Adaboost\GBDT\GBRT\组合算法
Adaboost\GBDT\GBRT\组合算法(龙心尘老师上课笔记)
一、Bagging (并行bootstrap)& Boosting(串行)
随机森林实际上是bagging的思路,而GBDT和Adaboost实际上是boosting的思路。而bagging和boosting有什么区别呢?怎样从bagging转到boosting呢?
Bagging的假设函数:
如果是二分类问题: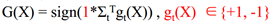 ,其中T是分类器的总数,g(x)是其中的小分类器的取值(+1或-1),最后根据各个分类器的值求加和,根据和的符号得到最终大分类器是正还是负。
,其中T是分类器的总数,g(x)是其中的小分类器的取值(+1或-1),最后根据各个分类器的值求加和,根据和的符号得到最终大分类器是正还是负。
如果是回归问题: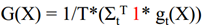 ,最后取得是各个小分类器的平均值。
,最后取得是各个小分类器的平均值。
Bagging的特点1.各个学习器相互独立,可以同时并行生成;2.各个学习期权重相同
而Boosting特别大的区别就在于,各个学习器强烈依赖(上一个学习器产生,再产生下一个),串行生成,其中,gbdt(每个学习器权重相同),Adaboost(每个学习器权重不同)。
Boosting要解决的核心问题:
产生不同的训练集(训练集各样本标签不同,训练集各样本抽样权重不同)
产生不同的模型(不同的训练集,就能产生不同模型)
产生不同模型对应的权重
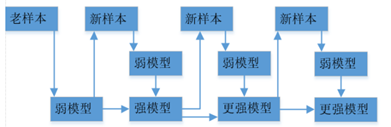
二、GBDT(生成新标签,串行生成树)
假设函数: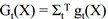
损失函数:均方损失函数
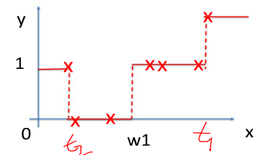
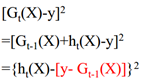 其中红色部分是之前集成学习器产生的残差,对应来看,这样可以理解成,红色部分相当于可以把之前学习器的残差,作为原来样本的新标签。这样就产生了新的训练集可以生成新的模型(下面右图2)。集成弱模型,得到强模型(下图3,样本x不变,标签Y变),依次下去重复,直到集合成最强模型。
其中红色部分是之前集成学习器产生的残差,对应来看,这样可以理解成,红色部分相当于可以把之前学习器的残差,作为原来样本的新标签。这样就产生了新的训练集可以生成新的模型(下面右图2)。集成弱模型,得到强模型(下图3,样本x不变,标签Y变),依次下去重复,直到集合成最强模型。
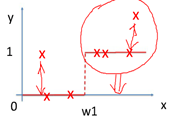
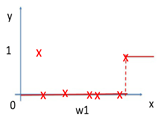
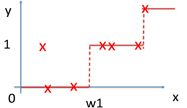
损失函数:
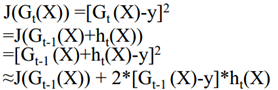 (一阶泰勒展开,因为h(x)不是单位长度,所以需要放缩到单位长度,变成有约束条件下的凸优化问题;chargeboost中试二阶展开,就不用放缩了)
(一阶泰勒展开,因为h(x)不是单位长度,所以需要放缩到单位长度,变成有约束条件下的凸优化问题;chargeboost中试二阶展开,就不用放缩了)
从集成学习器变成基学习器,不优化集成学习器整体,而以之前的学习器为已知项(G(X)),优化增加的那个学习器(损失函数也优化基学习器的)。不优化权重整体,而以之前的权重为已知项,优化权重变化的小量。每一步H(X)实际上就是CART树的生成过程。
三、Adaboost(每次新的学习器是基于上一次分类错误的样本,通过关注样本的权重来实现)
可以证明GDBT也是Adaboost的一种,最本质的区别:损失函数不同,指数损失函数:
另一个区别:假设函数不同:

g(x)的取值实际上是+1,-1,然后给一个权重相加,最后只取符号,正的就是+1,负的就是-1;a会越来越小,后面的学习器会越来越弱,所以尽管后面可能有些前面的被分类错误了,影响也不大。一直经历分对,分错,分对,分错的过程,直到损失函数最小,但后面的学习器的分布权重减少。
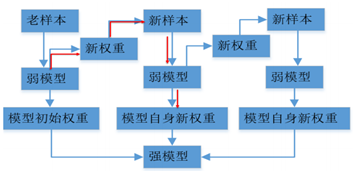
理解Adaboost训练过程
1. 新的弱模型来自于上一个弱模型,而不是之前所有模型的集合(GBDT)
2. 每个弱模型到强模型之前有权重(弱模型自身生成的权重)
3. 新权重,是样本的权重
样本权重:不同的样本分布权重对应不同训练集,类比boostrap,每一次boostrap抽样产生的新的训练集各类别样本比例不一样。(类似于上采样,多复制几遍负样本,也就是给予较多的权重)
基于错误分类的样本,给予权重的放大缩小,以使其分类正确。
样本的权重(其实是损失函数的系数):
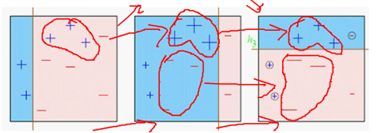
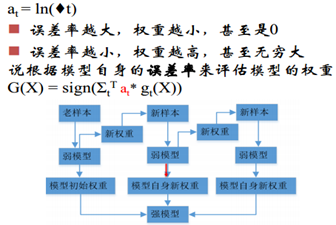
新的分类器必须是在上一个分类器上表现最差,与上一个分类器不一样,这样才能改进上一个学习器,否者没有什么作用,而二分类问题,表现最差的情况就是拍脑袋分类1/2概率,从而求解权重un. 这种方式求解u过麻烦,因而就有了下图中,构造一种递推的方式。


模型的权重:
误差率越小,模型权重越高,也就是说如果一个模型能把所有的都分对,那我们就给予一个很高的权重。

梯度下降理解Adaboost:
要求解的仍然是增加的新学习器的g(x)和模型权重at
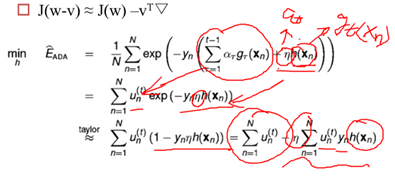
求解h(x),最优解就是h(x)=gt

求解η,最优解就是模型权重at
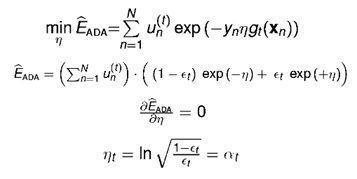
四、集成学习
精英制是加了权重之后再投票。

偏差是算法可能预测出一系列的值,取平均,与真实结果的偏离。方差是训练集数据的变化对学习结果的影响。如果说一个模型偏差高,则是欠拟合;如果说一个模型方差高,则是过拟合。一个模型的误差是由方差、偏差和噪声共同构成。

损失函数,adaboost基学习器的损失还是是0-1损失函数,只是前面加了权重,集成学习器的损失函数为指数损失函数;CART也可以看做集成学习器,看成是每一个树桩的集成学习。

