基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(一)
系列文章
- 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目
- 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来
- 基于 abp vNext 和 .NET Core 开发博客项目 - 完善与美化,Swagger登场
- 基于 abp vNext 和 .NET Core 开发博客项目 - 数据访问和代码优先
- 基于 abp vNext 和 .NET Core 开发博客项目 - 自定义仓储之增删改查
- 基于 abp vNext 和 .NET Core 开发博客项目 - 统一规范API,包装返回模型
- 基于 abp vNext 和 .NET Core 开发博客项目 - 再说Swagger,分组、描述、小绿锁
- 基于 abp vNext 和 .NET Core 开发博客项目 - 接入GitHub,用JWT保护你的API
- 基于 abp vNext 和 .NET Core 开发博客项目 - 异常处理和日志记录
- 基于 abp vNext 和 .NET Core 开发博客项目 - 使用Redis缓存数据
- 基于 abp vNext 和 .NET Core 开发博客项目 - 集成Hangfire实现定时任务处理
- 基于 abp vNext 和 .NET Core 开发博客项目 - 用AutoMapper搞定对象映射
- 基于 abp vNext 和 .NET Core 开发博客项目 - 定时任务最佳实战(一)
- 基于 abp vNext 和 .NET Core 开发博客项目 - 定时任务最佳实战(二)
- 基于 abp vNext 和 .NET Core 开发博客项目 - 定时任务最佳实战(三)
从本篇就开始博客页面的接口开发了,其实这些接口我是不想用文字来描述的,太枯燥太无趣了。全是CRUD,谁还不会啊,用得着我来讲吗?想想为了不半途而废,为了之前立的Flag,还是咬牙坚持吧。
准备工作
现在博客数据库中的数据是比较混乱的,为了看起来像那么回事,显得正式一点,我先手动搞点数据进去。
搞定了种子数据,就可以去愉快的写接口了,我这里将根据我现在的博客页面去分析所需要接口,感兴趣的去点点。
为了让接口看起来清晰,一目了然,删掉之前在IBlogService中添加的所有接口,将5个自定义仓储全部添加至BlogService中,然后用partial修饰。
//IBlogService.cs
public partial interface IBlogService
{
}
//BlogService.cs
using Meowv.Blog.Application.Caching.Blog;
using Meowv.Blog.Domain.Blog.Repositories;
namespace Meowv.Blog.Application.Blog.Impl
{
public partial class BlogService : ServiceBase, IBlogService
{
private readonly IBlogCacheService _blogCacheService;
private readonly IPostRepository _postRepository;
private readonly ICategoryRepository _categoryRepository;
private readonly ITagRepository _tagRepository;
private readonly IPostTagRepository _postTagRepository;
private readonly IFriendLinkRepository _friendLinksRepository;
public BlogService(IBlogCacheService blogCacheService,
