论文阅读笔记(十二)【CVPR2018】:Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning
Introduction
(1)Motivation:
大量标记数据成本过高,采用半监督的方式只标注一部分的行人,且采用单样本学习,每个行人只标注一个数据。
(2)Method:
对没有标记的数据生成一个伪标签(pseudo labels),将标记的数据和部分伪标签的数据作为扩充数据集进行训练。
但这种方法引入了很多不可信的训练样本,制约了训练模型的性能。
(3)Contribution:
① 为了在单样本学习中更好的利用未标签数据,提出了步进学习方法EUG(Exploit the Unknown Gradually)。介绍如下:
通过单样本数据集训练CNN模型;
EUG迭代更新CNN模型,分为两步:
标签估计:对未标记数据生成伪标签,根据预测的可信度选择伪标签数据训练,
模型更新:使用扩充数据集对CNN重新训练。
② 采用基于距离的抽样准则进行标签估计和样本选择,显著提高了标签估计的性能。

The Progressive Model
(1)预备工作:
符号定义:
标记数据:L = {(x1, y1), ..., (xnl, ynl)}, |L| = nl
未标记数据:U = {(xnl+1), ..., (xnl+nu)}, |U| = nu
训练标记数据集的目标函数:
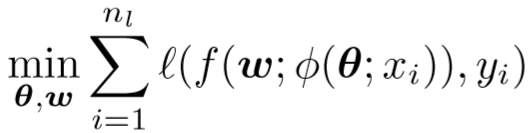
其中, Φ 表示一个嵌入函数,含有参数 θ,表示提取数据 xi 的特征(可视为CNN);
f 是一个含有参数 w 的函数,用于将 Φ 函数提取出的特征分类为 k 维的置信度估计(k表示行人的数量);
l 表示损失函数。
将未标记的数据考虑在内,单样本学习目标函数转为:
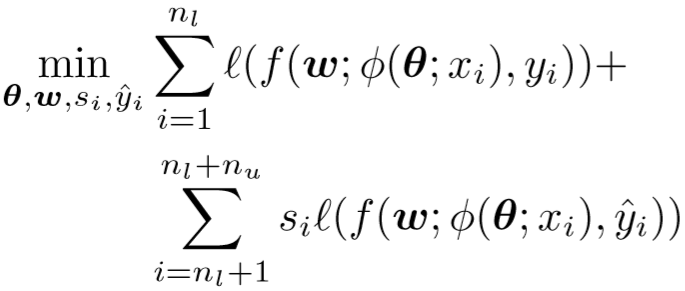
其中,yi^ 表示生成伪标签的第 i 个未标记数据;
si 属于 {0, 1},用于选择放进训练的未标记数据。
(2)框架:
提出一个步进学习方法来解决优化问题,即先优化 θ 和 w,再优化 y^ 和 s。
定义 S 为选择的伪标签的集合: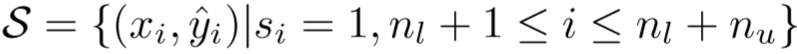
特征提取函数 Φ 采用一个带有时间平均池化的CNN模型ETAP-Net,该网络基于ResNet-50的架构,在分类层之前添加了全连接层和时间平均池化层。通过时间平均池化,每个tracklet包含的多个帧级特征转为tracklet级特征。在标签估计阶段,每个未标记的视频tracklet都会计算与已标记tracklet的距离,并将最近的数据进行伪标记。

(3)渐进式高效抽样策略:
① 抽样策略:如何保证抽选的伪标签样本的可靠性?
作者提出了一个动态的抽样策略,逐渐增加选择的伪标签样本数量。
② 抽样标准:对于单样本训练的行人重识别问题,什么才是一个高效的抽样标准?
