交
spark-submit (推荐)
其它也可⾏,如sbt run, java -jar 等等
提交:spark on standalone spark-submit --class SsdTest /zzy/original-spark2-1.0-SNAPSHOT.jar hdfs://hadoop13:9000/hello hdfs://hadoop13:9000/out1.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
Spark on YARN
需要配置hadoop_conf_dir,hadoop_home
任务提交:
(standalone)spark-submit --class SsdTest /zzy/original-spark2-1.0-SNAPSHOT.jar hdfs://hadoop13:9000/hello hdfs://hadoop13:9000/out1.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
命令格式:
spark –submit –class path.your.class --master yarn-cluster [options] <app jar> [app options] spark-submit --class you.jar /
--master yarn-cluster\
--driver-memory 4g\
--executor-memory 2g\
--executor -cores 1\
lib\spark-examples*.jar\
10提交:on yarn
spark-submit --class classname inputyour.jar input your.text outpath spark-submit --class SaprkOnYarn original-spark2-1.0-SNAPSHOT.jar /hello out2(hadop默认是/usr/root文件夹).csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
4.RDD,可恢复分布式数据集,弹性分布式数据集
5.spark 对比mapreduce优势的总结
spark具有所有优点,并不是依靠一个人或者是一个团队的力量,而是站在巨人的肩膀上
1.依靠scala强有力的函数式变成
2.actor通信模式,akka做底层架构
3.MR架构思想
4.数据共享快,省去了mapreduce的shuffle过程中至少三次存入磁盘所带来的额外开销
5.spark的DAG(执行过程首先省城一张有向无环图)做的好,越靠近编译器,就性能越好,优化也更好。
6.任务使用线程启动并执行,比mapreduce使用进程执行任务要有很大优势
7.delay scheduling ---延迟执行
6.Spark Streaming
流失系统的特点:
1.低延迟。
2.高性能
3.分布式
4.可扩展。伴随着业务的发展,我们的数据量、计算量可能会越来越大,所以系统是可扩展的。
5.容错。这是分布式系统中通用问题。一个节点挂了不能影响应用。
对比storm
1.同一套系统,安装spark之后就一切都有了
2.spark 较强的容错能力,storm 使用较广,更稳定
3.storm是用Clojure语言去写的,它的很多扩展都是用java去写的
4.任务执行方面和storm 的区别是:
i.spark streaming 数据进来是一小段时间的RDD,数据进来之后切成一小块一小块进行处理
ii.storms是基于record形式来的,进来的是一个tuple,一条进来就处理一下
5.中间过程实质上就是spark引擎,只不过sparkstreaming 在spark之后引擎之上动了一点手脚:对进入spark引擎之前的数据进行了一个封装,方便进行基于时间片的小批量作业,交给spark 进行计算。
Spark之命令的更多相关文章
- spark提交命令 spark-submit 的参数 executor-memory、executor-cores、num-executors、spark.default.parallelism分析
转载:https://blog.csdn.net/zimiao552147572/article/details/96482120 nohup spark-submit --master yarn - ...
- spark执行命令 监控执行命令
#!/bin/bash #/usr/hdp/current/flume-server/bin/flume-ng agent -c conf/ -f /usr/hdp/current/flume-ser ...
- python操作Spark常用命令
1. 获取SparkSession spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate() 2. 获取SparkCo ...
- Spark运行命令示例
local单机模式:结果xshell可见:./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[1] ...
- 集群提交spark任务命令
>>spark-submit --class WordCount DataMining.jar /dept_ana/part-00000 /dept_ana/output/wordCou ...
- spark 编译命令
mvn -Pyarn -Phadoop-2.4 -Dhadoop.version=2.4.0 -DskipTests clean package
- spark集群的简单测试和基础命令的使用
写此篇文章之前,已经搭建好spark集群并测试成功: spark集群搭建文章链接:http://www.cnblogs.com/mmzs/p/8193707.html 一.启动环境 由于每次都要启动, ...
- Ubuntu 14.04 LTS 安装 spark 1.6.0 (伪分布式)-26号开始
需要下载的软件: 1.hadoop-2.6.4.tar.gz 下载网址:http://hadoop.apache.org/releases.html 2.scala-2.11.7.tgz 下载网址:h ...
- 《深入理解Spark:核心思想与源码分析》(前言及第1章)
自己牺牲了7个月的周末和下班空闲时间,通过研究Spark源码和原理,总结整理的<深入理解Spark:核心思想与源码分析>一书现在已经正式出版上市,目前亚马逊.京东.当当.天猫等网站均有销售 ...
随机推荐
- photoshop切图介绍
第一部分:界面设置 1.点击“文件-新建”(或者ctrl+n)打开一个新建对话框.名称可随意填写.“预设”设置为自定,“宽度”一般选择1920,“单位”选为像素.“高度”可选择为2000,“单位”选为 ...
- cobbler工作流分析
官网 http://cobbler.github.io/ 介绍 Cobbler是一个快速网络安装linux的服务,而且在经过调整也可以支持网络安装windows.该工具使用python开发,小巧轻便, ...
- edmx代码分析
http://www.cnblogs.com/FoundationSoft/archive/2011/01/08/1930479.html 本文分析Entity Framework从数据库自动生成的模 ...
- OC之NSString、NSMutableString学习笔记 常用方法
NSString篇: 1.字符串连接 NSString *beijing = @"北京"; NSString *welcome = [beijing stringByAppendi ...
- redis常用配置
daemonize yes #是否以后台进程运行,默认为no pidfile /var/run/redis.pid #如以后台进程运行,则需指定一个pid,默认为/var/run/redis.pid ...
- SVM支持向量机的高维映射与核函数-记录毕业论文2
上一篇博客将了在数据集线性可分的情况下的支持向量机,这篇主要记录如何通过映射到高维解决线性不可分的数据集和如何通过核函数减少内积计算量的理论思想. [5]径向基函数的核函数:https://www.q ...
- WinForm------TreeList加载数据方法
1.SQLService操作 (1)在SQLServer创建一张表dbo.Department (2)写入以下数据 2.VS操作(这里如何使用EntityFramework加载数据库就不多说了哈) ( ...
- lua 闭包
--匿名函数使用upvalue i保存他的计数, 闭包是一个函数加上它可以正确访问的upvalues function newCounter() return function() i = i + r ...
- Markdown常用用法
很早之前就听过Markdown,一直没用,用过才发现,原来这么好用,迷人,就好比一位知性.大方.成熟.美丽的少妇一样深深吸引着我,特深夜把学习的笔记记录下. 引用 ">"最好 ...
- Robot Framework--07 变量的声明、赋值及其使用
转自:http://blog.csdn.net/tulituqi/article/details/7984642 一.变量的声明 1.变量标识符 每个变量都可以用 变量标识符{变量名} 来进行 ...