Adaboost\GBDT\GBRT\组合算法的更多相关文章
- 机器学习总结(一) Adaboost,GBDT和XGboost算法
一: 提升方法概述 提升方法是一种常用的统计学习方法,其实就是将多个弱学习器提升(boost)为一个强学习器的算法.其工作机制是通过一个弱学习算法,从初始训练集中训练出一个弱学习器,再根据弱学习器的表 ...
- 排列组合算法(PHP)
用php实现的排列组合算法.使用递归算法,效率低,胜在简单易懂.可对付元素不多的情况. //从$input数组中取$m个数的组合算法 function comb($input, $m) { if($m ...
- C#语法灵活运用之排列组合算法
今天群里有朋友求一个排列组合算法,题目是给定长度,输出所有指定字母的组合. 如指定字母a.b.c.d.e.f,长度为2,则结果应为:aa.ab.ac ... ef.ff. 有朋友给出算法,很有特色: ...
- JAVA-- M选N的组合算法
M选N的组合算法 只要每个数字出现一次就可以 举例 :也就是说123与321和213属于重复 只算一组 此算法已经排除了重复数据 应用--彩票的注数算法 本程序的思路是开一个数组b,其长度 ...
- Lua版组合算法
高效率的排列组合算法--<编程珠矶>--Lua实现 原文链接 原文是python实现的,这里给出lua版本的实现 组合算法 本程序的思路是开一个数组,其下标表示1到m个数,数组元素 ...
- 基于C#程序设计语言的三种组合算法
目录 基于C#程序设计语言的三种组合算法 1. 总体思路 1.1 前言 1.2 算法思路 1.3 算法需要注意的点 2. 三种组合算法 2.1 普通组合算法 2.2 与自身进行组合的组合算法 2.3 ...
- python实现高效率的排列组合算法-乾颐堂
组合算法 本程序的思路是开一个数组,其下标表示1到m个数,数组元素的值为1表示其下标 代表的数被选中,为0则没选中. 首先初始化,将数组前n个元素置1,表示第一个组合为前n个数. 然后从左到右扫描数组 ...
- 提升学习算法简述:AdaBoost, GBDT和XGBoost
1. 历史及演进 提升学习算法,又常常被称为Boosting,其主要思想是集成多个弱分类器,然后线性组合成为强分类器.为什么弱分类算法可以通过线性组合形成强分类算法?其实这是有一定的理论基础的.198 ...
- 基于Adaboost的人脸检测算法
AdaBoost算法是一种自适应的Boosting算法,基本思想是选取若干弱分类器,组合成强分类器.根据人脸的灰度分布特征,AdaBoost选用了Haar特征[38].AdaBoost分类器的构造过程 ...
随机推荐
- 项目游戏开发日记 No.0x000006(Finish)
项目开发的最后一周! 突然一下就把游戏收尾了, 就像一个嘎然而止的乐章, 留下的, 是无尽的回味. 余音绕梁的夜晚, 也还想着, 拼命码代码的日子, 和还留在嘴里回味的烈酒的浓香. ————————— ...
- WinCE项目应用之车载导航
WinCE车载导航系统是我过去几年投入精力比较多的一个项目.我的主要工作内容是BSP的移植.硬件模块的调试和WinCE系统的深度定制.如TDA7415驱动.TDA7415均衡器.慧翰车载蓝牙模块.华为 ...
- java基础学习03(java基础程序设计)
java基础程序设计 一.完成的目标 1. 掌握java中的数据类型划分 2. 8种基本数据类型的使用及数据类型转换 3. 位运算.运算符.表达式 4. 判断.循环语句的使用 5. break和con ...
- 内网劫持渗透新姿势:MITMf简要指南
声明:本文具有一定攻击性,仅作为技术交流和安全教学之用,不要用在除了搭建环境之外的环境. 0×01 题记 又是一年十月一,想到小伙伴们都纷纷出门旅游,皆有美酒佳人相伴,想到这里,不禁潸然泪下.子曰:& ...
- Linux进程学习
进程与进程管理: 清屏:system("clear"); //#include <signal.h> 进程环境与进程属性: 什么是进程:简单的说,进程就是程序的一次执行 ...
- [LeetCode] Remove Duplicate Letters 移除重复字母
Given a string which contains only lowercase letters, remove duplicate letters so that every letter ...
- [LeetCode] Maximum Gap 求最大间距
Given an unsorted array, find the maximum difference between the successive elements in its sorted f ...
- IRandomAccessStream, IBuffer, Stream, byte[] 之间相互转换
/* * 用于实现 IRandomAccessStream, IBuffer, Stream, byte[] 之间相互转换的帮助类 */ using System;using System.IO;us ...
- BP神经网络原理及python实现
[废话外传]:终于要讲神经网络了,这个让我踏进机器学习大门,让我读研,改变我人生命运的四个字!话说那么一天,我在乱点百度,看到了这样的内容: 看到这么高大上,这么牛逼的定义,怎么能不让我这个技术宅男心 ...
- sql server中对xml进行操作
一.前言 SQL Server 2005 引入了一种称为 XML 的本机数据类型.用户可以创建这样的表,它在关系列之外还有一个或多个 XML 类型的列:此外,还允许带有变量和参数.为了更好地支持 XM ...