作者提出了一个高效的抽样标准,采用了特征空间的距离度量(最近邻)来衡量可靠性。
具体策略如下:
对于每一个未标记数据,定义不相似度代价函数,其中 xi 属于 U:
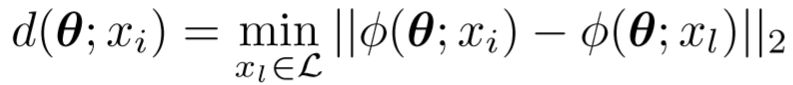
设置第 t 次迭代的伪标签索引:
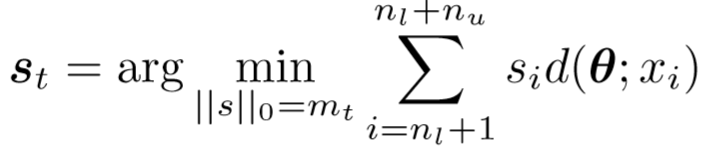
其中 mt 表示选择的伪标签集合的大小,迭代定义为:mt = mt-1 + p*nu,p为增量因子,属于(0, 1),控制伪标签集合的增长速度。
如何确定增量因子 p ?将 p 设置为一个很小的数值,使得 mt 在迭代中逐渐增大。
算法流程:

Experiments
(1)实验设置:
① 数据集:MARS和DukeMTMC
② 参数设置:momentum = 0.5,weight decay = 0.0005, batch size = 16, epochs = 70,lr = 0.1(前55个epochs),lr = 0.01(后15个epochs)
③ 数据处理:采用ImageNet进行预训练;每个tracklet选取16帧作为输入。
(2)实验结果:
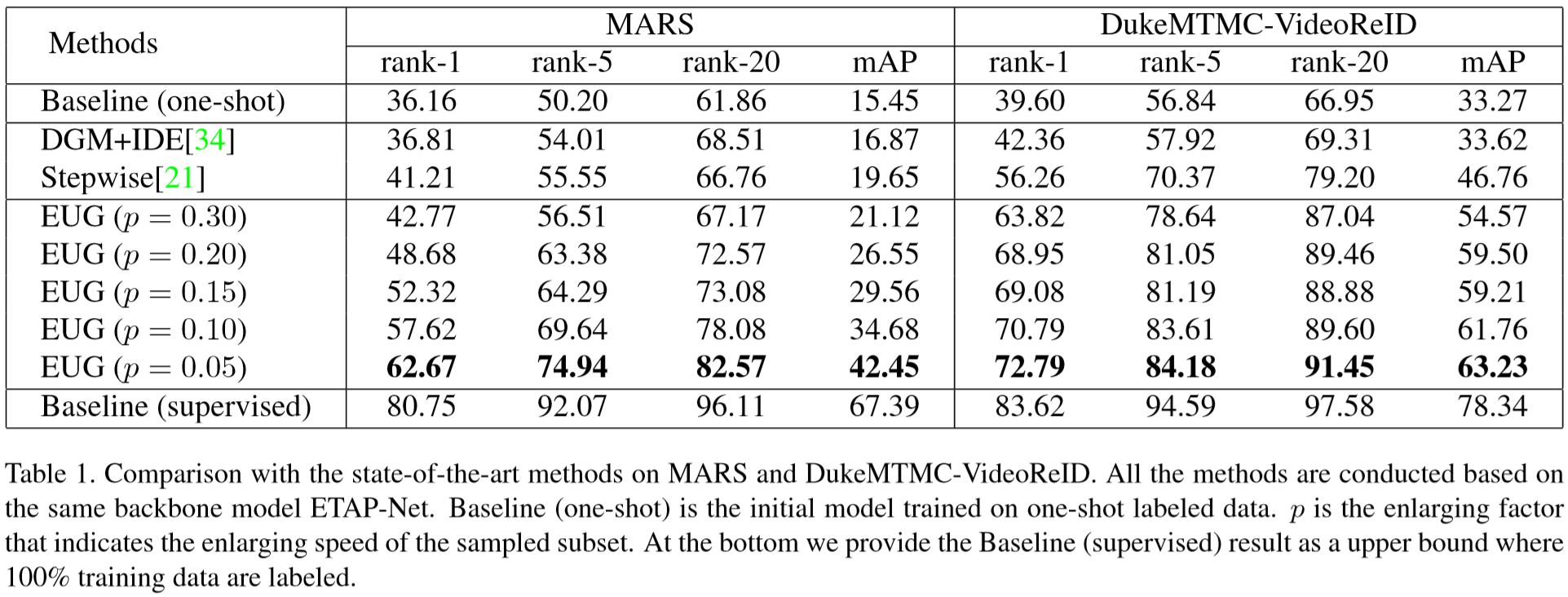

其他读者的阅读笔记【传送门】
论文阅读笔记(十二)【CVPR2018】:Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning的更多相关文章
- 论文阅读笔记十二:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(DeepLabv3+)(CVPR2018)
论文链接:https://arxiv.org/abs/1802.02611 tensorflow 官方实现: https: //github.com/tensorflow/models/tree/ma ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- 论文阅读笔记(二十二)【CVPR2017】:See the Forest for the Trees: Joint Spatial and Temporal Recurrent Neural Networks for Video-based Person Re-identification
Introduction 在视频序列中,有些帧由于被严重遮挡,需要被尽可能的“忽略”掉,因此本文提出了时间注意力模型(temporal attention model,TAM),注重于更有相关性的帧. ...