IPostRepository postRepository,
ICategoryRepository categoryRepository,
ITagRepository tagRepository,
IPostTagRepository postTagRepository,
IFriendLinkRepository friendLinksRepository)
{
_blogCacheService = blogCacheService;
_postRepository = postRepository;
_categoryRepository = categoryRepository;
_tagRepository = tagRepository;
_postTagRepository = postTagRepository;
_friendLinksRepository = friendLinksRepository;
}
}
}
在Blog文件夹下依次添加接口:IBlogService.Post.cs、IBlogService.Category.cs、IBlogService.Tag.cs、IBlogService.FriendLink.cs、IBlogService.Admin.cs。
在Blog/Impl文件夹下添加实现类:IBlogService.Post.cs、BlogService.Category.cs、BlogService.Tag.cs、BlogService.FriendLink.cs、BlogService.Admin.cs。
同上,.Application.Caching层也按照这个样子添加。
注意都需要添加partial修饰为局部的接口和实现类,所有文章相关的接口放在IBlogService.Post.cs中,分类放在IBlogService.Category.cs,标签放在IBlogService.Tag.cs,友链放在IBlogService.FriendLink.cs,后台增删改所有接口放在IBlogService.Admin.cs,最终效果图如下:
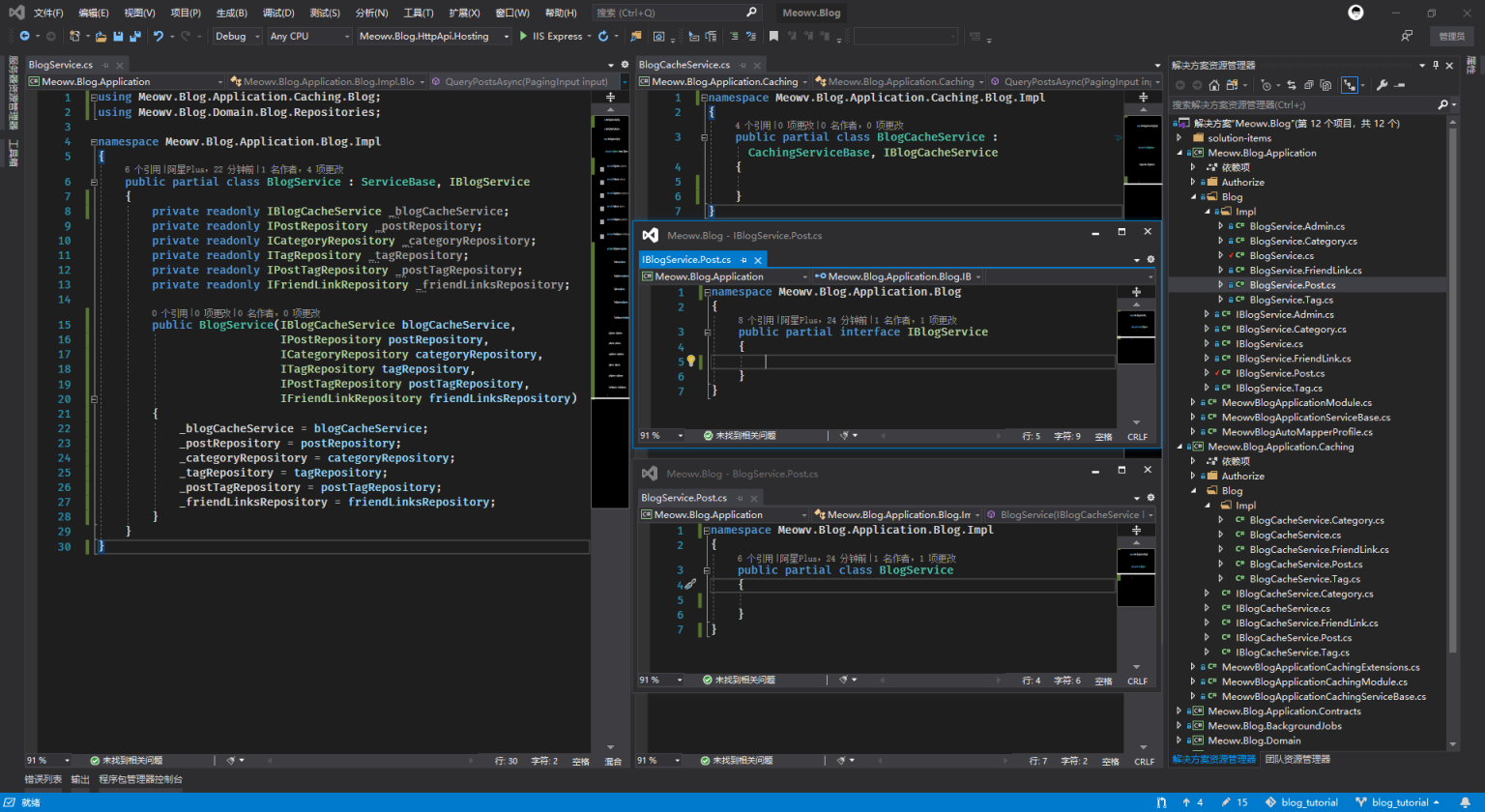
文章列表页
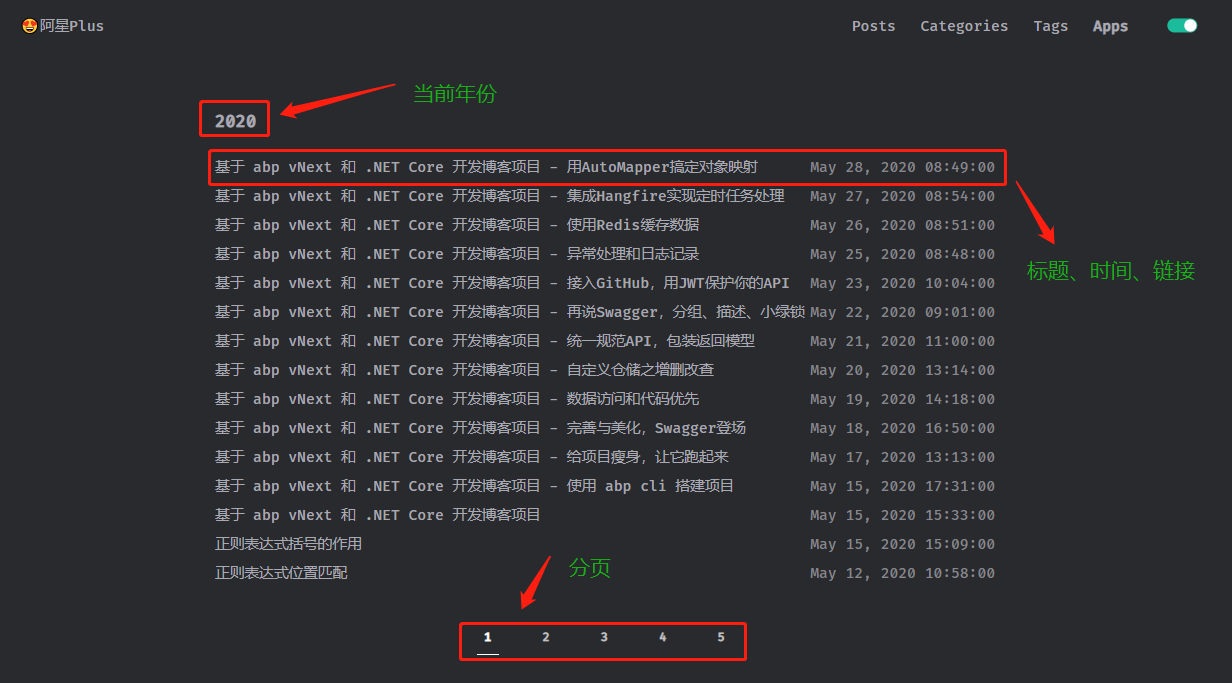
分析:列表带分页,以文章发表的年份分组,所需字段:标题、链接、时间、年份。
在.Application.Contracts层Blog文件夹下添加返回的模型:QueryPostDto.cs。
//QueryPostDto.cs
using System.Collections.Generic;
namespace Meowv.Blog.Application.Contracts.Blog
{
public class QueryPostDto
{
/// <summary>
/// 年份
/// </summary>
public int Year { get; set; }
/// <summary>
/// Posts
/// </summary>
public IEnumerable<PostBriefDto> Posts { get; set; }
}
}
模型为一个年份和一个文章列表,文章列表模型:PostBriefDto.cs。
//PostBriefDto.cs
namespace Meowv.Blog.Application.Contracts.Blog
{
public class PostBriefDto
{
/// <summary>
/// 标题
/// </summary>
public string Title { get; set; }
/// <summary>
/// 链接
/// </summary>
public string Url { get; set; }
/// <summary>
/// 年份
/// </summary>
public int Year { get; set; }
/// <summary>
