ha环境下重新格式化hdfs报错
datanode启动不成功,如下所示,我的136,137.138都是datanode,都启动不了。
查看datanode日志文件发现报错:
一个报错Incompatible clusterIDs in /home/hadoop/data/datanode,需要删除core-site.xml中配置的hadoop.tmp.dir临时目录下的东西。
第二个报错需要删除hdfs-site.xml中配置dfs.datanode.data.dir对应的目录下的东西。
然后重新格式化hdfs后,重启hdfs就可以了。
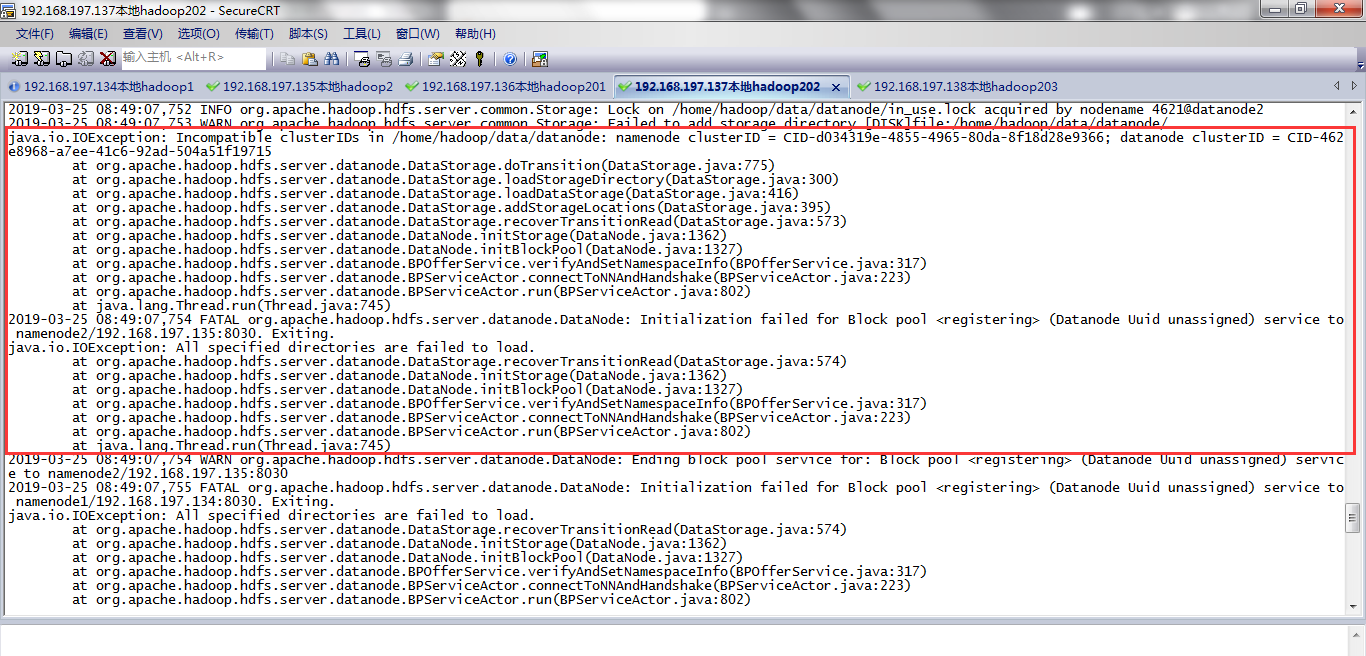
2019-03-25 08:49:07,753 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/hadoop/data/datanode/
java.io.IOException: Incompatible clusterIDs in /home/hadoop/data/datanode: namenode clusterID = CID-d034319e-4855-4965-80da-8f18d28e9366; datanode clusterID = CID-462e8968-a7ee-41c6-92ad-504a51f19715
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:775)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:300)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:416)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:395)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:573)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1362)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1327)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:223)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:802)
at java.lang.Thread.run(Thread.java:745)
2019-03-25 08:49:07,754 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to namenode2/192.168.197.135:8030. Exiting.
java.io.IOException: All specified directories are failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:574)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1362)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1327)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:223)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:802)
at java.lang.Thread.run(Thread.java:745)
ha环境下重新格式化hdfs报错的更多相关文章
- hadoop ha环境下的datanode启动报错java.lang.NumberFormatException: For input string: "10m"
hadoop ha环境启动start-dfs.sh的时候datanode启动不了,并且报错. [hadoop@datanode2 ~]$ cat /home/hadoop/hadoop-2.7.3/l ...
