Spark 2.0
Apache Spark 2.0: Faster, Easier, and Smarter
http://blog.madhukaraphatak.com/categories/spark-two/
https://amplab.cs.berkeley.edu/technical-preview-of-apache-spark-2-0-easier-faster-and-smarter/
Dataset - New Abstraction of Spark
For long, RDD was the standard abstraction of Spark.
But from Spark 2.0, Dataset will become the new abstraction layer for spark. Though RDD API will be available, it will become low level API, used mostly for runtime and library development. All user land code will be written against the Dataset abstraction and it’s subset Dataframe API.
2.0中,最关键的是在RDD这个low level抽象层上,又加了一组DataSet的high level的抽象层,让用户可以跟方便的开发
From Definition, ” A Dataset is a strongly typed collection of domain-specific objects that can be transformed in parallel using functional or relational operations. Each dataset also has an untyped view called a DataFrame, which is a Dataset of Row. “
which sounds similar to RDD definition
” RDD represents an immutable,partitioned collection of elements that can be operated on in parallel “
Dataset is a superset of Dataframe API which is released in Spark 1.3.
Dataframe是一种特殊化的Dataset,Dataframe = Dataset[row]
SparkSession - New entry point of Spark
In earlier versions of spark, spark context was entry point for Spark. As RDD was main API, it was created and manipulated using context API’s. For every other API,we needed to use different contexts.For streaming, we needed StreamingContext, for SQL sqlContext and for hive HiveContext. But as DataSet and Dataframe API’s are becoming new standard API’s we need an entry point build for them. So in Spark 2.0, we have a new entry point for DataSet and Dataframe API’s called as Spark Session.
因为有了新的抽象层,所以需要加新的入口,SparkSession
就像RDD对应于SparkContext
更强大的SQL支持
On the SQL side, we have significantly expanded the SQL capabilities of Spark, with the introduction of a new ANSI SQL parser and support for subqueries.
Spark 2.0 can run all the 99 TPC-DS queries, which require many of the SQL:2003 features.
Tungsten 2.0
Spark 2.0 ships with the second generation Tungsten engine.
This engine builds upon ideas from modern compilers and MPP databases and applies them to data processing.
The main idea is to emit optimized bytecode at runtime that collapses the entire query into a single function, eliminating virtual function calls and leveraging CPU registers for intermediate data. We call this technique “whole-stage code generation.”
在内存管理和基于CPU的性能优化上,faster
Structured Streaming
Spark 2.0’s Structured Streaming APIs is a novel way to approach streaming.
It stems from the realization that the simplest way to compute answers on streams of data is to not having to reason about the fact that it is a stream.
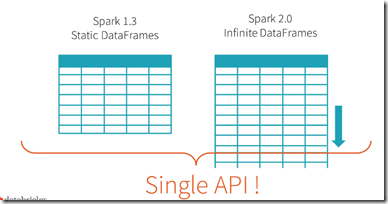
意思就是说,不要意识到流,流就是个无限的DataFrames
这个是典型的spark的思路,batch是一切的根本,和Flink截然相反
Spark 2.0的更多相关文章
- Spark 1.0.0 横空出世 Spark on Yarn 部署(Hadoop 2.4)
就在昨天,北京时间5月30日20点多.Spark 1.0.0最终公布了:Spark 1.0.0 released 依据官网描写叙述,Spark 1.0.0支持SQL编写:Spark SQL Progr ...
- APACHE SPARK 2.0 API IMPROVEMENTS: RDD, DATAFRAME, DATASET AND SQL
What’s New, What’s Changed and How to get Started. Are you ready for Apache Spark 2.0? If you are ju ...
- Apache Spark 3.0 将内置支持 GPU 调度
如今大数据和机器学习已经有了很大的结合,在机器学习里面,因为计算迭代的时间可能会很长,开发人员一般会选择使用 GPU.FPGA 或 TPU 来加速计算.在 Apache Hadoop 3.1 版本里面 ...
- spark 2.0.0集群安装与hive on spark配置
1. 环境准备: JDK1.8 hive 2.3.4 hadoop 2.7.3 hbase 1.3.3 scala 2.11.12 mysql5.7 2. 下载spark2.0.0 cd /home/ ...
- Spark 2.0 PCA主成份分析
PCA在Spark2.0中用法比较简单,只需要设置: .setInputCol(“features”)//保证输入是特征值向量 .setOutputCol(“pcaFeatures”)//输出 .se ...
- Apache Spark 2.0三种API的传说:RDD、DataFrame和Dataset
Apache Spark吸引广大社区开发者的一个重要原因是:Apache Spark提供极其简单.易用的APIs,支持跨多种语言(比如:Scala.Java.Python和R)来操作大数据. 本文主要 ...
- Spark 2.0 DataFrame map操作中Unable to find encoder for type stored in a Dataset.问题的分析与解决
转载:http://blog.csdn.net/sparkexpert/article/details/52871000 随着新版本的spark已经逐渐稳定,最近拟将原有框架升级到spark 2.0. ...
- Spark 2.0.0 SPARK-SQL returns NPE Error
com.esotericsoftware.kryo.KryoException: java.lang.NullPointerExceptionSerialization trace:underlyin ...
- Apache Spark 3.0 预览版正式发布,多项重大功能发布
2019年11月08日 数砖的 Xingbo Jiang 大佬给社区发了一封邮件,宣布 Apache Spark 3.0 预览版正式发布,这个版本主要是为了对即将发布的 Apache Spark 3. ...
随机推荐
- 如何在Eclipse中查看Android源码或者第三方组件包源码
文章出处:http://blog.csdn.net/cjjky/article/details/6535426 在学习过程中如果经常阅读源码,理解程度会比较深,学习效率也会比较高,那么如何方便快捷的阅 ...
- poj 1935(树形dp)
题目链接:http://poj.org/problem?id=1935 思路:首先我们考虑从源点出发到所有自己想要经过的点然后在回到源点sum,显然每条边都必须经过源点(这个我们可以一次dfs求出), ...
- 使用pm2常见问题
一.日志 1.pm2 的log怎么查看?(安装pm2后默认日志的路径为~/.pm2/),可以通过pm2 show (name)来查看某个进程下的日志地址 2.修改日志的输出路径,通过写一个程序启动的配 ...
- hdu 5762 Teacher Bo 曼哈顿路径
Teacher Bo Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)Tota ...
- extjs 2.0获取选中的radio的值
var temp=winFormPanel.getForm().findField('selectedType').getGroupValue();
- BZOJ3867 : Nice boat
每个点最多被修改$O(\log n)$次,线段树记录区间最值暴力更新. #include<cstdio> #define N 262145 int T,n,m,i,op,c,d,p,s[N ...
- 在本地(Eclipse)运行第一个strom-starter例子
一.在Eclipse中建立storm项目: 具体步骤如下: 1.在Eclipse中新建java project项目并导入jar包: File-> New -> Java Project - ...
- 达成成就:排名和AC数相同
233333 纪念一下.(268会不会是幸运数字呢0.0
- 【BZOJ】2818: Gcd(欧拉函数/莫比乌斯)
http://www.lydsy.com/JudgeOnline/problem.php?id=2818 我很sb的丢了原来做的一题上去.. 其实这题可以更简单.. 设 $$f[i]=1+2 \tim ...
- Checkbox的选中删除功能且Ajax返回后清除所选行
转摘:http://javaweb1024.com/qianduan/jQuery/2015/04/13/544.html 功能描述:多选框勾选以后(全部或者部分),需要想后台提交已勾选的数据(Aja ...