explain查看sql执行计划
http://www.cnblogs.com/wolf-sun/p/5291563.html
一该命令作用:该命令会向您展示查询是如何被执行的。
1、各个项的含义:https://blog.csdn.net/wuseyukui/article/details/71512793

2、id表示查询序列号,三种情况。规则是:序号不同,则越大越先被执行;序号相同,则越在前面的越先被执行。大前原则。
(1)查询序列号都相同。SQL的执行顺序从上到下。即先主键表,后外键表。这里是先查询村寨,再查询楼栋,最后查询房间。房间的外键是楼栋的主键,楼栋的外键是村寨的主键。

(2)查询序列号都不相同。如果是子查询语句,则id序列号递增,id越大则越先执行。
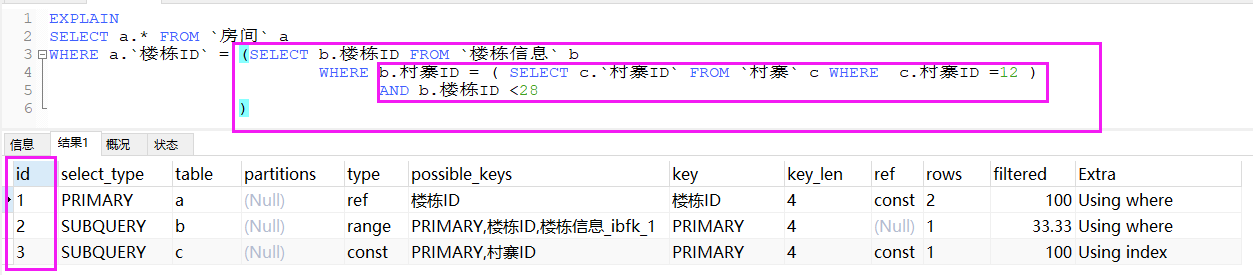
(3)查询序列号都不相同。
3、select_type字段。
(1)simple:简单的select查询,查询中不包含子查询或者union;
(2)primary:查询中包含任何复杂的子部分,最外层查询则被标记为primary;
(3)subquery:在select 或 where列表中包含了子查询;
(4)derived:在from列表中包含的子查询被标记为derived(衍生),mysql或递归执行这些子查询,把结果放在零时表里;
(5)union:若第二个select出现在union之后,则被标记为union;若union包含在from子句的子查询中,外层select将被标记为derived;
(6)union result:从union表获取结果的select;
4、type字段。
(1)system;
(2)const;
(3)eq_ref;
(4)ref ;
(5)fulltext;
(6)ref_or_null;
(7)index_merge ;
(8)unique_subquery ;
(9)index_subquery ;
(10)range ;
(11)index ;
(12)all;
5、key字段。实际使用的索引,如果为NULL,则没有使用索引。
2、id表示查询序列号,三种情况。
2、id表示查询序列号,三种情况。
2、id表示查询序列号,三种情况。
2、id表示查询序列号,三种情况。
2、id表示查询序列号,三种情况。
###########################################################
Explain 作用
Explain 提供了 MySQL 如何执行 SQL 语句的信息,通过这些信息,可以对 SQL 语句做相应的优化,提高执行效率。
Explain 使用
调用 Explain,只需要在 SQL 语句前添加 explain 关键字即可。
一般情况下,添加 explain 关键字后,认为 MySQL 不会执行查询,但是如果在 from 子句中包含子查询,那么 MySQL 实际上会执行子查询,将其子查询的结果放在一个临时表中,然后完成外层查询优化。
MySQL 5.6 之前的版本,只允许解释 select 语句,从 MySQL 5.6 开始,非 select 语句也可以被解释了。
Explain 字段
调用 Explain 后,MySQL 会返回一行或者多行记录,通过这些记录就可以知道 SQL 语句的执行情况了。
每行记录都包含了以下几个字段
- id:执行编号,标识 select 所属的行
- select_type:select 查询的类型
- table:查询的是哪个表
- partitions:匹配的分区
- type:关联类型,或者访问类型
- possible_keys:该查询可以选用的索引
- key:该查询选用的索引
- key_len:索引中使用的字节数
- ref:显示上述表的连接匹配条件,即哪些列或常量被用于查询索引列上的值
- rows:估计为了找到所需行而要读取的行数
- filtered:按表条件过滤的行的百分比
- Extra:额外的信息
Explain 字段详解
id
该列总是包含一个编号,标识 select 所属的行。如果语句当中没有子查询或联合查询,那么只会有唯一的 select,于是每一行在这个列中都将显示一个 1。否则,内层的 select 语句一般会顺序编号,对应于原始语句中的位置。
id 值越大,越先执行。
select_type
该列指明了查询的类型,以下为常见的取值
- SIMPLLE:简单查询,该查询不包含 UNION 或子查询
- PRIMARY:如果查询包含 UNION 或子查询,则最外层的查询被标识为 PRIMARY
- UNION:表示此查询是 UNION 中的第二个或者随后的查询
- DEPENDENT:UNION 满足 UNION 中的第二个或者随后的查询,其次取决于外面的查询
- UNION RESULT:UNION 的结果
- SUBQUERY:子查询中的第一个 select 语句
- DEPENDENT SUBQUERY:子查询中的 第一个 select,同时取决于外面的查询
- DERIVED:派生表 select,包含在 from 字句的子查询中的查询
- UNCACHEABLE SUBQUERY:满足是子查询中的第一个 select 语句,同时意味着 select 中的某些特性阻止结果被缓存于一个 Item_cache 中
- UNCACHEABLE UNION:满足此查询是 UNION 中的第二个或者随后的查询,同时意味着 select 中的某些特性阻止结果被缓存于一个 Item_cache 中
table
该列显示了对应行正在访问哪个表,或者该表的别名。
partitions
记录将与查询匹配的分区,非分区表的值为NULL。
type
该列称为关联类型或者访问类型,它指明了 MySQL 决定如何查找表中符合条件的行,同时为判断查询是否高效提供了重要的依据。