- Hadoop格式化HDFS报错java.net.UnknownHostException: localhost.localdomain: localhost.localdomain
异常描述: 在对HDFS格式化,执行hadoop namenode -format命令时,出现未知的主机名的问题,异常信息如下所示: [shirdrn@localhost bin]$ hadoop n ...
- window环境下npm install node-sass报错
最近准备想用vue-cli初始化一个项目,需要sass-loader编译: 发现window下npm install node-sass和sass-loader一直报错, window 命令行中提示我 ...
- thinkphp 5.0 lnmp环境下 无法访问,报错500(public目录)
两种方法: 1.修改fastcgi的配置文件 /usr/local/nginx/conf/fastcgi.conf fastcgi_param PHP_ADMIN_VALUE "open_b ...
- windows环境下安装scrapy框架报错问题--最快捷有效的解决方案
windows在执行如下命令,安装scrapy的过程中会报错: pip install scrapy 报错分析: windows环境下,会出现如下错误: 1.提示的错误是编译环境的问题,字面意思看需要 ...
- ubuntu1604环境下mariadb启动卡住报错和apparmor基本使用
问题描述:Ubuntu 1604 新环境下使用apt安装的mariadb10版本,结果第二天就起不来了,很是郁闷 启动时会卡住,当时就慌了,这什么情况啊,昨天好好的今天就起不来了,过了一会儿就有返回信 ...
- windows10环境下pip安装Scrapy报错
问题描述 当前环境win10,python_3.6.1,64位. 在windows下,在dos中运行pip install Scrapy报错: building 'twisted.test.raise ...
- Hadoop格式化HDFS报错java.net.UnknownHostException: centos64
异常描述 在对HDFS格式化,执行hadoop namenode -format命令时,出现未知的主机名的问题,异常信息如下所示: [shirdrn@localhost bin]$ hadoop na ...
- ubuntu环境下重启mysql服务报错“No directory, logging in with HOME=-”
前提:使用系统的环境 3.13.0-24-generic mysql的版本:5.6.33 错误描述: 首先用mysqld_safe启动报错如下: root@zabbix-forFunction:~# ...
随机推荐
- java中的Object类和其clone()
1.Object是所有类的父类,任何类都默认继承Object,即直接或间接的继承java.lang.Object类.由于所有的类都继承在Object类,因此省略了extends Object关键字. ...
- Gravitational Teleport 开源的通过ssh && kubernetes api 管理linux 服务器集群的网关
Gravitational Teleport 是一个开源的通过ssh && kubernetes api 管理linux 服务器集群的网关 支持以下功能: 基于证书的身份认证 ssh ...
- #pragma Directive in C/C++
The #pragma is complier specified. for example, the code below does not work in gcc. #pragma startup ...
- Unity 游戏性能优化 学习
优化误区
- taro 列表渲染
元素的 key 在他的兄弟元素之间应该唯一 数组元素中使用的 key 在其兄弟之间应该是独一无二的.然而,它们不需要是全局唯一的.当我们生成两个不同的数组时,我们可以使用相同的 key key 的取值 ...
- Python random模块sample、randint、shuffle、choice随机函数
一.random模块简介 Python标准库中的random函数,可以生成随机浮点数.整数.字符串,甚至帮助你随机选择列表序列中的一个元素,打乱一组数据等. 二.random模块重要函数 1 ).ra ...
- workerman的使用实践--并与solaris通信
Workerman与solarisTCP通信测试 1. 笔记本win7,tcp_test.php 2. solaris,test.c 编译命令: gcc test.c –o test –lsoc ...
- struts中的dojo控件sx:submit布局问题
想在一个四列的表格中插入两个按钮,希望实现下面的布局效果: 其中保存按钮为<sx:submit />控件.按照下面的代码布局: <tr><td align="c ...
- [转]使用 Angular CLI 和 ng-packagr 构建一个标准的 Angular 组件库
使用 Angular CLI 构建 Angular 应用程序是最方便的方式之一. 项目目标 现在,我们一起创建一个简单的组件库. 首先,我们需要创建一个 header 组件.这没什么特别的,当然接下来 ...
- DataFlow编程模型与Spark Structured streaming
流式(streaming)和批量( batch):流式数据,实际上更准确的说法应该是unbounded data(processing),也就是无边界的连续的数据的处理:对应的批量计算,更准确的说法是 ...