/// 创建时间
/// </summary>
public string CreationTime { get; set; }
}
}
搞定,因为返回时间为英文格式,所以CreationTime 给了字符串类型。
在IBlogService.Post.cs中添加接口分页查询文章列表QueryPostsAsync,肯定需要接受俩参数分页页码和分页数量。还是去添加一个公共模型PagingInput吧,在.Application.Contracts下面。
//PagingInput.cs
using System.ComponentModel.DataAnnotations;
namespace Meowv.Blog.Application.Contracts
{
/// <summary>
/// 分页输入参数
/// </summary>
public class PagingInput
{
/// <summary>
/// 页码
/// </summary>
[Range(1, int.MaxValue)]
public int Page { get; set; } = 1;
/// <summary>
/// 限制条数
/// </summary>
[Range(10, 30)]
public int Limit { get; set; } = 10;
}
}
Page设置默认值为1,Limit设置默认值为10,Range Attribute设置参数可输入大小限制,于是这个分页查询文章列表的接口就是这个样子的。
//IBlogService.Post.cs
public partial interface IBlogService
{
/// <summary>
/// 分页查询文章列表
/// </summary>
/// <param name="input"></param>
/// <returns></returns>
Task<ServiceResult<PagedList<QueryPostDto>>> QueryPostsAsync(PagingInput input);
}
ServiceResult和PagedList是之前添加的统一返回模型,紧接着就去添加一个分页查询文章列表缓存接口,和上面是对应的。
//IBlogCacheService.Post.cs
using Meowv.Blog.Application.Contracts;
using Meowv.Blog.Application.Contracts.Blog;
using Meowv.Blog.ToolKits.Base;
using System;
using System.Threading.Tasks;
namespace Meowv.Blog.Application.Caching.Blog
{
public partial interface IBlogCacheService
{
/// <summary>
/// 分页查询文章列表
/// </summary>
/// <param name="input"></param>
/// <param name="factory"></param>
/// <returns></returns>
Task<ServiceResult<PagedList<QueryPostDto>>> QueryPostsAsync(PagingInput input, Func<Task<ServiceResult<PagedList<QueryPostDto>>>> factory);
}
}
分别实现这两个接口。
//BlogCacheService.Post.cs
public partial class BlogCacheService
{
private const string KEY_QueryPosts = "Blog:Post:QueryPosts-{0}-{1}";
/// <summary>
/// 分页查询文章列表
/// </summary>
/// <param name="input"></param>
