Elasticsearch 编程API入门系列---说在前面的话
前提,是
Eclipse下Maven新建项目、自动打依赖jar包(包含普通项目和Web项目)
setting.xml配置文件
如何在Maven官网下载历史版本
HBase 开发环境搭建(Eclipse\MyEclipse + Maven)
MapReduce 开发环境搭建(Eclipse\MyEclipse + Maven)
Hadoop项目开发环境搭建(Eclipse\MyEclipse + Maven)
Eclipse下Maven新建Web项目index.jsp报错完美解决(war包)
多去看看,会对你有益处!
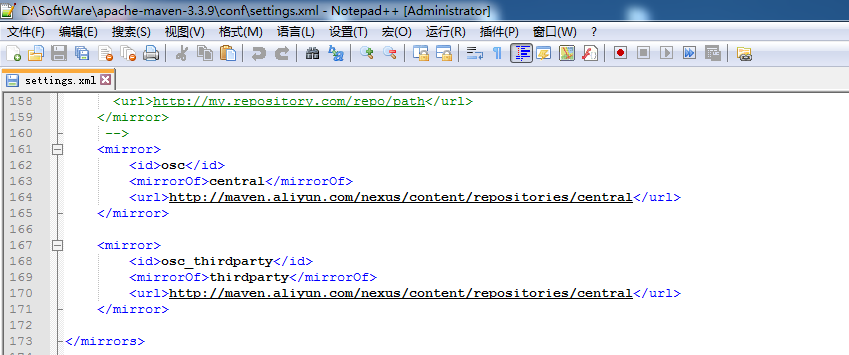
经验之谈,建议使用国内的镜像,当然,国外的也行,一般,两个都准备!当国内的有时候出现网速慢时,切换到国外。最好还是先国内。
这里,我推荐,使用阿里云的镜像!
maven 使用国内的镜像
修改 maven 下面的 conf/settings.xml 文件
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
Java操作es集群
步骤1:配置集群对象信息;2:创建客户端;3:查看集群信息
1:集群名称
默认集群名为elasticsearch,如果集群名称和指定的不一致则在使用节点资源时会报错。
2:嗅探功能
通过client.transport.sniff启动嗅探功能,这样只需要指定集群中的某一个节点(不一定是主节点),然后会加载集群中的其他节点,这样只要程序不停即使此节点宕机仍然可以连接到其他节点。
3:查询类型
ES中一共有四种查询类型。
| 查询类型 | 描述 | 特点 |
|---|---|---|
| QUERY_AND_FETCH | 主节点将查询请求分发到所有的分片中,各个分片按照自己的查询规则即词频文档频率进行打分排序,然后将结果返回给主节点,主节点对所有数据进行汇总排序然后再返回给客户端,此种方式只需要和ES交互一次 | ①存在数据量和排序问题,主节点会汇总所有分片返回的数据,这样数据量会比较大②各个分片上的规则可能不一致 |
| QUERY_THEN_FETCH | 主节点将请求分发给所有分片,各个分片打分排序后将数据的id和分值返回给主节点,主节点收到后进行汇总排序,再根据排序后的id到对应的节点读取对应的数据再返回给客户端,此种方式需要和ES交互两次 | 解决了数据量问题但是排序问题依然存在,是ES的默认查询方式 |
| DFS_QUERY_AND_FETCH | 和前面两种的区别在于将各个分片的规则统一起来进行打分 | 解决了排序问题,但是仍然存在数据量问题 |
| DFS_QUERY_THEN_FETCH | 和前面两种的区别在于将各个分片的规则统一起来进行打分 | 解决了排序和数据量问题但是效率是最差的 |
特点:
一个交互两次,一个交互一次;一个统一打分规则一个不统一;一个分片返回详细数据一个分片返回id。
4:分页压力
我们通过curl和java查询时都可以指定分页,但是页数越往后服务器的压力会越大。大多数搜索引擎都不会提供非常大的页数搜索,原因有两个一是用户习惯一般不会看页数大的搜索结果因为越往后越不准确,二是服务器压力。
比如分片是5分页单位是10查询第10000到10010条记录,es需要在所有分片上进行查询,每个分片会产生10010条排序后的数据然后返回给主节点,主节点接收5个分片的数据一共是50050条然后再进行汇总最后再取其中的10000到10010条数据返回给客户端,这样一来看似只请求了10条数据但实际上es要汇总5万多条数据,所以页码越大服务器的压力就越大。
5:超时timeout
查询时如果数据量很大,可以指定超时时间即到达此时间后无论查询的结果是什么都会返回并且关闭连接,这样用户体验较好缺点是查询出的数据可能不完整,Java和curl都可以指定超时时间。
Elasticsearch 编程API入门系列---说在前面的话的更多相关文章
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- HBase编程 API入门系列之create(管理端而言)(8)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门系列之put(客户端而言)(1) 就知道,在这篇博文里,我是在HBase Shell里创建HBase表的. 这里,我带领大家,学习更高 ...
