scrapy框架系列 (1) 初识scrapy
Scrapy 框架
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图(绿线是数据流向):
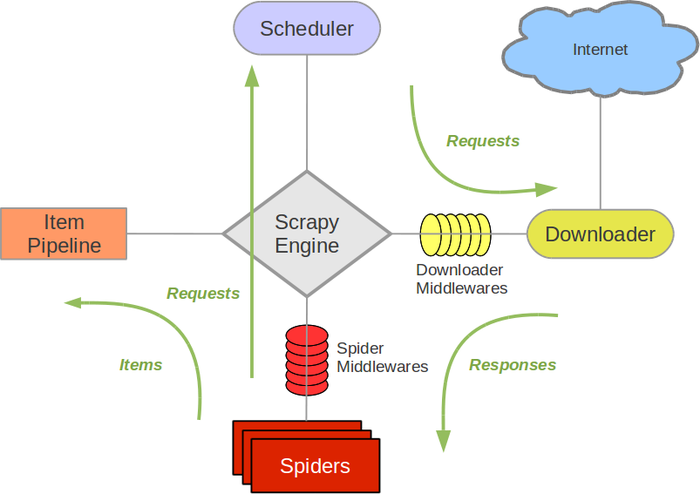
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
代码写好,程序开始运行...
引擎:Hi!Spider, 你要处理哪一个网站?Spider:老大要我处理xxxx.com。引擎:你把第一个需要处理的URL给我吧。Spider:给你,第一个URL是xxxxxxx.com。引擎:Hi!调度器,我这有request请求你帮我排序入队一下。调度器:好的,正在处理你等一下。引擎:Hi!调度器,把你处理好的request请求给我。调度器:给你,这是我处理好的request引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。管道``调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
scrapy框架系列 (1) 初识scrapy的更多相关文章
- scrapy框架系列 (5) Spider类
Spider Spider类定义了如何爬取某个(或某些)网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item). 换句话说,Spider就是您定义爬取的动作及 ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- scrapy爬虫系列之开头--scrapy知识点
介绍:Scrapy是一个为了爬取网站数据.提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速抓取.Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度. 0.说明: ...
- Scrapy框架——安装以及新建scrapy文件
一.安装 conda install Scrapy :之后在按y 表示允许安装相关的依赖库(下载速度慢的话也可以借助镜像源),安装的前提是安装了anaconda作为python , 测试scr ...
- SpringMVC 框架系列之初识与入门实例
微信公众号:compassblog 欢迎关注.转发,互相学习,共同进步! 有任何问题,请后台留言联系! 1.SpringMVC 概述 (1). MVC:Model-View-Control Contr ...
- scrapy框架系列 (4) Scrapy Shell
Scrapy Shell Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据 ...
- scrapy框架系列 (3) Item Pipline
item pipeline 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item. 每个Item Pipeline ...
- scrapy框架系列 (2) 一个简单案例
学习目标 创建一个Scrapy项目 定义提取的结构化数据(Item) 编写爬取网站的 Spider 并提取出结构化数据(Item) 编写 Item Pipelines 来存储提取到的Item(即结构化 ...
随机推荐
- SpringMVC中使用Ajax POST请求以json格式传递参数服务端通过request.getParameter("name")无法获取参数值问题分析
SpringMVC中使用Ajax POST请求以json格式传递参数服务端通过request.getParameter("name")无法获取参数值问题分析 一:问题demo展示 ...
- SOAP port
To determine the SOAP port on WebSphere Base: Server Types > WebSphere application servers > [ ...
- 用python做一个图片验证码
看一下做出来的验证码长啥样 验证码分析 1. 有很多点 2. 有很多线条 3. 有字母,有数字 需要用到的模块: 1. random 2. Pillow (python3中使用pillow) 安装p ...
- 折腾一天安装Centos7,以及后面恢复Win7引导的曲折历程
一.下载centos 7 livecd iso 访问镜像网站,http://mirrors.aliyun.com/centos/7.0.1406/isos/x86_64/ 或者直接下载:http:// ...
- DEX文件类型和虚拟机(摘抄)
DEX文件类型是Android平台上可执行文件的类型. Dalvik是Google公司自己设计用于Android平台的Java虚拟机.Dalvik虚拟机是Google等厂商合作开发的Android移动 ...
- UVALive 6916 Punching Robot dp
Punching Robot 题目连接: https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid= ...
- UVALive 6889 City Park 并查集
City Park 题目连接: http://acm.hust.edu.cn/vjudge/contest/view.action?cid=122283#problem/F Description P ...
- ARM Cortex Design Considerations for Debug
JTAG was the traditional mechanism for debug connections for ARM7/9 parts, but with the Cortex-M fam ...
- GoDaddy Linux主机支持机房的更换
GoDaddy Linux主机支持机房的更换 http://godaddy.idcspy.com/godaddy-change-data-center GoDaddy推出中文界面后,小编发现虚拟主机有 ...
- Revit Family API 找到实体某一方向上的面。
PlanarFace.Normal取得向量.IsAlmostEqualTo判断向量是否一致. // ================================================== ...