论文阅读笔记三十二:YOLOv3: An Incremental Improvement

论文源址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
代码:https://github.com/qqwweee/keras-yolo3
摘要
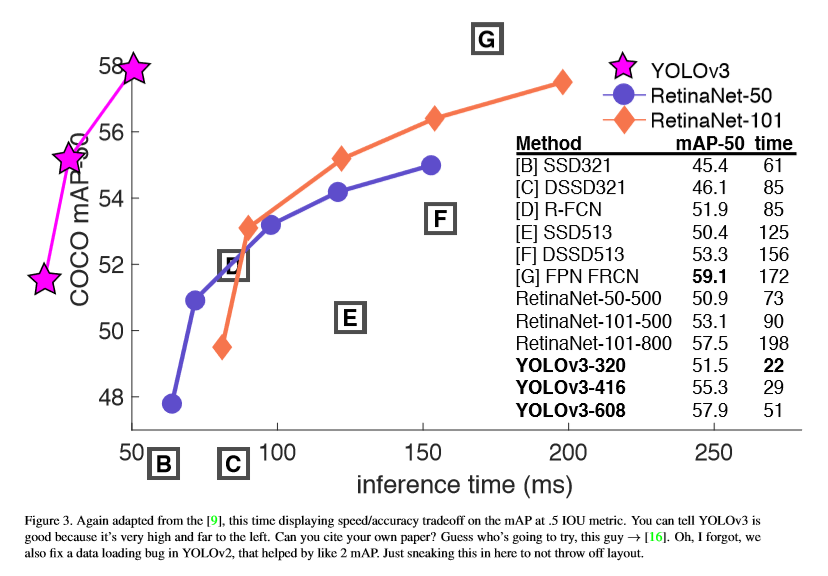
本文针对YOLO再次改进,训练更大的网络,准确率也有所提高。在320x320的输入上YOLOv3运行22ms,mAP为28.2,与SSD的准确率相同,但比SSD快三倍。在使用0.5 IOU作为检测机制时,YOLOv3仍表现很好。在Titan X上实现57.9 AP50 51ms的运行,而RetinamNet为57.5 AP50运行198ms,YOLOv3要快3.8倍。
The Deal
bounding box 的预测:沿袭YOLO9000的方式,仍采用维度聚合的方式。网络预测每个bounding box的四个坐标,tx,ty,tw,th。如果单元格偏离图像左上角(cx,cy),而且先验框的宽和高为pw,ph,这预测的值为:

训练时,选择平方误差损失的和,预测坐标对应的真值为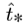 ,梯度计算是真值减去预测值,
,梯度计算是真值减去预测值,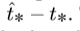 通过翻转上述式子,可以得到真值的值。YOLOv3通过使用逻辑回归预测每个bounding box的目标分数。如果一个先验框与ground truth 的重合率要比其他先验框都要多,则该框的目标分数应为1.对于与ground truth中目标有重叠超过阈值(本为设置为0.5),但不是最好的先验框,将此预测进行移除。如果一个先验框没有一个ground truth与之匹配。则没有类别和坐标的预测损失。只有是否存在目标的损失描述。
通过翻转上述式子,可以得到真值的值。YOLOv3通过使用逻辑回归预测每个bounding box的目标分数。如果一个先验框与ground truth 的重合率要比其他先验框都要多,则该框的目标分数应为1.对于与ground truth中目标有重叠超过阈值(本为设置为0.5),但不是最好的先验框,将此预测进行移除。如果一个先验框没有一个ground truth与之匹配。则没有类别和坐标的预测损失。只有是否存在目标的损失描述。

类别预测:使用多类别的分类器对每个框内可能包含的类别进行预测分类。YOLOv3并未使用softmax,只是使用独立的逻辑回归分类器。训练时,采用二元交叉熵损失进行类别的预测。当面向更复杂的情况时(开放的数据集,此数据集中存在大量重叠的标签),此方法会有所帮助,而使用softmax基于每个box只包含一个类别的假设,并不实用,而使用多标记的方法可以更好的描述数据。
不同尺寸的预测: YOLOv3预测三种不同的尺寸。YOLOv3采用类似于FPN网络类似的结构提取多尺寸特征。在基础的特征提取层后添加了基层卷积层。最后预测了一个三维张量,编码bounding box,objectness和类别的预测。COCO中每种尺寸预测三个框,因此张量为NXNX[3*(4+1+80)],分别代表4个坐标,1个objectness及80个类别的预测。取前两层的feature map将其上采样扩大至2倍,然后将采样后的feature map与更靠前的feature map进行拼接。通过上采样可以获得更多的语义信息,提取靠前层的feature map可以获得图像的细节信息。最后,添加一些卷积层来处理拼接后的feature map,并对此张量进行预测,当前的尺寸扩大。重复此方法,对最后一种尺寸进行预测。第三种储存预测的结果结合了先前的计算(相当于微调后的feature map)。
仍采用k-means剧烈确定先验框,任意选择9个簇及3种尺寸。在COCO数据集上得到的9个先验框为(10×13),(16×30),(33×23),(30×61),(62×45),(59× 119),(116×90),(156×198),(373×326).