/// <param name="factory"></param>
/// <returns></returns>
public async Task<ServiceResult<PagedList<QueryPostDto>>> QueryPostsAsync(PagingInput input, Func<Task<ServiceResult<PagedList<QueryPostDto>>>> factory)
{
return await Cache.GetOrAddAsync(KEY_QueryPosts.FormatWith(input.Page, input.Limit), factory, CacheStrategy.ONE_DAY);
}
}
//BlogService.Post.cs
/// <summary>
/// 分页查询文章列表
/// </summary>
/// <param name="input"></param>
/// <returns></returns>
public async Task<ServiceResult<PagedList<QueryPostDto>>> QueryPostsAsync(PagingInput input)
{
return await _blogCacheService.QueryPostsAsync(input, async () =>
{
var result = new ServiceResult<PagedList<QueryPostDto>>();
var count = await _postRepository.GetCountAsync();
var list = _postRepository.OrderByDescending(x => x.CreationTime)
.PageByIndex(input.Page, input.Limit)
.Select(x => new PostBriefDto
{
Title = x.Title,
Url = x.Url,
Year = x.CreationTime.Year,
CreationTime = x.CreationTime.TryToDateTime()
}).GroupBy(x => x.Year)
.Select(x => new QueryPostDto
{
Year = x.Key,
Posts = x.ToList()
}).ToList();
result.IsSuccess(new PagedList<QueryPostDto>(count.TryToInt(), list));
return result;
});
}
PageByIndex(...)、TryToDateTime()是.ToolKits层添加的扩展方法,先查询总数,然后根据时间倒序,分页,筛选出所需字段,根据年份分组,输出,结束。
在BlogController中添加API。
/// <summary>
/// 分页查询文章列表
/// </summary>
/// <param name="input"></param>
/// <returns></returns>
[HttpGet]
[Route("posts")]
public async Task<ServiceResult<PagedList<QueryPostDto>>> QueryPostsAsync([FromQuery] PagingInput input)
{
return await _blogService.QueryPostsAsync(input);
}
[FromQuery]设置input为从URL进行查询参数,编译运行看效果。
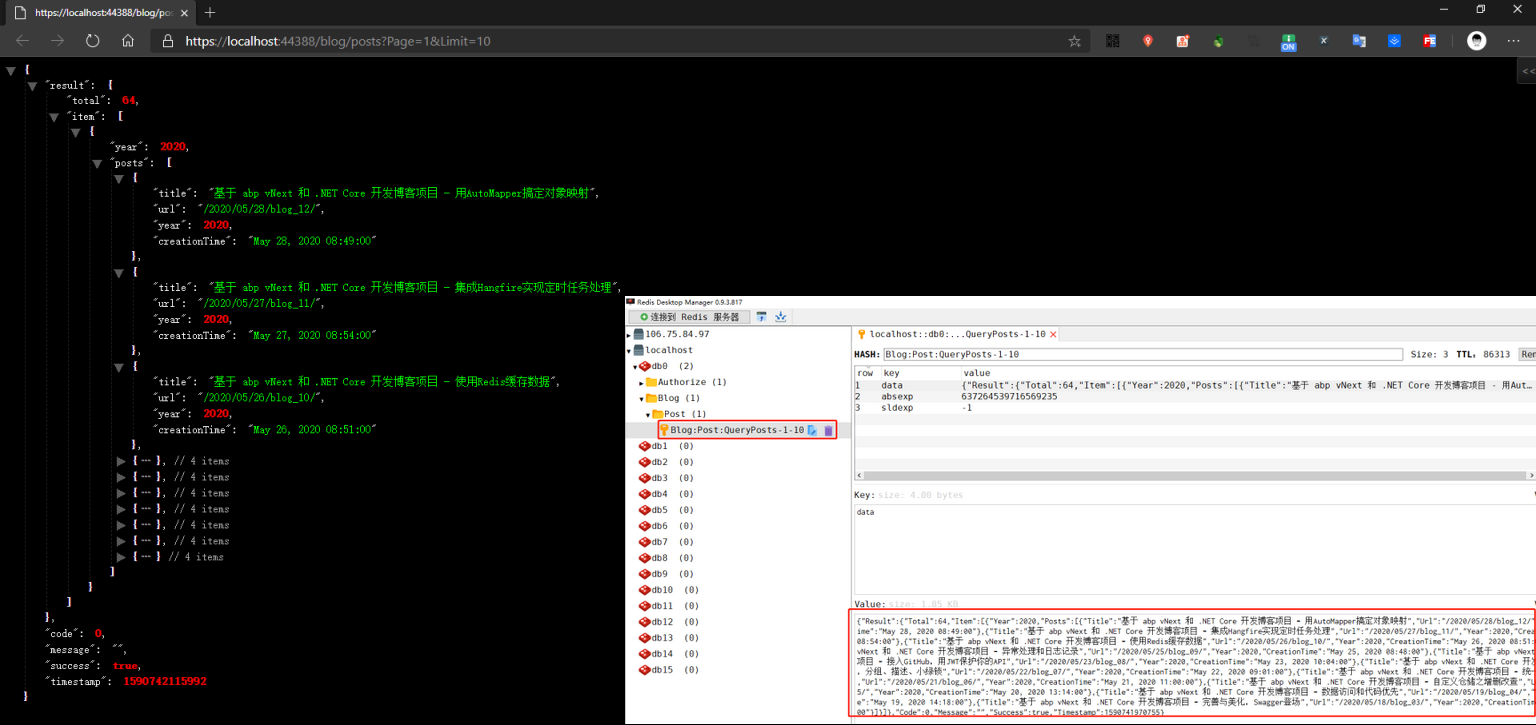
已经可以查询出数据,并且缓存至Redis中。
获取文章详情
分析:文章详情页,文章的标题、作者、发布时间、所属分类、标签列表、文章内容(HTML和MarkDown)、链接、上下篇的标题和链接。
