scrapy框架系列 (1) 初识scrapy
Scrapy 框架
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图(绿线是数据流向):
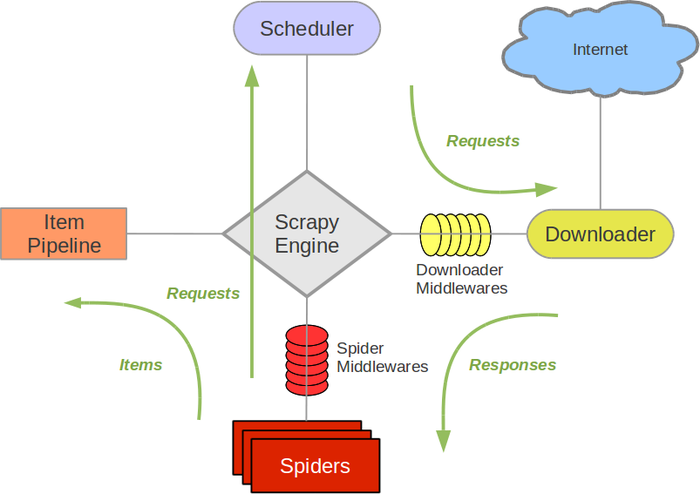
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
代码写好,程序开始运行...
引擎:Hi!Spider, 你要处理哪一个网站?Spider:老大要我处理xxxx.com。引擎:你把第一个需要处理的URL给我吧。Spider:给你,第一个URL是xxxxxxx.com。引擎:Hi!调度器,我这有request请求你帮我排序入队一下。调度器:好的,正在处理你等一下。引擎:Hi!调度器,把你处理好的request请求给我。调度器:给你,这是我处理好的request引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。管道``调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
scrapy框架系列 (1) 初识scrapy的更多相关文章
- scrapy框架系列 (5) Spider类
Spider Spider类定义了如何爬取某个(或某些)网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item). 换句话说,Spider就是您定义爬取的动作及 ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- scrapy爬虫系列之开头--scrapy知识点
介绍:Scrapy是一个为了爬取网站数据.提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速抓取.Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度. 0.说明: ...
- Scrapy框架——安装以及新建scrapy文件
一.安装 conda install Scrapy :之后在按y 表示允许安装相关的依赖库(下载速度慢的话也可以借助镜像源),安装的前提是安装了anaconda作为python , 测试scr ...
- SpringMVC 框架系列之初识与入门实例
微信公众号:compassblog 欢迎关注.转发,互相学习,共同进步! 有任何问题,请后台留言联系! 1.SpringMVC 概述 (1). MVC:Model-View-Control Contr ...
- scrapy框架系列 (4) Scrapy Shell
Scrapy Shell Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据 ...
- scrapy框架系列 (3) Item Pipline
item pipeline 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item. 每个Item Pipeline ...
- scrapy框架系列 (2) 一个简单案例
学习目标 创建一个Scrapy项目 定义提取的结构化数据(Item) 编写爬取网站的 Spider 并提取出结构化数据(Item) 编写 Item Pipelines 来存储提取到的Item(即结构化 ...
随机推荐
- 我希望我知道的七个JavaScript技巧
如果你是一个JavaScript新手或仅仅最近才在你的开发工作中接触它,你可能感到沮丧.所有的语言都有自己的怪癖(quirks)——但从基于强类型的服务器端语言转移过来的开发人员可能会感到困惑.我就曾 ...
- BZOJ2671 : Calc
设$d=\gcd(a,b),a=xd,b=yd$,则$a+b|ab$等价于$x+y|xyd$. 因为$x,y$互质,所以$x+y|d$. 假设$x<y$,那么对于固定的$x,y$,有$\lflo ...
- B+/-Tree原理
B-Tree介绍 B-Tree是一种多路搜索树(并不是二叉的): 1.定义任意非叶子结点最多只有M个儿子:且M>2: 2.根结点的儿子数为[2, M]: 3. ...
- HDU 5745 La Vie en rose 暴力
La Vie en rose 题目连接: http://acm.hdu.edu.cn/showproblem.php?pid=5745 Description Professor Zhang woul ...
- hdu 5734 Acperience 水题
Acperience 题目连接: http://acm.hdu.edu.cn/showproblem.php?pid=5734 Description Deep neural networks (DN ...
- oracle创建透明网关出现的问题
解决方案:创建HS_TRANSACTION_LOG表 DROP TABLE HS_TRANSACTION_LOG go CREATE TABLE HS_TRANSACTION_LOG( GLOBAL_ ...
- SLAM(一)----学习资料整理
转自:http://www.cnblogs.com/wenhust/ 书籍: 1.必读经典 Thrun S, Burgard W, Fox D. <Probabilistic robotics& ...
- Jedis使用总结【pipeline】【分布式的id生成器】【分布式锁【watch】【multi】】【redis分布式】(转)
前段时间细节的了解了Jedis的使用,Jedis是redis的java版本的客户端实现.本文做个总结,主要分享如下内容: [pipeline][分布式的id生成器][分布式锁[watch][multi ...
- [Deepin 15] 编译安装 PHP-5.6.30
先看下历史笔记: Ubuntu 14 编译安装 PHP 5.4.45 + Nginx 1.4.7 + MySQL 5.6.26 笔记 ################################# ...
- [Go] 跨平台文件系统监控工具 fsnotify 应用举例
项目地址:https://github.com/fsnotify/fsnotify fsnotify 能监控指定文件夹内 文件的修改情况,如 文件的 增加.删除.修改.重命名等操作. 官方给出了以下注 ...