- HBase编程 API入门系列之delete(客户端而言)(3)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面的基础,如下 HBase编程 API入门系列之put(客户端而言)(1) HBase编程 API入门系列之get(客户端而言) ...
- HBase编程 API入门系列之get(客户端而言)(2)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面是基础,如下 HBase编程 API入门系列之put(客户端而言)(1) package zhouls.bigdata.Hba ...
- HBase编程 API入门系列之HTable pool(6)
HTable是一个比较重的对此,比如加载配置文件,连接ZK,查询meta表等等,高并发的时候影响系统的性能,因此引入了“池”的概念. 引入“HBase里的连接池”的目的是: 为了更高的,提高程序的并发 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- HBase编程 API入门系列之delete(管理端而言)(9)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门之delete(客户端而言) 就知道,在这篇博文里,我是在客户端里删除HBase表的. 这里,我带领大家,学习更高级的,因为,在开发中 ...
随机推荐
- Caffe框架,了解三个文件
不知道从什么时候开始,Deep Learning成为了各个领域研究的热点,也不知道从什么时候开始,2015CVPR的文章出现了很多Deep Learning的文章,更不知道从什么时候开始,三维重建各个 ...
- JAVA之旅(八)——多态的体现,前提,好处,应用,转型,instanceof,多态中成员变量的特点,多态的案例
JAVA之旅(八)--多态的体现,前提,好处,应用,转型,instanceof,多态中成员变量的特点,多态的案例 学习是不能停止的 一.多态 我们今天又要学习一个新的概念了,就是多态,它是面向对象的第 ...
- 一个不错的扩展:Ext.ux.container.ButtonSegment
地址:http://www.sencha.com/forum/showthread.php?132048-Ext.ux.container.ButtonSegment
- 客户信息全SQL
SELECT hp.party_name "客户名称", --客户名称 hca.account_number "客户编号", --客户编号 hca.cust_a ...
- 单向循环链表C语言实现
我们都知道,单向链表最后指向为NULL,也就是为空,那单向循环链表就是不指向为NULL了,指向头节点,所以下面这个程序运行结果就是,你将会看到遍历链表的时候就是一个死循环,因为它不指向为NULL,也是 ...
- ANDROID 中设计模式的采用--行为模式
1 职责链模式 职责链模式的意图为:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系.将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止.使多个对象都有 ...
- ExtJS:GridPanel之renderer:function()和itemdblclick : function()方法参数详解
要使用GridPanel,首先要定义Store,而在创建Store的时候必须要有Model,因此我们首先来定义Model: Ext.define("Gpsdata", { exte ...
- Android服务器——TomCat服务器的搭建
Android服务器--TomCat服务器的搭建 作为一个开发人员,当然是需要自己调试一些程序的,这个时候本地的服务器就十分方便了,一般都会使用TomCat或者IIS服务器,IIS就比较简单了,其实t ...
- Mybatis中文查询没有结果
我用中文参数去查找数据,没有返回结果,应该是乱码问题 进行如下配置问题消失:jdbc:mysql://localhost:3306/appstore_db?useUnicode=true&ch ...
- VS2010中使用Jquery调用Wcf服务读取数据库记录
VS2010中使用Jquery调用Wcf服务读取数据库记录 开发环境:Window Servere 2008 +SQL SERVE 2008 R2+ IIS7 +VS2010+Jquery1.3.2 ...