以下为常见的取值
- ALL:全表扫描,这个类型是性能最差的查询之一。通常来说,我们的查询不应该出现 ALL 类型,因为这样的查询,在数据量最大的情况下,对数据库的性能是巨大的灾难。
- index:全索引扫描,和 ALL 类型类似,只不过 ALL 类型是全表扫描,而 index 类型是扫描全部的索引,主要优点是避免了排序,但是开销仍然非常大。如果在 Extra 列看到 Using index,说明正在使用覆盖索引,只扫描索引的数据,它比按索引次序全表扫描的开销要少很多。
- range:范围扫描,就是一个有限制的索引扫描,它开始于索引里的某一点,返回匹配这个值域的行。这个类型通常出现在 =、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN、IN() 的操作中,key 列显示使用了哪个索引,当 type 为该值时,则输出的 ref 列为 NULL,并且 key_len 列是此次查询中使用到的索引最长的那个。
- ref:一种索引访问,也称索引查找,它返回所有匹配某个单个值的行。此类型通常出现在多表的 join 查询, 针对于非唯一或非主键索引, 或者是使用了最左前缀规则索引的查询。
- eq_ref:使用这种索引查找,最多只返回一条符合条件的记录。在使用唯一性索引或主键查找时会出现该值,非常高效。
- const、system:该表至多有一个匹配行,在查询开始时读取,或者该表是系统表,只有一行匹配。其中 const 用于在和 primary key 或 unique 索引中有固定值比较的情形。
- NULL:在执行阶段不需要访问表。
该列取不同值的执行效率依次是
ALL < index < range < ref < eq_ref < const < system < NULL
一般来说,至少要保证查询达到 range 级别,最好能达到 ref 级别。
possible_keys
该列显示了查询可以选用哪些索引,但是列出来的索引,可能对于后续优化过程是没有用的。
key
该列显示了查询选用了哪个索引,如果该索引没有出现在 possible_keys 列中,那么选用它可能出于另外的原因,比如,它可能选择了一个覆盖索引。
key_len
该列显示了在索引里使用的字节数,当 key 列的值为 NULL 时,则该列也是 NULL。如果正在使用的只是索引里的某些列,那么可以通过用该列的值算出来具体是哪些列。
ref
该列显示了哪些字段或者常量被用来和 key 配合从表中查询记录出来。
rows
该列显示了估计要找到所需的行而要读取的行数,这个值是个估计值,原则上值越小越好。
filtered
该列表示根据条件过滤的表行的估计百分比,和 rows 相乘,表示和查询计划里前一个表关联的行数。
Extra
该列显示了有关 MySQL 如何解析查询的其它信息。
以下为常见的取值
- Using index:使用覆盖索引,表示查询索引就可查到所需数据,不用扫描表数据文件,往往说明性能不错。
- Using Where:在存储引擎检索行后再进行过滤,使用了 where 从句来限制哪些行将与下一张表匹配或者是返回给用户。
- Using temporary:在查询结果排序时会使用一个临时表,一般出现于排序、分组和多表 join 的情况,查询效率不高,建议优化。
- Using filesort:对结果使用一个外部索引排序,而不是按索引次序从表里读取行,一般有出现该值,都建议优化去掉,因为这样的查询 CPU 资源消耗大。
注意事项
Explain 不会告诉你触发器、存储过程或用户自定义函数对查询的影响情况;
Explain 不会告诉你 MySQL 在查询执行中所做的特定优化;
Explain 只是个近似结果;
Explain 不会显示关于查询的执行计划的所有信息。
###########################################
ID SELECT命令的序号(通常为1,子查询的话往往从序号2开始)
select_type
SIMPLE 单纯的SELECT命令
PRIMARY 最外层的SELECT命令
UNION 由UNION语句连接的SELECT命令
DEPENDENT UNION 由UNION语句连接的SELECT命令(依赖外部查询)
SUBQUERY 子查询中的SELECT命令
DEPENDENT SUBQUERY 子查询中的SELECT命令(依赖外部查询)
DERIVED 派生表(FROM语句的子查询)
Table 表名
type
表的连接类型(按效率的高低排序)
system 只存在一条记录的表(=系统表)
const 常量,拥有PRIMARY KEY/UNIQUE制约的索引(结果总为1行)
eq_ref 连接时由PRIMARY KEY/UNIQUE列进行的等值查询
ref 非UNIQUE列进行的等值查询
ref_or_null ref中加入了[~OR列名IS NULL]的检索
range 使用索引检查一定范围的记录(=,<>,>,>=,<,<=,IS NULL,<>,BETWEEN,IN等运算符)
index 全索引扫描
ALL 全表扫描
possible keys 检索时可能使用到的索引(不存在索引时为NULL)
key 检索时真实使用到的索引(未使用索引时为NULL)
key_len 使用的索引的关键字长度(单位为bytes)
Ref 需要时与比较的列,或者定制(const)
rows 需要遍历的记录数量
Extra 查询时的追加信息 (值为index时,使用了覆盖索引,性能最好)
explain查看sql执行计划的更多相关文章
- EXPLAIN 查看 SQL 执行计划
EXPLAIN 查看 SQL 执行计划.分析索引的效率: id:id 列数字越大越先执行: 如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. ...
