VGG网络
VGG论文给出了一个非常振奋人心的结论:卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用。记得在AlexNet论文中,也做了最后指出了网络深度的对最终的分类结果有很大的作用。这篇论文则更加直接的论证了这一结论。
网络结构
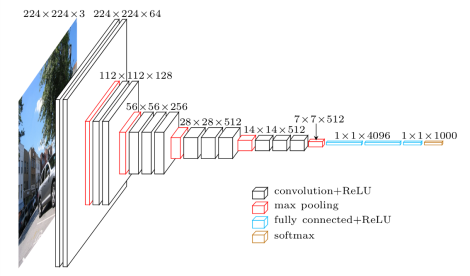
论文指出:
- VGG不仅在ILSVRC的分类和检测任务中取得了the state-of-the-art的精度
- 在其他数据集上也具有很好的推广能力
结构Architecture

说明:
*1x1卷积核:降维,增加非线性性论文中,作者指出,虽然LRN(Local Response Normalisation)在AlexNet对最终结果起到了作用,但在VGG网络中没有效果,并且该操作会增加内存和计算,从而作者在更深的网络结构中,没有使用该操作
*3x3卷积核:多个卷积核叠加,增加空间感受野,减少参数
VGG网络结构
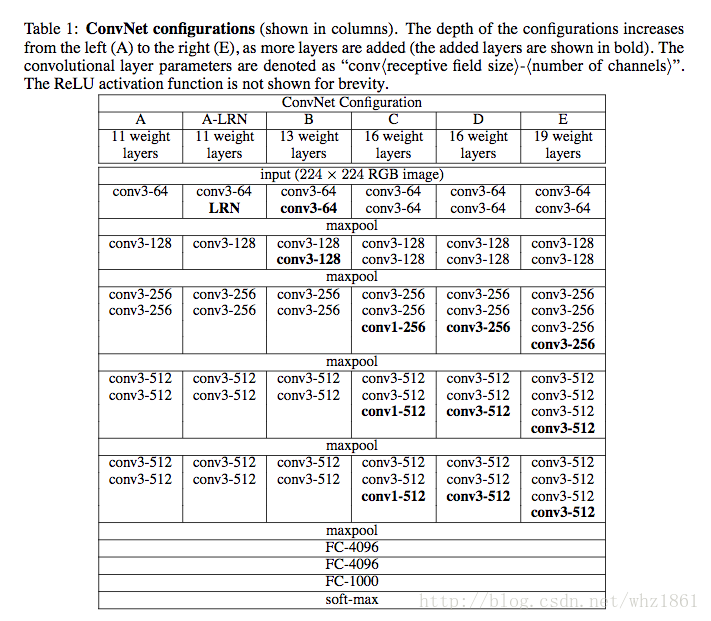
VGG网络参数

Q1: 为什么3个3x3的卷积可以代替7x7的卷积?
3个3x3的卷积,使用了3个非线性激活函数,增加了非线性表达能力,使得分割平面更具有可分性
减少参数个数。对于C个通道的卷积核,7x7含有参数72C272C2, 3个3x3的参数个数为3∗32C23∗32C2,参数大大减少
Q2: 1x1卷积核的作用
- 在不影响感受野的情况下,增加模型的非线性性
- 1x1卷机相当于线性变换,非线性激活函数起到非线性作用
Q3: 网络深度对结果的影响(同年google也独立发布了深度为22层的网络GoogleNet)
VGG与GoogleNet模型都很深
都采用了小卷积
VGG只采用3x3,而GoogleNet采用1x1, 3x3, 5x5,模型更加复杂(模型开始采用了很大的卷积核,来降低后面卷机层的计算)
模型框架
VGG采用了min-batch gradient descent去优化multinomial logistic regression objective
正则化方法:
- 增加了对权重的正则化,5∗10−4||W||L25∗10−4||W||L2
- 对FC全连接层进行dropout正则化,dropout ratio = 0.5
说明:虽然模型的参数和深度相比AlexNetyou 了很大的增加,但是模型的训练迭代次数却要求更少:a)正则化+小卷积核,b)特定层的预初始化
初始化策略:
首先,随机初始化网络结构A(A的深度较浅)
利用A的网络参数,给其他的模型进行初始化(初始化前4层卷积+全连接层,其他的层采用正态分布随机初始化,mean=0,var=10−210−2, biases = 0)最后证明,即使随 机初始化所有的层,模型也能训练的很好
训练输入:
采用随机裁剪的方式,获取固定大小224x224的输入图像。并且采用了随机水平镜像和随机平移图像通道来丰富数据。
Training image size: 令S为图像的最小边,如果最小边S=224S=224,则直接在图像上进行224x224区域随机裁剪,这时相当于裁剪后的图像能够几乎覆盖全部的图像信息;如果最小边S>>224S>>224,那么做完224x224区域随机裁剪后,每张裁剪图,只能覆盖原图的一小部分内容。
