Caffe的运行mnist手写数字识别
老规矩,首先附上官方教程:http://caffe.berkeleyvision.org/gathered/examples/mnist.html
注:关于caffe的安装教程请看我的上一篇文章
1、必要软件
因为Caffe中使用的是Linux才能运行的shell脚本,因此首先的安装 wget(将wget放入C:\windows\system32)和 Git 方能运行。
2、而后按照官方教程,首先进入caffe路径的根目录,而后打开cmd输入命令:
./data/mnist/get_mnist.sh
这个命令是通过打开/data/mnist目录下的get_mnist.sh脚本来下载mnist的数据,若cmd出现错误可以直接进入打开get_mnist.sh脚本效果是一样的,运行完成后会出现如下4个数据文件:

而后继续输入以下命令,或者进入路径打开也一样
./examples/mnist/create_mnist.sh
若不存在该文件可以自己创建一个create_mnist.sh,具体的代码如下(注:第九行BUILD可能老版本的路径会不一样,根据自己路径来修改):
#!/usr/bin/env sh # This script converts the mnist data into lmdb/leveldb format,
# depending on the value assigned to $BACKEND.
set -e EXAMPLE=.
DATA=../../data/mnist
BUILD=../../scripts/build/examples/mnist/Release BACKEND="lmdb" echo "Creating ${BACKEND}..." rm -rf $EXAMPLE/mnist_train_${BACKEND}
rm -rf $EXAMPLE/mnist_test_${BACKEND} $BUILD/convert_mnist_data.exe $DATA/train-images-idx3-ubyte \
$DATA/train-labels-idx1-ubyte $EXAMPLE/mnist_train_${BACKEND} --backend=${BACKEND}
$BUILD/convert_mnist_data.exe $DATA/t10k-images-idx3-ubyte \
$DATA/t10k-labels-idx1-ubyte $EXAMPLE/mnist_test_${BACKEND} --backend=${BACKEND} echo "Done." read -p "回车继续..."
运行完成后会出现mnist_test_lmdb和mnist_train_lmdb两个文件夹:

cmd显示:

3、打开路径/scripts/build/examples/mnist/Release下的lenet_solver.prototxt(不同版本的caffe的路径不一样,有些老版本的caffe的路径为:/Build/x64/Release),根据自己的情况修改参数:
第二行:若lenet_train_test.prototxt和lenet_solver.prototxt不在同一路径下,则需要在其之前写上lenet_train_test.prototxt所在的路径
第23行:snapshot_prefix:生成的model为产生的训练模型,可根据自己来修改路径
