Tensorflow学习-数据读取
Tensorflow数据读取方式主要包括以下三种
- Preloaded data:预加载数据
- Feeding: 通过Python代码读取或者产生数据,然后给后端
- Reading from file: 通过TensorFlow队列机制,从文件中直接读取数据
前两种方法比较基础而且容易理解,在Tensorflow入门教程、书本中经常可以见到,这里不再进行介绍。
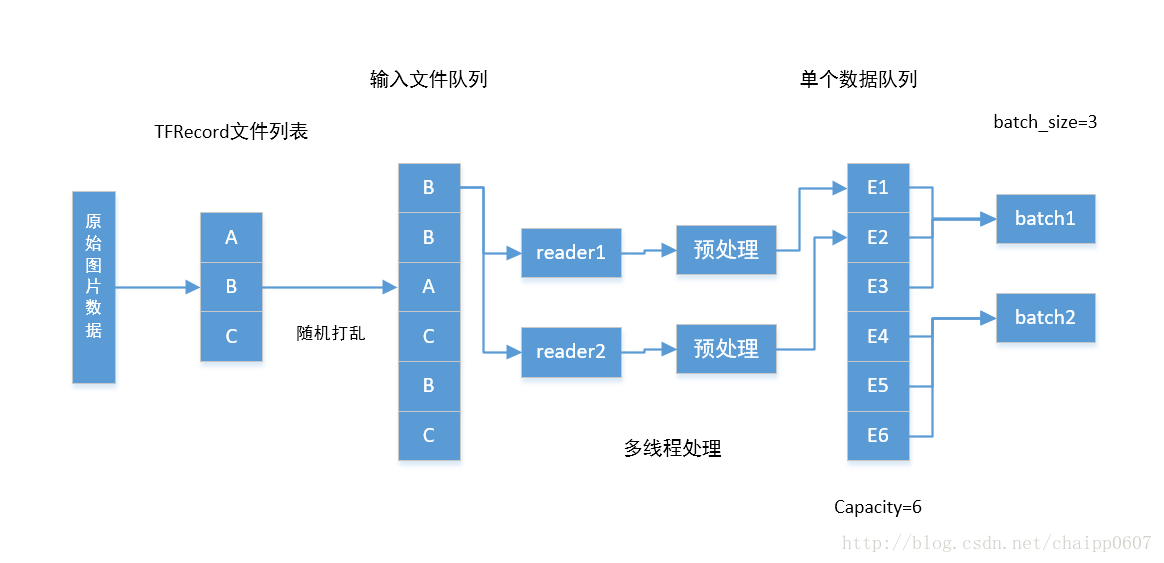
在介绍Tensorflow第三种读取数据方法之前,介绍以下有关队列相关知识
Queue(队列)
队列是用来存放数据的,并且tensorflow中的Queue中已经实现了同步机制,所以我们可以放心的往里面添加数据还有读取数据。如果Queue中的数据满了,那么en_queue(队列添加元素)操作将会阻塞,如果Queue是空的,那么dequeue(队列抛出元素)操作就会阻塞.在常用环境中,一般是有多个en_queue线程同时像Queue中放数据,有一个dequeue操作从Queue中取数据。
Coordinator(协调管理器)
Coordinator主要是用来帮助管理多个线程,协调多线程之间的配合
# Thread body: loop until the coordinator indicates a stop was requested.
# If some condition becomes true, ask the coordinator to stop.
#将coord传入到线程中,来帮助它们同时停止工作
def MyLoop(coord):
while not coord.should_stop():
...do something...
if ...some condition...:
coord.request_stop()
# Main thread: create a coordinator.
coord = tf.train.Coordinator()
# Create 10 threads that run 'MyLoop()'
threads = [threading.Thread(target=MyLoop, args=(coord,)) for i in xrange(10)]
