吴裕雄--天生自然 人工智能机器学习实战代码:线性判断分析LINEARDISCRIMINANTANALYSIS
import numpy as np
import matplotlib.pyplot as plt from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
from sklearn.model_selection import train_test_split
from sklearn import datasets, linear_model,discriminant_analysis def load_data():
# 使用 scikit-learn 自带的 iris 数据集
iris=datasets.load_iris()
X_train=iris.data
y_train=iris.target
return train_test_split(X_train, y_train,test_size=0.25,random_state=0,stratify=y_train) #线性判断分析LinearDiscriminantAnalysis
def test_LinearDiscriminantAnalysis(*data):
X_train,X_test,y_train,y_test=data
lda = discriminant_analysis.LinearDiscriminantAnalysis()
lda.fit(X_train, y_train)
print('Coefficients:%s, intercept %s'%(lda.coef_,lda.intercept_))
print('Score: %.2f' % lda.score(X_test, y_test)) # 产生用于分类的数据集
X_train,X_test,y_train,y_test=load_data()
# 调用 test_LinearDiscriminantAnalysis
test_LinearDiscriminantAnalysis(X_train,X_test,y_train,y_test)

def plot_LDA(converted_X,y):
'''
绘制经过 LDA 转换后的数据
:param converted_X: 经过 LDA转换后的样本集
:param y: 样本集的标记
'''
fig=plt.figure()
ax=Axes3D(fig)
colors='rgb'
markers='o*s'
for target,color,marker in zip([0,1,2],colors,markers):
pos=(y==target).ravel()
X=converted_X[pos,:]
ax.scatter(X[:,0], X[:,1], X[:,2],color=color,marker=marker,label="Label %d"%target)
ax.legend(loc="best")
fig.suptitle("Iris After LDA")
plt.show() def run_plot_LDA():
'''
执行 plot_LDA 。其中数据集来自于 load_data() 函数
'''
X_train,X_test,y_train,y_test=load_data()
X=np.vstack((X_train,X_test))
Y=np.vstack((y_train.reshape(y_train.size,1),y_test.reshape(y_test.size,1)))
lda = discriminant_analysis.LinearDiscriminantAnalysis()
lda.fit(X, Y)
converted_X=np.dot(X,np.transpose(lda.coef_))+lda.intercept_
plot_LDA(converted_X,Y) # 调用 run_plot_LDA
run_plot_LDA()

def test_LinearDiscriminantAnalysis_solver(*data):
'''
测试 LinearDiscriminantAnalysis 的预测性能随 solver 参数的影响
'''
X_train,X_test,y_train,y_test=data
solvers=['svd','lsqr','eigen']
for solver in solvers:
if(solver=='svd'):
lda = discriminant_analysis.LinearDiscriminantAnalysis(solver=solver)
else:
lda = discriminant_analysis.LinearDiscriminantAnalysis(solver=solver,shrinkage=None)
lda.fit(X_train, y_train)
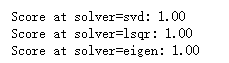
print('Score at solver=%s: %.2f' %(solver, lda.score(X_test, y_test))) # 调用 test_LinearDiscriminantAnalysis_solver
test_LinearDiscriminantAnalysis_solver(X_train,X_test,y_train,y_test)
def test_LinearDiscriminantAnalysis_shrinkage(*data):
'''
测试 LinearDiscriminantAnalysis 的预测性能随 shrinkage 参数的影响
'''
X_train,X_test,y_train,y_test=data
shrinkages=np.linspace(0.0,1.0,num=20)
scores=[]
for shrinkage in shrinkages:
lda = discriminant_analysis.LinearDiscriminantAnalysis(solver='lsqr',shrinkage=shrinkage)
lda.fit(X_train, y_train)
scores.append(lda.score(X_test, y_test))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(shrinkages,scores)
ax.set_xlabel(r"shrinkage")
ax.set_ylabel(r"score")
ax.set_ylim(0,1.05)
ax.set_title("LinearDiscriminantAnalysis")
plt.show()
# 调用 test_LinearDiscr
test_LinearDiscriminantAnalysis_shrinkage(X_train,X_test,y_train,y_test)

吴裕雄--天生自然 人工智能机器学习实战代码:线性判断分析LINEARDISCRIMINANTANALYSIS的更多相关文章
- 吴裕雄--天生自然 人工智能机器学习实战代码:ELASTICNET回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄--天生自然 人工智能机器学习实战代码:LASSO回归
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model from s ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据 import matplotlib import matplotlib.pyplot as plt from numpy import * xcord0 = [] ycord0 ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...
- 吴裕雄--天生自然python机器学习:机器学习简介
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息.例如 ,对于垃圾邮 件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅 以考察邮件长度及其他因素,人们 ...
- 吴裕雄--天生自然python机器学习:基于支持向量机SVM的手写数字识别
from numpy import * def img2vector(filename): returnVect = zeros((1,1024)) fr = open(filename) for i ...
随机推荐
- 吴裕雄--天生自然 JAVA开发学习: 循环结构
public class Test { public static void main(String args[]) { int x = 10; while( x < 20 ) { System ...
- teminal / console / shell
console从应用程序角度看的(控制台是管理员用的,唯一的) teminal从用户角度看的(终端是用户用的) 应用程序与console交互 用户与teminal交互 teminal可以不存在 tem ...
- Graph & Tree
图论学习笔记 TYQ图论真是个渣渣呢 所以TYQ决定猛补图论 好的从0x60开始 表示博客园不用Latex真的烦呢QAQ,公式难打的要命QAQ 0x60~0x62 最短路讲解跳过 最小生成树: Kru ...
- VS Code之Vue开发常用插件
Auto Close Tag 自动补全html标签 Auto Rename Tag 同步更改html尾标签 ESLint ESlint语法提示 settings.json 文件 "eslin ...
- Docker Compose文件详解 V2
Compose file reference 语法: web: build: ./web ports: - "5000:5000" volu ...
- 学习spring第一天
Spring第一天笔记 1. 说在前面 怎样的架构的程序,我们认为是一个优秀的架构? 我们考虑的标准:可维护性好,可扩展性好,性能. 什么叫可扩展性好? 答:就是可以做到,不断的增加代码,但是可以 ...
- 14 微服务电商【黑马乐优商城】:day03-springcloud(Hystix,Feign)
本项目的笔记和资料的Download,请点击这一句话自行获取. day01-springboot(理论篇) :day01-springboot(实践篇) day02-springcloud(理论篇一) ...
- 第一章:ESXi6.7虚拟化环境安装
1.1 硬件环境及镜像引导准备 1.1.1 硬件和系统资源 要安装ESXi6.7,硬件和系统资源必须满足下列要求: ESXi 6.7 要求主机至少具有两个 CPU 内核,生产环境中需要根据 ...
- springboot集成aop日志
日常开发中假如是前后端完全分离,我们会习惯用浏览器去调用controller的接口来测试.这一个过程普通的日志功能会记录sql参数等一些基本信息.但是假如项目越来越庞大,我们的包越来越多,在维护项目和 ...
- java静态方法和静态字段
public class Dog{ public static void main(String[]args){ A a= new A(); a.add(); //java实例对象可以访问类的静态方法 ...