创建返回模型:PostDetailDto.cs
//PostDetailDto.cs
using System.Collections.Generic;
namespace Meowv.Blog.Application.Contracts.Blog
{
public class PostDetailDto
{
/// <summary>
/// 标题
/// </summary>
public string Title { get; set; }
/// <summary>
/// 作者
/// </summary>
public string Author { get; set; }
/// <summary>
/// 链接
/// </summary>
public string Url { get; set; }
/// <summary>
/// HTML
/// </summary>
public string Html { get; set; }
/// <summary>
/// Markdown
/// </summary>
public string Markdown { get; set; }
/// <summary>
/// 创建时间
/// </summary>
public string CreationTime { get; set; }
/// <summary>
/// 分类
/// </summary>
public CategoryDto Category { get; set; }
/// <summary>
/// 标签列表
/// </summary>
public IEnumerable<TagDto> Tags { get; set; }
/// <summary>
/// 上一篇
/// </summary>
public PostForPagedDto Previous { get; set; }
/// <summary>
/// 下一篇
/// </summary>
public PostForPagedDto Next { get; set; }
}
}
同时添加CategoryDto、TagDto、PostForPagedDto。
//CategoryDto.cs
namespace Meowv.Blog.Application.Contracts.Blog
{
public class CategoryDto
{
/// <summary>
/// 分类名称
/// </summary>
public string CategoryName { get; set; }
/// <summary>
/// 展示名称
/// </summary>
public string DisplayName { get; set; }
}
}
//TagDto.cs
namespace Meowv.Blog.Application.Contracts.Blog
{
public class TagDto
{
/// <summary>
/// 标签名称
/// </summary>
public string TagName { get; set; }
/// <summary>
/// 展示名称
/// </summary>
public string DisplayName { get; set; }
}
}
//PostForPagedDto.cs
namespace Meowv.Blog.Application.Contracts.Blog
{
public class PostForPagedDto
{
/// <summary>
/// 标题
/// </summary>
public string Title { get; set; }
/// <summary>
/// 链接
/// </summary>
public string Url { get; set; }
}
}
添加获取文章详情接口和缓存的接口。
//IBlogService.Post.cs