注:因为训练数据的输入为224x224,从而图像的最小边S,不应该小于224
数据生成方式:首先对图像进行放缩变换,将图像的最小边缩放到S大小,然后
方法1: 在S=224和S=384的尺度下,对图像进行224x224区域随机裁剪
方法2: 令S随机的在[Smin,Smax][Smin,Smax]区间内值,放缩完图像后,再进行随机裁剪(其中Smin=256,Smax=512Smin=256,Smax=512)
预测方式:作者考虑了两种预测方式:
方法1: multi-crop,即对图像进行多样本的随机裁剪,然后通过网络预测每一个样本的结构,最终对所有结果平均
方法2: densely, 利用FCN的思想,将原图直接送到网络进行预测,将最后的全连接层改为1x1的卷积,这样最后可以得出一个预测的score map,再对结果求平均
上述两种方法分析:
Szegedy et al.在2014年得出multi-crops相对于FCN效果要好
multi-crops相当于对于dense evaluatio的补充,原因在于,两者在边界的处理方式不同:multi-crop相当于padding补充0值,而dense evaluation相当于padding补充了相邻的像素值,并且增大了感受野
multi-crop存在重复计算带来的效率的问题
效果分析
单尺度
效果分析
单尺度
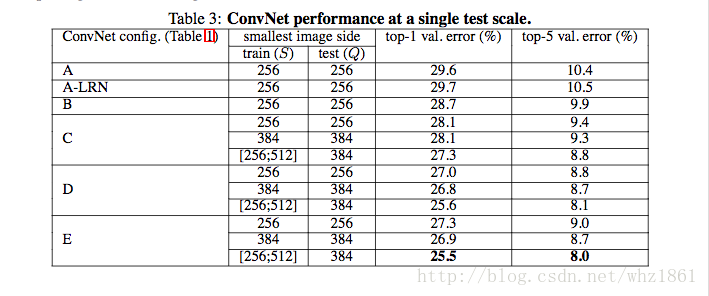
结论:
- 模型E(VGG19)的效果最好,即网络越深,效果越好
- 同一种模型,随机scale jittering的效果好于固定S大小的256,384两种尺度,即scale jittering数据增强能更准确的提取图像多尺度信息
多尺度
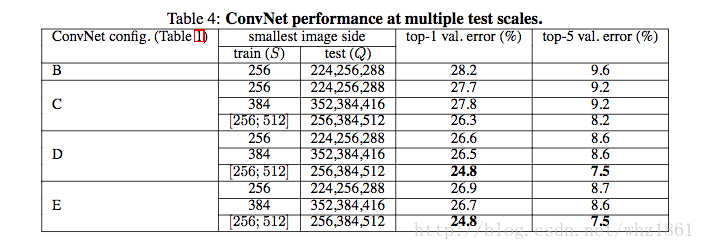
结论:
- 对比单尺度预测,多尺度综合预测,能够提升预测的精度
- 同单尺度预测,多尺度预测也证明了scale jittering的作用
多尺度裁剪
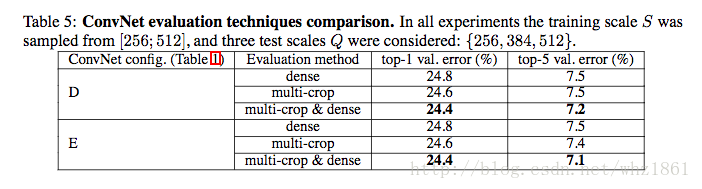
结论:
- 数据生成方式multi-crop效果略优于dense,但作者上文也提高,精度的提高不足以弥补计算上的损失
- multi-crop于dense方法结合的效果最后,也证明了作者的猜想:multi-crop和dense两种方法互为补充
模型融合
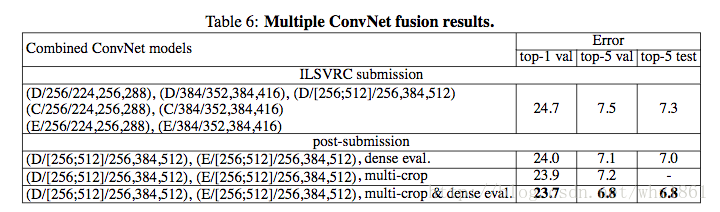
结论:
- 通过多种模型融合输出最终的预测结果,能达到the state-of-the-art的效果
对比
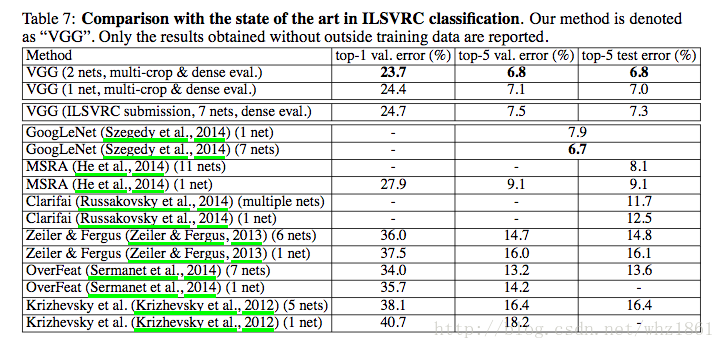
结论:
- 与其他模型对比发现,VGG也能达到非常好的效果。
总结
作者指出,VGG模型不仅能够在大规模数据集上的分类效果很好,其在其他数据集上的推广能力也非常出色。
VGG网络的更多相关文章
- 第二十四节,TensorFlow下slim库函数的使用以及使用VGG网络进行预训练、迁移学习(附代码)
在介绍这一节之前,需要你对slim模型库有一些基本了解,具体可以参考第二十二节,TensorFlow中的图片分类模型库slim的使用.数据集处理,这一节我们会详细介绍slim模型库下面的一些函数的使用 ...