- 论文阅读笔记(二十)【AAAI2019】:Spatial and Temporal Mutual Promotion for Video-Based Person Re-Identification
Introduction (1)Motivation: 作者考虑到空间上的噪声可以通过时间信息进行弥补,其原因为:不同帧的相同区域可能是相似信息,当一帧的某个区域存在噪声或者缺失,可以用其它帧的相同区 ...
- 论文阅读笔记十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(CVPR2016)
论文源址:https://arxiv.org/abs/1606.02147 tensorflow github: https://github.com/kwotsin/TensorFlow-ENet ...
- 论文阅读笔记十四:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation(CVPR2015)
论文链接:https://arxiv.org/abs/1506.04924 摘要 该文提出了基于混合标签的半监督分割网络.与当前基于区域分类的单任务的分割方法不同,Decoupled 网络将分割与分类 ...
- 【学习笔记】Vins-Mono论文阅读笔记(二)
估计器初始化简述 单目紧耦合VIO是一个高度非线性的系统,需要在一开始就进行准确的初始化估计.通过将IMU预积分与纯视觉结构进行松耦合对齐,我们得到了必要的初始值. 理解:这里初始化是指通过之前imu ...
- 论文阅读笔记十九:PIXEL DECONVOLUTIONAL NETWORKS(CVPR2017)
论文源址:https://arxiv.org/abs/1705.06820 tensorflow(github): https://github.com/HongyangGao/PixelDCN 基于 ...
- 论文阅读笔记十六:DeconvNet:Learning Deconvolution Network for Semantic Segmentation(ICCV2015)
论文源址:https://arxiv.org/abs/1505.04366 tensorflow代码:https://github.com/fabianbormann/Tensorflow-Decon ...
- 论文阅读笔记十五:Pyramid Scene Parsing Network(CVPR2016)
论文源址:https://arxiv.org/pdf/1612.01105.pdf tensorflow代码:https://github.com/hellochick/PSPNet-tensorfl ...
随机推荐
- Rust入坑指南:步步为营
俗话说:"测试写得好,奖金少不了." 有经验的开发人员通常会通过单元测试来保证代码基本逻辑的正确性.如果你是一名新手开发者,并且还没体会到单元测试的好处,那么建议你先读一下我之前的 ...
- pytorch之 bulid_nn_with_2_method
import torch import torch.nn.functional as F # replace following class code with an easy sequential ...
- php 安装扩展插件实例-ftp.so
工作记录一下 1.首先进入原始php包安装文件(不是安装后的文件,是下载php安装压缩包,解压后的那个文件)安装包里有个扩展文件夹ext,进入 #cd /home/php-5.3.3/ext/#l ...
- hexo博客
安装软件 node.js(建议稳定版本,本人安装v8.11.3) npm install -g hexo-cli hexo init myBlog //初始化,在myBlog的文件夹下建立网站 hex ...
- scrapy的useragent与代理ip
scrapy中的useragent与代理ip 方法一: user-agent我们可以直接在settings.py中更改,如下图,这样修改比较简单,但是并不推荐,更推荐的方法是修改使用scrapy的中间 ...
- JS-重写内置的call、apply、bind
首先看call和apply,第一个参数就是改变的this指向,写谁就是谁,如果是非严格模式下,传递null或undefined指向的也是window,二者唯一的区别是执行函数时,传递的参数方式不同,c ...
- 解决H5页面点击一瞬间出现灰色背景的问题
H5页面有时会出现点击一瞬间出现灰色背景的问题(ios会,安卓不会),解决方法: 加上样式: -webkit-tap-highlight-color: transparent; 如果以上方法不行,则是 ...
- 简单了解css3样式表写法和优先级
css3和css有什么区别?首先css3是css(层叠样式表)技术的升级版本,而css是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言. ...
- Android中通过Java代码实现ScrollView滚动视图-以歌词滚动为例
场景 实现效果如下 注: 博客: https://blog.csdn.net/badao_liumang_qizhi 关注公众号 霸道的程序猿 获取编程相关电子书.教程推送与免费下载. 实现 将布局改 ...
- Git安装与配置,以及pycharm提交代码到github
1.下载git,安装 下载好后直接下一步到底,安装成功(选择组件页面,可以勾选上控制台窗口字体选项,如下图) 2.配置Git信息 1.打开窗口中,输入:git --version 查看已安装的git版 ...