public partial interface IBlogService
{
/// <summary>
/// 根据URL获取文章详情
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
Task<ServiceResult<PostDetailDto>> GetPostDetailAsync(string url);
}
//IBlogCacheService.Post.cs
public partial interface IBlogCacheService
{
/// <summary>
/// 根据URL获取文章详情
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
Task<ServiceResult<PostDetailDto>> GetPostDetailAsync(string url, Func<Task<ServiceResult<PostDetailDto>>> factory);
}
分别实现这两个接口。
//BlogCacheService.Post.cs
public partial class BlogCacheService
{
private const string KEY_GetPostDetail = "Blog:Post:GetPostDetail-{0}";
/// <summary>
/// 根据URL获取文章详情
/// </summary>
/// <param name="url"></param>
/// <param name="factory"></param>
/// <returns></returns>
public async Task<ServiceResult<PostDetailDto>> GetPostDetailAsync(string url, Func<Task<ServiceResult<PostDetailDto>>> factory)
{
return await Cache.GetOrAddAsync(KEY_GetPostDetail.FormatWith(url), factory, CacheStrategy.ONE_DAY);
}
}
//BlogService.Post.cs
/// <summary>
/// 根据URL获取文章详情
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
public async Task<ServiceResult<PostDetailDto>> GetPostDetailAsync(string url)
{
return await _blogCacheService.GetPostDetailAsync(url, async () =>
{
var result = new ServiceResult<PostDetailDto>();
var post = await _postRepository.FindAsync(x => x.Url.Equals(url));
if (null == post)
{
result.IsFailed(ResponseText.WHAT_NOT_EXIST.FormatWith("URL", url));
return result;
}
var category = await _categoryRepository.GetAsync(post.CategoryId);
var tags = from post_tags in await _postTagRepository.GetListAsync()
join tag in await _tagRepository.GetListAsync()
on post_tags.TagId equals tag.Id
where post_tags.PostId.Equals(post.Id)
select new TagDto
{
TagName = tag.TagName,