特征提取:使用全新的网络进行特征提取。基于YOLOv2的网络将,Darknet19与残差结构进行结合。包含一系列的3x3与1x1的卷积夹杂着残差连接,网络规模变大,叫做Darknet-53。
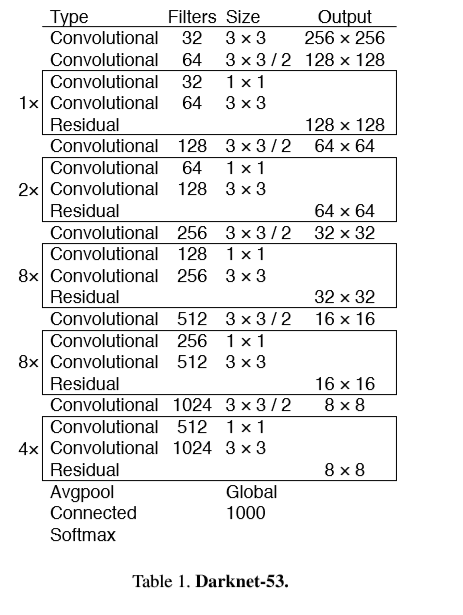
Darknet-53比Darknet-19高效,同时,比resnet-101,resnet-152更快。比较结果如下。
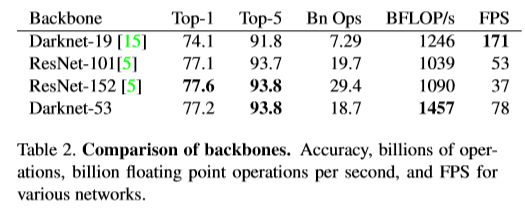
实验比较

实验失效的方案:
(1)Anchor box x,y offset predictions
(2)Linear x,y predictions instead of logistic.
(3)Focal loss.
(4)DualIOUthresholdsandtruthassignment.
Reference
[1] Analogy. Wikipedia, Mar 2018. 1
[2] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2):303– 338, 2010. 6
[3] C.-Y. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg. Dssd: Deconvolutional single shot detector. arXiv preprint arXiv:1701.06659, 2017. 3
[4] D. Gordon, A. Kembhavi, M. Rastegari, J. Redmon, D. Fox, andA.Farhadi. Iqa: Visualquestionansweringininteractive environments. arXiv preprint arXiv:1712.03316, 2017. 1
论文阅读笔记三十二:YOLOv3: An Incremental Improvement的更多相关文章
- 论文阅读笔记(十二)【CVPR2018】:Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning
Introduction (1)Motivation: 大量标记数据成本过高,采用半监督的方式只标注一部分的行人,且采用单样本学习,每个行人只标注一个数据. (2)Method: 对没有标记的数据生成 ...
- 论文阅读笔记五十二:CornerNet-Lite: Efficient Keypoint Based Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.08900.pdf github:https://github.com/princeton-vl/CornerNet-Lite 摘要 基 ...
- 论文阅读笔记三十六:Mask R-CNN(CVPR2017)
论文源址:https://arxiv.org/pdf/1703.06870.pdf 开源代码:https://github.com/matterport/Mask_RCNN 摘要 Mask R-CNN ...