- 关于VGG网络的介绍
本博客参考作者链接:https://zhuanlan.zhihu.com/p/41423739 前言: VGG是Oxford的Visual Geometry Group的组提出的(大家应该能看出VGG ...
- 基于深度学习的人脸识别系统(Caffe+OpenCV+Dlib)【三】VGG网络进行特征提取
前言 基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库).Caffe(深度学习库).Dlib(机器学习库).libfacedetection(人脸检测库).cudnn(gp ...
- VGG网络的Pytorch实现
1.文章原文地址 Very Deep Convolutional Networks for Large-Scale Image Recognition 2.文章摘要 在这项工作中,我们研究了在大规模的 ...
- 卷积神经网络特征图可视化(自定义网络和VGG网络)
借助Keras和Opencv实现的神经网络中间层特征图的可视化功能,方便我们研究CNN这个黑盒子里到发生了什么. 自定义网络特征可视化 代码: # coding: utf-8 from keras.m ...
- VGG网络-ILSVRC-2014亚军
用于大尺度图片识别的非常深的卷积网络 使用一个带有非常小的(3*3)的卷积核的结构去加深深度,该论文的一个十分重要的改进就是它将卷机网络的深度增加到了16-19层,且可以用于比较大224*224的图片 ...
- 【深度学习系列】用PaddlePaddle和Tensorflow实现经典CNN网络Vgg
上周我们讲了经典CNN网络AlexNet对图像分类的效果,2014年,在AlexNet出来的两年后,牛津大学提出了Vgg网络,并在ILSVRC 2014中的classification项目的比赛中取得 ...
- 学习TensorFlow,调用预训练好的网络(Alex, VGG, ResNet etc)
视觉问题引入深度神经网络后,针对端对端的训练和预测网络,可以看是特征的表达和任务的决策问题(分类,回归等).当我们自己的训练数据量过小时,往往借助牛人已经预训练好的网络进行特征的提取,然后在后面加上自 ...
- 第五弹:VGG
接下来讲一个目前经常被用到的模型,来自牛津大学的VGG,该网络目前还有很多改进版本,这里只讲一下最初的模型,分别从论文解析和模型理解两部分组成. 一.论文解析 一:摘要 -- 从Alex-net发展而 ...
随机推荐
- .net反编译的九款神器(转载)
.net反编译的九款神器 转载来源: https://www.cnblogs.com/zsuxiong/p/5117465.html 本人搜集了下8款非常不错的.Net反编译利器: 1.Reflec ...
- 3. 原子变量-CAS算法
1. 是什么 ? 2. CAS算法模拟 package com.gf.demo03; public class TestCompareAndSwap { public static void main ...
- java通过Access_JDBC30读取access数据库时无法获取最新插入的记录
1.编写了一个循环程序,每几秒钟读取一次,数据库中最新一行数据 连接access数据库的方法和查询的信息.之后开一个定时去掉用. package javacommon.util; import jav ...
- JAVA JVM常见内存参数配置简析
JVM常见内存参数配置简析 常见参数 -Xms .-Xmx.-XX:newSize.-XX:MaxnewSize.-Xmn(-XX:newSize.-XX:MaxnewSize) 简析 1.-Xm ...
- K8S Calico
NetworkPolicy是kubernetes对pod的隔离手段,是宿主机上的一系列iptables规则. Egress 表示出站流量,就是pod作为客户端访问外部服务,pod地址作为源地址.策略可 ...
- vuejs2.0实现一个简单的分页
用js实现的分页结果如图所示: css .page-bar{ margin:40px; } ul,li{ margin: 0px; padding: 0px; } li{ list-style: no ...
- Linux 新磁盘分区与挂载
1.查看未分区的盘 2.新建分区 3.格式化分区(/dev/sdb1) 4.查看磁盘uuid [root@web-node1 ~]# blkid /dev/vdb1 /dev/vdb1 ...
- Linux 解决Linux下火狐浏览器中文乱码成方块显示问题
解决Linux下火狐浏览器中文乱码成方块显示问题 by:授客 QQ:1033553122 测试环境: CentOS-6.0-x86_64 问题描述: 浏览器页面显示如下 解决方法: 安装中文支 ...
- git 入门教程之分支策略
默认情况下合并分支常常直接使用 git merge 命令,是最方便快速的合并方法.其实这种情况下 git 采用的是 fast forward 模式,特点是删除分支后,会丢失分支信息,好像从来没存在该分 ...
- MongoDB 安装与配置
MongoDB下载 官方下载链接:https://www.mongodb.com/download-center/community MongoDB安装 简单,按提示安装即可.安装方式: 1. Com ...