DisplayName = tag.DisplayName
};
var previous = _postRepository.Where(x => x.CreationTime > post.CreationTime).Take(1).FirstOrDefault();
var next = _postRepository.Where(x => x.CreationTime < post.CreationTime).OrderByDescending(x => x.CreationTime).Take(1).FirstOrDefault();
var postDetail = new PostDetailDto
{
Title = post.Title,
Author = post.Author,
Url = post.Url,
Html = post.Html,
Markdown = post.Markdown,
CreationTime = post.CreationTime.TryToDateTime(),
Category = new CategoryDto
{
CategoryName = category.CategoryName,
DisplayName = category.DisplayName
},
Tags = tags,
Previous = previous == null ? null : new PostForPagedDto
{
Title = previous.Title,
Url = previous.Url
},
Next = next == null ? null : new PostForPagedDto
{
Title = next.Title,
Url = next.Url
}
};
result.IsSuccess(postDetail);
return result;
});
}
ResponseText.WHAT_NOT_EXIST是定义在MeowvBlogConsts.cs的常量。
TryToDateTime()和列表查询中的扩展方法一样,转换时间为想要的格式。
简单说一下查询逻辑,先根据参数url,查询是否存在数据,如果文章不存在则返回错误消息。
然后根据 post.CategoryId 就可以查询到当前文章的分类名称。
联合查询post_tags和tag两张表,指定查询条件post.Id,查询当前文章的所有标签。
最后上下篇的逻辑也很简单,上一篇取大于当前文章发布时间的第一篇,下一篇取时间倒序排序并且小于当前文章发布时间的第一篇文章。
最后将所有查询到的数据赋值给输出对象,返回,结束。
在BlogController中添加API。
/// <summary>
/// 根据URL获取文章详情
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
[HttpGet]
[Route("post")]
public async Task<ServiceResult<PostDetailDto>> GetPostDetailAsync(string url)
{
return await _blogService.GetPostDetailAsync(url);
}
编译运行,然后输入URL查询一条文章详情数据。
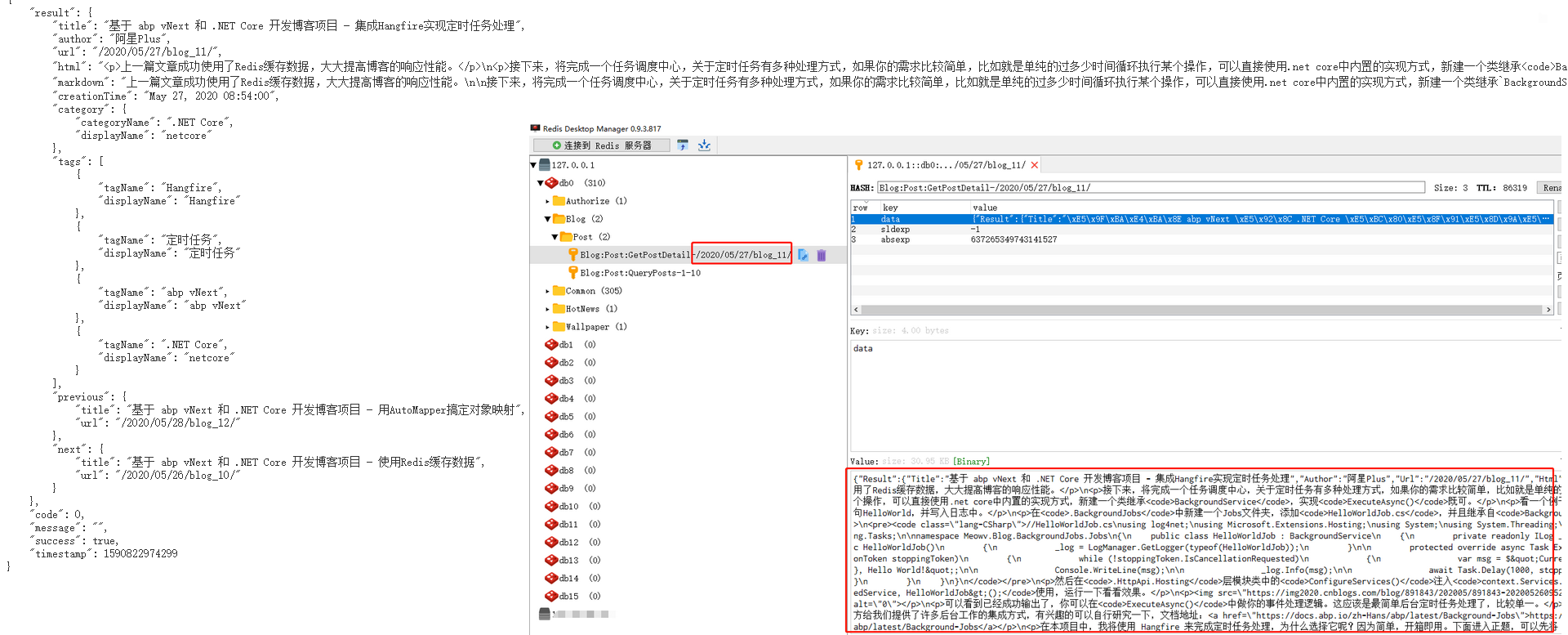
成功输出预期内容,缓存同时也是ok的。
开源地址:https://github.com/Meowv/Blog/tree/blog_tutorial
基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(一)的更多相关文章
- 基于 abp vNext 和 .NET Core 开发博客项目 - 定时任务最佳实战(三)
