Kafka:架构简介【转】
转:http://www.cnblogs.com/f1194361820/p/6026313.html
Kafka 架构简介
Kafka是一个开源的、分布式的、可分区的、可复制的基于日志提交的发布订阅消息系统。它具备以下特点:
·消息持久化: 为了从大数据中获取有价值的信息,任何信息的丢失都是负担不起的。Kafka使用了O(1)的磁盘结构设计,这样做即便是在要存储大体积的数据时也是可以提供稳定的性能。使用Kafka时,message会被存储并且会被复制以防止数据丢失。
·高吞吐量: 设计是工作在普通的硬件设施上多个客户端能够每秒处理几百兆的数据量。
·分布式: Kafka Broker的中心化集群支持消息分区,而consumer采用分布式进行消费。
·种多Client支持: Kafka很容易与其它平台进行支持,例如:Java、.NET、PHP、Ruby、Python。
·实时: 消息由producer产生后立即对consumer可见。这个特性对于基于事件的系统是很关键的。
下面就来对Kafka架构做一个简单的说明:
Kafka各组件说明
Broker
每个kafka server称为一个Broker,多个borker组成kafka cluster。

一个机器上可以部署一个或者多个Broker,这多个Broker连接到相同的ZooKeeper就组成了Kafka集群。
Topic
Kafka是一个发布订阅消息系统,它的逻辑结构如下:

Topic 就是消息类别名,一个topic中通常放置一类消息。每个topic都有一个或者多个订阅者,也就是消息的消费者consumer。
Producer将消息推送到topic,由订阅该topic的consumer从topic中拉取消息。
Topic 与broker
一个Broker上可以创建一个或者多个Topic。同一个topic可以在同一集群下的多个Broker中分布。

Partition log
Kafka会为每个topic维护了多个分区(partition),每个分区会映射到一个逻辑的日志(log)文件:
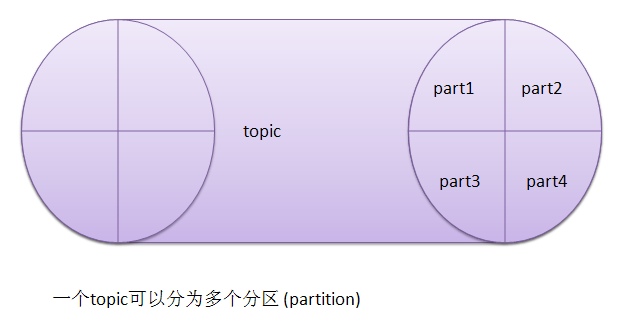
每当一个message被发布到一个topic上的一个partition,broker应会将该message追加到这个逻辑log文件的最后一个segment上。这些segments 会被flush到磁盘上。Flush时可以按照时间来进行,也可以按照message 数来执行。
每个partition都是一个有序的、不可变的结构化的提交日志记录的序列。在每个partition中每一条日志记录都会被分配一个序号——通常称为offset,offset在partition内是唯一的。论点逻辑文件会被化分为多个文件segment(每个segment的大小一样的)。
Broker集群将会保留所有已发布的message records,不管这些消息是否已被消费。保留时间依赖于一个可配的保留周期。例如:如果设置了保留策略是2day,那么每一条消息发布两天内是被保留的,在这个2day的保留时间内,消息是可以被消费的。过期后不再保留。
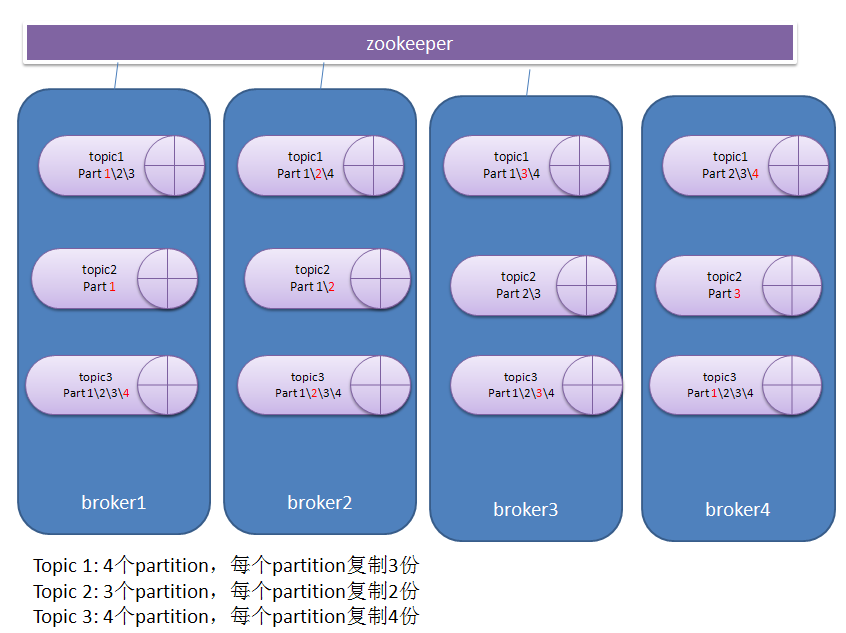
Partition distribution
日志分区是分布式的存在于一个kafka集群的多个broker上。每个partition会被复制多份存在于不同的broker上。这样做是为了容灾。具体会复制几份,会复制到哪些broker上,都是可以配置的。经过相关的复制策略后,每个topic在每个broker上会驻留一到多个partition。如图:
如果要了解kafka如何进行partition、replica 分配的,可以参考:
http://www.cnblogs.com/yurunmiao/p/5550906.html
对于同一个partition,它所在任何一个broker,都有能扮演两种角色:leader、follower。
看上面的例子。红色的代表是一个leader。
对于topic1的4个partition:
Part 1的leader是broker1,followers是broker2\3。
Part2的leader是broker2,followers是broker1\4。
Part3的leader是broker3,followers是broker1\3。
Part4的leader是broker4,followers是broker2\3。
对于topic2的3个partition:
Part1的leader是broker1,followers是broker2。
Part2的leader是broker2,followers是broker3。
Part3的leader是broker3,followers是broker4。
对于topic2的4个partition:
Part 1的leader是broker4,followers是broker1\2\3。
Part2的leader是broker2,followers是broker1\3\4。
Part3的leader是broker3,followers是broker1\2\4。
Part4的leader是broker1,followers是broker2\3\4。
下面是一个真实的例子:

图中的partition 0 的leader是broker 2,它有3个replicas:2,1,3。
In-Sync Replica:在同步中,也就是有哪些broker正处理同步中。partition 0的ISR是2,1,3,说明了3个replica都是正常状态。如果有一个broker down,那么它就不会在ISR中出现。
之后把broker1停止后:

每个partition的Leader的用于处理到该partition的读写请求的。
每个partition的followers是用于异步的从它的leader中复制数据的。
Kafka会动态维护一个与Leader保持一致的同步副本(in-sync replicas (ISR))集合,并且会将最新的同步副本(ISR )集合持久化到zookeeper。如果leader出现问题了,就会从该partition的followers中选举一个作为新的leader。
所以呢,在一个kafka集群中,每个broker通常会扮演两个角色:在一个partition中扮演leader,在其它的partition中扮演followers。Leader是最繁忙的,要处理读写请求。这样将leader均分到不同的broker上,目的自然是要确保负载均衡。
Producer
Producer作为消息的生产者,在生产完消息后需要将消息投送到指定的目的地(某个topic的某个partition)。Producer可以根据指定选择partition的算法或者是随机方式来选择发布消息到哪个partition。
Consumer
在Kafka中,同样有consumer group的概念,它是逻辑上将一些consumer分组。因为每个kafka consumer是一个进程。所以一个consumer group中的consumers将可能是由分布在不同机器上的不同的进程组成的。Topic中的每一条消息可以被多个consumer group消费,然而每个consumer group内只能有一个consumer来消费该消息。所以,如果想要一条消息被多个consumer消费,那么这些consumer就必须是在不同的consumer group中。所以也可以理解为consumer group才是topic在逻辑上的订阅者。
每个consumer可以订阅多个topic。
每个consumer会保留它读取到某个partition的offset。而consumer 是通过zookeeper来保留offset的。
Kafka提供的保障
1、如果producer往特定的partition发送消息时,会按照先后顺序存储,也就是说如果发送顺序是message1、message2、message3。那么这三个消息在partition log中的记录的offset就是 message1_offset < message2_offset < message3_offset。
2、consumer也是有序的浏览log中的记录。
3、如果一个topic指定了replication factor为N,那么就允许有N-1个Broker出错。
架构图
对上述各组件介绍后,现在就应该可以很容易的理解Kafka的架构图:

Kafka:架构简介【转】的更多相关文章
- 转 kafka架构简介
kafka架构 转 http://www.cnblogs.com/chushiyaoyue/p/5612298.html 相关文章: https://www.jianshu.com/p/6233d53 ...
- Kafka架构简介
一.kafka的架构 1.Broker kafka集群包含一个或者多个服务器,这种服务器就叫做Broker 2.Topic 每条发布到kafka集群的消息都有一个类别,这个类别就叫做Topic(逻辑上 ...
- Kafka 探险 - 架构简介
Kafka 探险 - 架构简介 这个 Kafka 的专题,我会从系统整体架构,设计到代码落地.和大家一起杠源码,学技巧,涨知识.希望大家持续关注一起见证成长! 我相信:技术的道路,十年如一日!十年磨一 ...
- kafka原理简介并且与RabbitMQ的选择
kafka原理简介并且与RabbitMQ的选择 kafka原理简介,rabbitMQ介绍,大致说一下区别 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和 ...
- 替代Flume——Kafka Connect简介
我们知道过去对于Kafka的定义是分布式,分区化的,带备份机制的日志提交服务.也就是一个分布式的消息队列,这也是他最常见的用法.但是Kafka不止于此,打开最新的官网. 我们看到Kafka最新的定义是 ...
- 最简单流处理引擎——Kafka Streaming简介
Kafka在0.10.0.0版本以前的定位是分布式,分区化的,带备份机制的日志提交服务.而kafka在这之前也没有提供数据处理的顾服务.大家的流处理计算主要是还是依赖于Storm,Spark Stre ...
- Kafka Connect简介
Kafka Connect简介 http://colobu.com/2016/02/24/kafka-connect/#more Kafka 0.9+增加了一个新的特性Kafka Connect,可以 ...
- Kafka架构和原理深度剖析
Kafka简介 Kafka是一种分布式的,基于发布/订阅的消息系统.主要设计目标如下: 以时间复杂度为O(1)的方式提供消息持久化能力,并保证即使对TB级以上数据也能保证常数时间的访问性能 高吞吐率. ...
- LoadRunner系统架构简介
1.LoadRunner系统架构简介 LoadRunner是通过创建虚拟用户来代替真实实际用户来操作客户端软件比如Internet Explorer,来向IIS.Apache等Web服务器发送HTTP ...
随机推荐
- linux获取精准进程PID之pgrep命令
pgrep 是通过程序的名字来查询进程的工具,一般是用来判断程序是否正在运行.在服务器的配置和管理中,这个工具常被应用,简单明了. 用法: #pgrep [选项] [程序名] pgrep [-flvx ...
- 简述MVC
强调:mvc不是框架而是一种设计模式 分层结构的好处:1.降低了代码之间的耦合性 2.提高了代码的重用性 一. 概述 MVC的全名Model View Controller,即模型-视图-控制器的缩写 ...
- protobuf3 iOS 接入 protobuf
1.引入官方基础pod 谷歌将protobuf需要使用的基础类封装成了一个pod,因此可以直接安装该pod,不必再手工导入. 如下: pod "Protobuf", :git =& ...
- 保证java的jar包在后台运行
nohup java -jar XX.jar >temp.text &
- Eclipse中Ant的配置与测试
在Eclipse中使用Ant Ant是Java平台下非常棒的批处理命令执行程序,能非常方便地自动完成编译,测试,打包,部署等等一系列任务,大大提高开发效率.如果你现在还没有开始使用Ant,那就要赶快开 ...
- MySQL -- 全文检索(查询扩展检索)
通常用在查询的关键词太短,用户需要隐含知识进行扩展.例如,查单词database时,用户可能还希望不仅仅包含database的文档,可能还指包含mysql.oracle.db2等单词.这时就需要查询扩 ...
- 高级Unix命令
在Unix操作中有太多太多的命令,这些命令的强大之处就是一个命令只干一件事,并把这件事干好.Do one thing, do it well.这是unix的哲学.而且Unix首创的管道可以把这些命令任 ...
- Nginx错误提示:504 Gateway Time-out解决方法
朋友说504 Gateway Time-out的错误提示与nginx本身是没有任何关系的我们可以通过fastcgi配置参数的调整进行解 决. 修改 php-fpm 配置文件: 1.把 max_chil ...
- php中array_merge合并数组详解
如果键名有重复,该键的键值为最后一个键名对应的值(后面的覆盖前面的).如果数组是数字索引的,则键名会以连续方式重新索引. 注释:如果仅仅向 array_merge() 函数输入了一个数组,且键名是整数 ...
- 第2章 Python基础-字符编码&数据类型 字符编码&字符串 练习题
1.简述位.字节的关系 位(bit)是计算机中最小的表示单元,数据传输是以“位”为单位的,1bit缩写为1b 字节(Byte)是计算机中最小的存储单位,1Byte缩写为1B 8bit = 1Byte ...