- 论文阅读笔记三十:One pixel attack for fooling deep neural networks(CVPR2017)
论文源址:https://arxiv.org/abs/1710.08864 tensorflow代码: https://github.com/Hyperparticle/one-pixel-attac ...
- 论文阅读笔记四十二:Going deeper with convolutions (Inception V1 CVPR2014 )
论文原址:https://arxiv.org/pdf/1409.4842.pdf 代码连接:https://github.com/titu1994/Inception-v4(包含v1,v2,v4) ...
- 论文阅读笔记三十九:Accurate Single Stage Detector Using Recurrent Rolling Convolution(RRC CVPR2017)
论文源址:https://arxiv.org/abs/1704.05776 开源代码:https://github.com/xiaohaoChen/rrc_detection 摘要 大多数目标检测及定 ...
- 论文阅读笔记三十八:Deformable Convolutional Networks(ECCV2017)
论文源址:https://arxiv.org/abs/1703.06211 开源项目:https://github.com/msracver/Deformable-ConvNets 摘要 卷积神经网络 ...
- 论文阅读笔记三十五:R-FCN:Object Detection via Region-based Fully Convolutional Networks(CVPR2016)
论文源址:https://arxiv.org/abs/1605.06409 开源代码:https://github.com/PureDiors/pytorch_RFCN 摘要 提出了基于区域的全卷积网 ...
- 论文阅读笔记三十四:DSSD: Deconvolutiona lSingle Shot Detector(CVPR2017)
论文源址:https://arxiv.org/abs/1701.06659 开源代码:https://github.com/MTCloudVision/mxnet-dssd 摘要 DSSD主要是向目标 ...
随机推荐
- 【Math for ML】矩阵分解(Matrix Decompositions) (下)
[Math for ML]矩阵分解(Matrix Decompositions) (上) I. 奇异值分解(Singular Value Decomposition) 1. 定义 Singular V ...
- python基础-----列表操作
在Python中用[]来表示列表,并用逗号隔开其中的元素. 1.访问列表元素 name=["zhangsan","lisi","ljy"] ...
- 测试cpu的简单工具-dhrystone【转】
转自:https://blog.csdn.net/feixiaoxing/article/details/9005587 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog ...
- Kafka管理工具介绍【转】
Kafka内部提供了许多管理脚本,这些脚本都放在$KAFKA_HOME/bin目录下,而这些类的实现都是放在源码的kafka/core/src/main/scala/kafka/tools/路径下. ...
- Git学习笔记04-管理修改
Git跟踪并管理的是修改,而非文件.新增文件,修改一行,删除一点,都算是修改. 在.git工作区新增一个文件,test.txt,输入test git ...然后git add add之后修改t ...
- dmp文件的导入导出
一.dmp文件的导入 方法一(需安装PLSQL) 1.运行PLSQL,在oracle登陆窗口输入用户名和密码登陆到数据库 2.运行工具>导入表,弹出导入对话框 3.单击下方选择文件按钮,在弹出对 ...
- linux批量替换文件内容3种方法(perl,sed,shell)
方法1:perl 这两天在构建一个应用的使用用到了maven,由于project很大,足足有700多个 pom.xml文件,更郁闷的是在很多pom.xml文件里都单独指定了资源库的url,我需要把 ...
- web-font 个人学习小总结
个人觉得 web-font 分为两种: 第一种就是真正文本字体,客户端没有安装的字体通过远程加载字体来实现特殊字体提高用户体验: icodon.com : http://icodon.com/goo ...
- python操作三大主流数据库(3)python操作mysql③python操作mysql的orm工具sqlaichemy安装配置和使用
python操作mysql③python操作mysql的orm工具sqlaichemy安装配置和使用 手册地址: http://docs.sqlalchemy.org/en/rel_1_1/orm/i ...
- Git系列②之部署企业级开源仓库gitlab服务器
Git系列②之部署企业级开源仓库gitlab服务器 上一篇我们介绍了github的常见使用方法,下面开始部署本地开源仓库gitlab GitLab 是一个用于仓库管理系统的开源项目. 1.安装配置gi ...