- Oracle查看SQL执行计划的方式
Oracle查看SQL执行计划的方式 获取Oracle sql执行计划并查看执行计划,是掌握和判断数据库性能的基本技巧.下面案例介绍了多种查看sql执行计划的方式: 基本有以下几种方式: ...
- 查看SQL执行计划
一用户进入某界面慢得要死,查看SQL执行计划如下(具体SQL语句就不完全公布了,截断的如下): call count cpu elapsed disk ...
- plsql中查看sql执行计划
想要优化sql语句,可以从sql执行计划入手. 在plsql客户端,提供了一个方便的按钮来查看执行计划 选中需要查看的sql语句,点击此按钮,就可以看到该条语句的执行计划了. 结果集包括描述,用户,对 ...
- 利用AWR 查看SQL 执行计划
在AWR中定位到问题SQL语句后想要了解该SQL statement的具体执行计划,于是就用AWR报告中得到的SQL ID去V$SQL等几个动态性能视图中查询,但发现V$SQL或V$SQL_PLAN视 ...
- PostgreSQL环境中查看SQL执行计划示例
explain analyze ,format,buffers, format :TEXT, XML, JSON, or YAML. EXPLAIN (ANALYZE,buffers,format ...
- 查看Oracle SQL执行计划的常用方式
在查看SQL执行计划的时候有很多方式 我常用的方式有三种 SQL> explain plan for 2 select * from scott.emp where ename='KING'; ...
- Oracle之SQL优化专题01-查看SQL执行计划的方法
在我2014年总结的"SQL Tuning 基础概述"中,其实已经介绍了一些查看SQL执行计划的方法,但是不够系统和全面,所以本次SQL优化专题,就首先要系统的介绍一下查看SQL执 ...
- MySql 的SQL执行计划查看,判断是否走索引
在select窗口中,执行以下语句: set profiling =1; -- 打开profile分析工具show variables like '%profil%'; -- 查看是否生效show p ...
随机推荐
- CSS 让 fontawesome 图标字体变细
一句 CSS 让 fontawesome 图标字体变细 自从 iOS 某个版本发布之后,前端的流行趋势是什么都越来越细…字体越来越细…图标线条也越来越细.而老物 fontawesome 粗壮的线条风格 ...
- iOS 面试题整理(带答案)二
第一篇面试题整理: http://www.cocoachina.com/bbs/read.php?tid-459620.html 本篇面试题同样:如答案有问题,欢迎指正! 1.回答person的ret ...
- Unity3D笔记 英保通七 物理引擎
给球体添加刚体RigidBody和球体碰撞器Sphere Collider 效果: OnTriggerEnter() 代码 using UnityEngine; using System.Collec ...
- hdu2586(LCA最近公共祖先)
How far away ? Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) T ...
- python3之装饰器修复技术@wraps
普通函数 def f(): """ 这是一个用来测试装饰器修复技术的函数 """ print("哈哈哈") if __n ...
- [分布式系统学习]阅读笔记 Distributed systems for fun and profit 之一 基本概念
因为工作的原因,最近打算看一些分布式学习的资料.其中这个http://book.mixu.net/distsys/就是一篇非常适合分布式入门的介绍. 这个短小的材料有下面5个小的章节,图文并茂,也没有 ...
- 洛谷P2414 阿狸的打字机【AC自动机】【fail树】【dfs序】【树状数组】
居然真的遇上了这种蔡队题.瑟瑟发抖. 题目背景 阿狸喜欢收藏各种稀奇古怪的东西,最近他淘到一台老式的打字机. 题目描述 打字机上只有28个按键,分别印有26个小写英文字母和'B'.'P'两个字母.经阿 ...
- nowcoder2018年全国多校算法寒假训练营练习比赛(第一场)
[气死我了 写完了博客发布 点看来一看怎么只剩下一半不到的内容了!!!!!!!!!!] [就把卡的那两道放上来好了 其余的不弄了 生气!!!!!] 可以说是很久没有打比赛了 今天这一场主要是 基础算 ...
- 一套准确率高且效率高的分词、词性标注工具-thulac
软件简介 THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能.THU ...
- easyui-combo个人实例
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...