最后一行为选择安装的caffe是CPU还是GPU,我这里安装的是GPU版本
注意:不要直接将文件路径复制过去,因为在这里面路径分隔符是/ ,而不是\,如果使用\后面运行时会出现以下错误(下面几步同样如此,如果不确定就照着我的写):
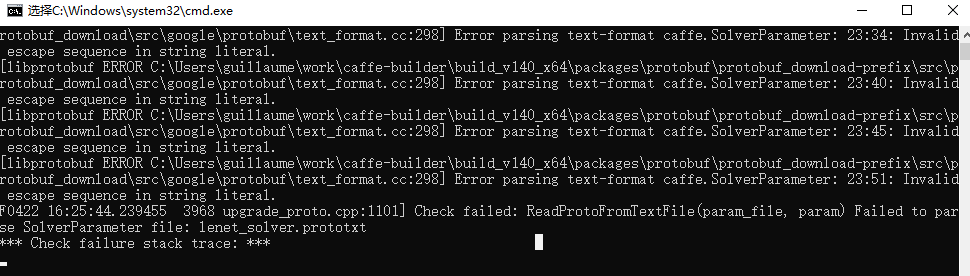
修改参数后的结果:
# The train/test net protocol buffer definition
net: "lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "E:/CaffeSource/caffe/data/mnist/model"
# solver mode: CPU or GPU
solver_mode: GPU
4、打开lenet_train_test.prototxt(上面第二行那个文件)
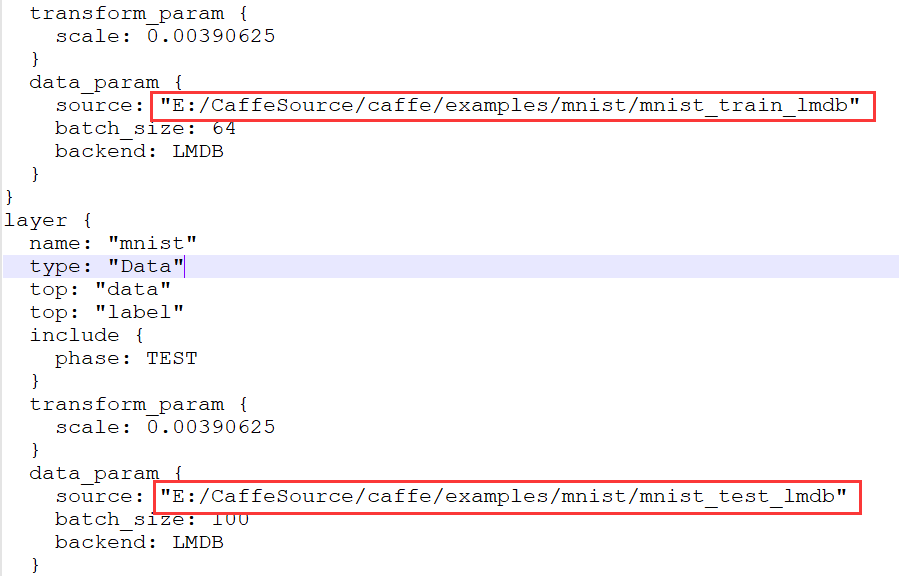
而后更改上图路径,这两个文件是执行./data/mnist/get_mnist.sh命令时下载的文件,将其路径添加进去
5、在目录\examples\mnist下新建一个train_lenet.txt文档,添加下面一段,然后改后缀名为.bat
..\..\Build\x64\Release\caffe.exe train --solver="lenet_solver.prototxt" --gpu 0
pause
或者在该目录下修改train_lenet.sh文件:
#!/usr/bin/env sh
set -e
BUILD=../../Build/x64/Release/
echo "Training lenet_solver.prototxt..." $BUILD/caffe.exe train --solver=lenet_solver.prototxt $@
echo "Done." read -p "回车继续..."
6、运行该文件,大概运行几分钟后结果如下:
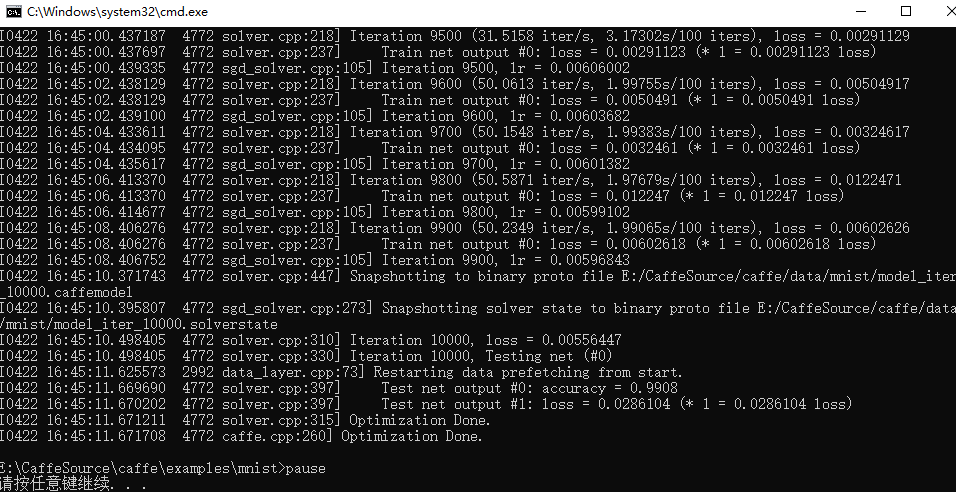
若没有报错,则测试就算大功告成啦!
可以看出准确度为99%,训练好的模型保存在 lenet_iter_10000.caffemodel, 训练状态保存在lenet_iter_10000.solverstate里,结果如下:

Caffe的运行mnist手写数字识别的更多相关文章
- 持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型
持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献Tensorflow实战Google深度学习框架 实验平台: Tens ...
- 基于TensorFlow的MNIST手写数字识别-初级
一:MNIST数据集 下载地址 MNIST是一个包含很多手写数字图片的数据集,一共4个二进制压缩文件 分别是test set images,test set labels,training se ...
- Android+TensorFlow+CNN+MNIST 手写数字识别实现
Android+TensorFlow+CNN+MNIST 手写数字识别实现 SkySeraph 2018 Email:skyseraph00#163.com 更多精彩请直接访问SkySeraph个人站 ...