# Start the threads and wait for all of them to stop.
for t in threads:
t.start()
coord.join(threads)
QueueRunner()
QueueRunner可以创建多个线程对队列(queue)进行插入(enqueue)操作,它是一个op,这些线程可以通过上述的Coordinator协调器来协调工作。
在深度学习中样本数据集有多种存储编码形式,以经典数据集Cifar-10为例,公开共下载的数据有三种存储方式:Bin(二进制)、Python以及Matlab版本。此外,我们常用的还有csv(天池竞赛、百度竞赛等)比较常见或txt等,当然对图片存储最为直观的还是可视化展示的TIF、PNG、JPG等。Tensorflow官方推荐使用他自己的一种文件格式叫TFRecord,具体实现及应用会在以后详细介绍。
从上图中可知,Tensorflow数据读取过程主要包括两个队列(FIFO),一个叫做文件队列,主要用作对输入样本文件的管理(可以想象,所有的训练数据一般不会存储在一个文件内,该部分主要完成对数据文件的管理);另一个叫做数据队列,如果对应的数据是图像可以认为该队列中的每一项都是存储在内存中的解码后的一系列图像像素值。
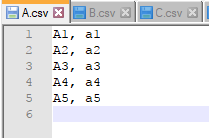
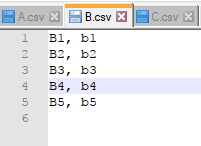
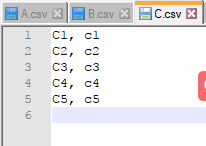
下面,我们分别新建3个csv文件->A.csv;B.csv;C.csv,每个文件下分别用X_i, y_i代表训练样本的数据及标注信息。
#-*- coding:gbk -*-
import tensorflow as tf
# 队列1:生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False, num_epochs=2)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['string'], ['string']])
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(12):
e_val, l_val = sess.run([example, label])
print(e_val, l_val)
coord.request_stop()
coord.join(threads)
程序中,首先根据文件列表,通过tf.train.string_input_producer(filenames, shuffle=False)函数建立了一个对应的文件管理队列,其中shuffle=False表 示不对文件顺序进行打乱(True表示打乱,每次输出顺序将不再一致)。此外,还可通过设置第三个参数num_epochs来控制文件数据多少。
运行结果如下:

上段程序中,主要完成以下几方面工作:
- 针对文件名列表,建立对应的文件队列
- 使用reader读取对应文件数据集
- 解码数据集,得到样本example和标注label
感兴趣的读者可以打开tf.train.string_input_producer(...)函数,可以看到如下代码
"""
@compatibility(eager)
Input pipelines based on Queues are not supported when eager execution is
enabled. Please use the `tf.data` API to ingest data under eager execution.
@end_compatibility
"""
if context.in_eager_mode():
raise RuntimeError(
"Input pipelines based on Queues are not supported when eager execution"
" is enabled. Please use tf.data to ingest data into your model"
" instead.")
with ops.name_scope(name, "input_producer", [input_tensor]):
input_tensor = ops.convert_to_tensor(input_tensor, name="input_tensor")
element_shape = input_tensor.shape[1:].merge_with(element_shape)
if not element_shape.is_fully_defined():
raise ValueError("Either `input_tensor` must have a fully defined shape "
"or `element_shape` must be specified")
if shuffle:
input_tensor = random_ops.random_shuffle(input_tensor, seed=seed)
input_tensor = limit_epochs(input_tensor, num_epochs)
q = data_flow_ops.FIFOQueue(capacity=capacity,
dtypes=[input_tensor.dtype.base_dtype],
shapes=[element_shape],
shared_name=shared_name, name=name)
enq = q.enqueue_many([input_tensor])