上一篇(https://www.cnblogs.com/meowv/p/12974439.html)完成了全网各大平台的热点新闻数据的抓取,本篇继续围绕抓取完成后的操作做一个提醒.当每次抓取完数据后, ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(二)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(三)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(四)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(五)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(一)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(二)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(三)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - Blazor 实战系列(四)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
随机推荐
- CSS的基础使用
一,css是什么? CSS全称为“层叠样式表” ,与HTML相辅相成,实现网页的排版布局与样式美化 二,CSS使用方式 1.行内样式/内联样式(单一页面中使用) 借助于style标签属性,为当前的标签 ...
- k近邻法(二)
上一篇文章讲了k近邻法,以及使用kd树构造数据结构,使得提高最近邻点搜索效率,但是这在数据点N 远大于 2^n 时可以有效的降低算法复杂度,n为数据点的维度,否则,由于需要向上回溯比较距离,使得实际效 ...
- IDEA打包JavaWeb项目
IDEA打包JavaWeb项目 步骤: 1.配置项目->2.Build Artifacts->3.找到.war文件 具体操作: 首先,单击顶部工具栏的“File”选项,在弹出选项中选择“P ...
- [hdu1028]整数拆分,生成函数
题意:给一个正整数n,求n的拆分方法数(不考虑顺序) 思路:不妨考虑用1~n来构成n.用多项式表示单个数所有能构成的数,用多项式表示,就相当于卷积运算了. 1 2 3 4 5 6 7 8 9 10 1 ...
- Android CodeReview 些许总结
CodeReview些许总结 1:使用Handler的时候,使用handler.post(Runnable);,hanler与类尽量保持弱引用关系,或者使用静态的handler对象 public Ha ...
- Amaze UI学习笔记——JS学习历程一
1.自定义事件 (1)一些组件提供了自定义事件,命名方式为{事件名称}.{组件名称}.amui,用户可以查看组件文档了解.使用这些事件,如: $('#myAlert').on('close.alert ...
- 格式转换工具:使用kgEncode转换压缩无损音乐
在kugou安装目录下,有kgEncode目录,可以在各种格式中相互转换
- 黑马程序员_毕向东_Java基础视频教程——类型转换(随笔)
类型转换 class Test{ public static void main(String[] args) { byte b = 3; // b = b + 2; /* Test.java:5: ...
- Python 图像处理 OpenCV (2):像素处理与 Numpy 操作以及 Matplotlib 显示图像
前文传送门: 「Python 图像处理 OpenCV (1):入门」 普通操作 1. 读取像素 读取像素可以通过行坐标和列坐标来进行访问,灰度图像直接返回灰度值,彩色图像则返回B.G.R三个分量. 需 ...
- Postman学习宝典(一)
前言:网上看到的比较好的Postman教程,既然已经有了,我就不重复造轮子了,直接copy过来. 资源来源于:米阳MeYoung Postman 入门1- 安装.变量.代理 简介 Postman 是一 ...