- 深度学习之 mnist 手写数字识别
深度学习之 mnist 手写数字识别 开始学习深度学习,先来一个手写数字的程序 import numpy as np import os import codecs import torch from ...
- 基于tensorflow的MNIST手写数字识别(二)--入门篇
http://www.jianshu.com/p/4195577585e6 基于tensorflow的MNIST手写字识别(一)--白话卷积神经网络模型 基于tensorflow的MNIST手写数字识 ...
- 第三节,CNN案例-mnist手写数字识别
卷积:神经网络不再是对每个像素做处理,而是对一小块区域的处理,这种做法加强了图像信息的连续性,使得神经网络看到的是一个图像,而非一个点,同时也加深了神经网络对图像的理解,卷积神经网络有一个批量过滤器, ...
- mnist 手写数字识别
mnist 手写数字识别三大步骤 1.定义分类模型2.训练模型3.评价模型 import tensorflow as tfimport input_datamnist = input_data.rea ...
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别 http://phunter.farbox.com/post/mxnet-tutorial1 用MXnet实战深度学 ...
- Tensorflow之MNIST手写数字识别:分类问题(1)
一.MNIST数据集读取 one hot 独热编码独热编码是一种稀疏向量,其中:一个向量设为1,其他元素均设为0.独热编码常用于表示拥有有限个可能值的字符串或标识符优点: 1.将离散特征的取值扩展 ...
随机推荐
- 四则运算程序(java基于控制台)
四则运算题目生成程序(基于控制台) 一.题目描述: 1. 使用 -n 参数控制生成题目的个数,例如 Myapp.exe -n 10 -o Exercise.txt 将生成10个题目. 2. 使用 -r ...
- java 中的JDK封装的数据结构和算法解析(集合类)----顺序表 List 之 ArrayList
1. 数据结构之List (java:接口)[由于是分析原理,这里多用截图说明] List是集合类中的容器之一,其定义如下:(无序可重复) An ordered collection (also kn ...
- java虚拟机的内存分配与回收机制
分为4个方面来介绍内存分配与回收,分别是内存是如何分配的.哪些内存需要回收.在什么情况下执行回收.如何监控和优化GC机制. java GC(Garbage Collction)垃圾回收机制,是java ...
- 2017年秋软工-领跑衫获奖感言&我最感谢的人
啥都不说,先上幅图.获得领跑衫,开心. 一.回忆 这是我第二次来上恩师杨的软件工程,第一次是2016年春,那时候我还是本科三年级的学生.忘了第一次为啥去蹭课,印象中是我的榜样亮哥把我给忽悠过去的?我也 ...
- 安装iis8
-------------------- @echo off echo 正在添加IIS8.0 功能,依据不同的网络速率,全程大约需要5分钟时间... start /w pkgmgr / ...
- 20162318 实验三《 敏捷开发与XP实践》实验报告
北京电子科技学院(BESTI) 实 验 报 告 课程:程序设计与数据结构 班级:1623班 姓名:张泰毓 指导老师:娄老师.王老师 实验日期:2017年5月12日 实验密级:非密级 实验器材:带Lin ...
- 项目Alpha冲刺Day6
一.会议照片 二.项目进展 1.今日安排 熟悉后台框架并编写.继续搭建前台框架模版.熟悉前端框架开发流程.完成前端热部署配置.完成部分后台用户信息相关接口.解决后台jdk1.8日期在框架中的使用. 2 ...
- 201621123043 《Java程序设计》第7周学习总结
1. 本周学习总结 2.书面作业 1. GUI中的事件处理 1.1 写出事件处理模型中最重要的几个关键词. 事件:用户的操作. 事件源:产生事件的组件. 事件监听程序:对事件进行处理的操作所引发的相关 ...
- 玩转Leveldb原理及源码--拙见1
可以说是不知天高地厚.. 可以说是班门弄斧.. 但是,我今天还就这样走了,我喜欢!!!!!! 注:后续文章,限于篇幅,不懂名词都有 紫色+下划线 超链接,有兴趣,可以查阅: 网上关于Leveldb 的 ...
- python的模块和包
==模块== python语言的组织结构层次: 包->模块->代码文件->类->函数->代码块 什么是模块呢 可以把模块理解为一个代码文件的封装,这是比类更高一级的封装层 ...