queue_runner.add_queue_runner(
queue_runner.QueueRunner(
q, [enq], cancel_op=cancel_op))
if summary_name is not None:
summary.scalar(summary_name,
math_ops.to_float(q.size()) * (1. / capacity))
return q
可以看到该段代码主要完成以下工作:
- 创建队列Queue
- 创建线程enqueue_many
- 添加QueueRunner到collection中
- 返回队列Queue
数据解析
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['string'], ['string']])
这里,我们通过定义一个reader来读取每个数据文件内容,也可图中也展示了TensorFlow支持定义多个reader并且读取文件队列中文件内容,从而提供数据读取效率。然后,采用一个decoder_csv函数对读取的原始CSV文件内容进行解码,平时我们也可根据自己数据存储格式选择不同数据解码方式。在这里需要指出的是,上述程序中并没有用到图中展示的第二个数据队列,这是为什么呢。
实际上做深度学习or机器学习训练过程中,为了保证训练过程的高效性通常不采用单个样本数据给训练模型,而是采用一组N个数据(称作mini-batch),并把每组样本个数N成为batch-size。现在假设我们每组需要喂给模型N个数据,需通过N次循环读入内存,然后再通过GPU进行前向or返向传播运算,这就意味着GPU每次运算都需要一段时间等待CPU读取数据,从而大大降低了训练效率。而第二个队列(数据队列)就是为了解决这个问题提出来的,代码实现即为:tf.train.batch()和 tf.train.shuffle_batch,这两个函数的主要区别在于是否需要将列表中数据进行随机打乱。
#-*- coding:gbk -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False, num_epochs=3)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['string'], ['string']])
#example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=16, capacity=200, min_after_dequeue=100, num_threads=2)
example_batch, label_batch = tf.train.batch([example,label], batch_size=8, capacity=200, num_threads=2)
#example_list = [tf.decode_csv(value, record_defaults=[['string'], ['string']])
# for _ in range(2)] # Reader设置为2
### 使用tf.train.batch_join(),可以使用多个reader,并行读取数据。每个Reader使用一个线程。
#example_batch, label_batch = tf.train.batch_join(
# example_list, batch_size=5)
init_local_op = tf.initialize_local_variables()
with tf.Session() as sess:
sess.run(init_local_op)
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(5):
# Retrieve a single instance:
e_val, l_val = sess.run([example_batch, label_batch])
print(e_val, l_val)
coord.request_stop()
coord.join(threads)
使用tf.train.batch()函数,每次根据自己定义大小会返回一组训练数据,从而避免了往内存中循环读取数据的麻烦,提高了效率。并且还可以通过设置reader个数,实现多线程高效地往数据队列(或叫内存队列)中填充数据,直到文件队列读完所有文件(或文件数据不足一个batch size)。
tf.train.batch()程序运行结果如下
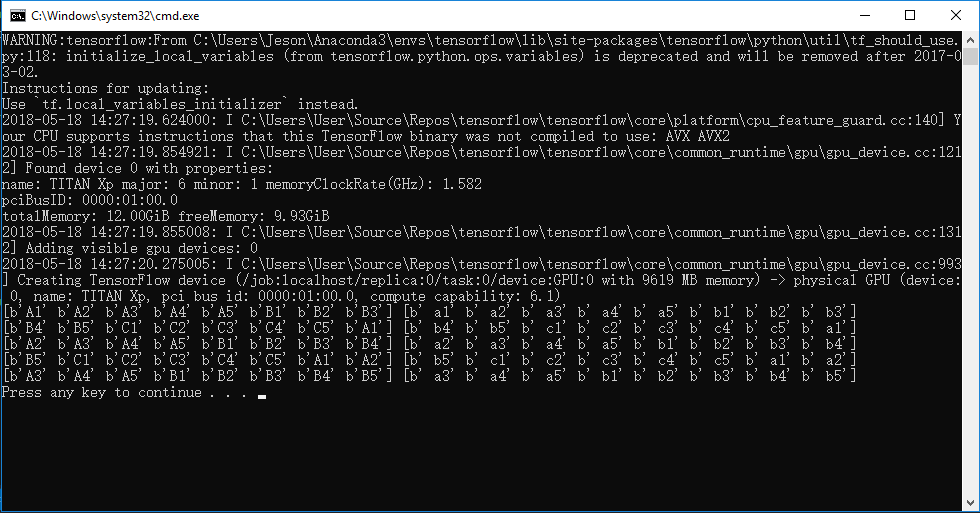
注:tf.train.batch([example,label], batch_size=8, capacity=200, num_threads=2)参数中,capacity表示队列大小,每次读出数据后队尾会按顺序依次补充。num_treads=2表示两个线程(据说在一个reader下可达到最优),batch_size=8表示每次返回8组训练数据,即batch size大小。tf.train.shuffle_batch()比tf.train.bathc()多一个min_after_dequeue参数,意思是在每次抛出一个batch后,剩余数据样本不少于多少个。
Tensorflow学习-数据读取的更多相关文章
- AI学习---数据读取&神经网络
AI学习---数据读取&神经网络 fa
- Tensorflow学习教程------读取数据、建立网络、训练模型,小巧而完整的代码示例
紧接上篇Tensorflow学习教程------tfrecords数据格式生成与读取,本篇将数据读取.建立网络以及模型训练整理成一个小样例,完整代码如下. #coding:utf-8 import t ...
- tensorflow之数据读取探究(2)
tensorflow之tfrecord数据读取 Tensorflow关于TFRecord格式文件的处理.模型的训练的架构为: 1.获取文件列表.创建文件队列:http://blog.csdn.net/ ...
- tensorflow之数据读取探究(1)
Tensorflow中之前主要用的数据读取方式主要有: 建立placeholder,然后使用feed_dict将数据feed进placeholder进行使用.使用这种方法十分灵活,可以一下子将所有数据 ...
- 关于Tensorflow 的数据读取环节
Tensorflow读取数据的一般方式有下面3种: preloaded直接创建变量:在tensorflow定义图的过程中,创建常量或变量来存储数据 feed:在运行程序时,通过feed_dict传入数 ...
- 机器学习: TensorFlow 的数据读取与TFRecords 格式
最近学习tensorflow,发现其读取数据的方式看起来有些不同,所以又重新系统地看了一下文档,总得来说,tensorflow 有三种主流的数据读取方式: 1) 传送 (feeding): Pytho ...
- tensorflow学习--数据加载
文章主要来自Tensorflow官方文档,同时加入了自己的理解以及部分代码 数据读取 TensorFlow程序读取数据一共有3种方法: 供给数据(Feeding): 在TensorFlow程序运行的每 ...
- 『TensorFlow』数据读取类_data.Dataset
一.资料 参考原文: TensorFlow全新的数据读取方式:Dataset API入门教程 API接口简介: TensorFlow的数据集 二.背景 注意,在TensorFlow 1.3中,Data ...
- TensorFlow的数据读取机制
一.tensorflow读取机制图解 首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取的过程可以用下图来表示 假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003 ...
随机推荐
- 浮点数据有损压缩算法 附完整C代码
在几年前的时候在做修图APP算法的时候, 曾经一度想过对3D Lut 预设数据进行压缩, 主要用于提升用户体验. 关于3d lut算法开源的资源也挺多的,就不多做科普了. 有兴趣的朋友,可以去查阅下f ...
- 一种WPF在后台线程更新UI界面的简便方法
WPF框架规定只有UI线程(主线程)可以更新界面,所有其他后台线程无法直接更新界面.幸好,WPF提供的SynchronizationContext类以及C#的Lambda表达式提供了一种方便的解决方法 ...
- Spring3.x企业应用开发实战-Spring+Hibernat架构分析
1: 持久层设计 采用Spring注解方式省略了大量Hibernate ORM配置文件: BaseDAO减少DAO层代码量,只需要编写非通用型的持久层方法: 持久层提供分页支持: Hibernate ...
- JS核心笔记
一.说明 JS权威指南文字用红色标出: JS高级程序设计用橙色标出; 自己加上的文字用粉红色标出: 其(一)-(九)为JS权指南,(十)为JS高级程序设计 二.记法结构 2.1字符集 Javascri ...
- SpringBoot配置拦截器
[配置步骤] 1.为类添加注解@Configuration,配置拦截器 2.继承WebMvcConfigurerAdapter类 3.重写addInterceptors方法,添加需要拦截的请求 @Co ...
- golang升级
系统安装软件一般在/usr/share,可执行的文件在/usr/bin,配置文件可能安装到了/etc下等. 文档一般在 /usr/share 可执行文件 /usr/bin 配置文件 /etc lib文 ...
- pymongo "ServerSelectionTimeoutError: No servers found yet" 错误的解决
系统转移过程中,擅自把aptitude安装的mongoengine换成了pip安装,系统启动以后,报这个错误 报错提示: File "/usr/local/lib/python2.7/dis ...
- linux/unix解压缩
转自:http://blog.sina.com.cn/s/blog_6f2d29af01015ac6.html zip: 压缩: zip [-AcdDfFghjJKlLmoqrSTuvVwXyz$][ ...
- 分析DuxCms之AdminController
/** * 后台模板显示 调用内置的模板引擎显示方法, * @access protected * @param string $templateFile 指定要调用的模板文件 * @return v ...
- iframe跨域动态设置主窗口宽高
Q:在A项目的a页面嵌入一个iframe,src是B项目的b页面,怎样让a页面的高度跟b页面的高度一样? A:解决跨域方案:增加一个A项目的c页面. 操作步骤: 一,a页面的iframe设置: 获取到 ...