吴裕雄--天生自然 人工智能机器学习实战代码:LASSO回归
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets, linear_model
from sklearn.model_selection import train_test_split def load_data():
diabetes = datasets.load_diabetes()
return train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0) #Lasso回归
def test_Lasso(*data):
X_train,X_test,y_train,y_test=data
regr = linear_model.Lasso()
regr.fit(X_train, y_train)
print('Coefficients:%s, intercept %.2f'%(regr.coef_,regr.intercept_))
print("Residual sum of squares: %.2f"% np.mean((regr.predict(X_test) - y_test) ** 2))
print('Score: %.2f' % regr.score(X_test, y_test)) # 产生用于回归问题的数据集
X_train,X_test,y_train,y_test=load_data()
# 调用 test_Lasso
test_Lasso(X_train,X_test,y_train,y_test) def test_Lasso_alpha(*data):
X_train,X_test,y_train,y_test=data
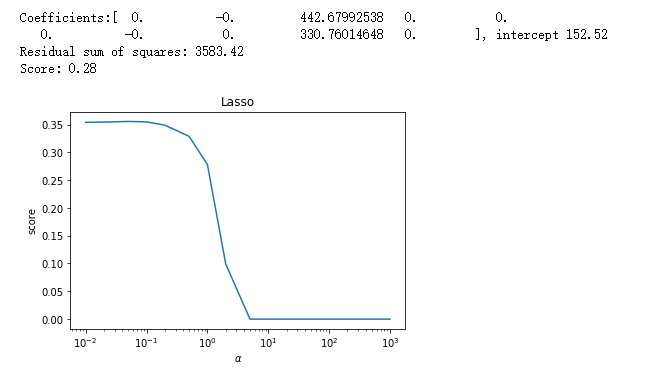
alphas=[0.01,0.02,0.05,0.1,0.2,0.5,1,2,5,10,20,50,100,200,500,1000]
scores=[]
for i,alpha in enumerate(alphas):
regr = linear_model.Lasso(alpha=alpha)
regr.fit(X_train, y_train)
scores.append(regr.score(X_test, y_test))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(alphas,scores)
ax.set_xlabel(r"$\alpha$")
ax.set_ylabel(r"score")
ax.set_xscale('log')
ax.set_title("Lasso")
plt.show() # 调用 test_Lasso_alpha
test_Lasso_alpha(X_train,X_test,y_train,y_test)
吴裕雄--天生自然 人工智能机器学习实战代码:LASSO回归的更多相关文章
- 吴裕雄--天生自然 人工智能机器学习实战代码:线性判断分析LINEARDISCRIMINANTANALYSIS
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄--天生自然 人工智能机器学习实战代码:ELASTICNET回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 吴裕雄--天生自然python机器学习:使用Logistic回归从疝气病症预测病马的死亡率
,除了部分指标主观和难以测量外,该数据还存在一个问题,数据集中有 30%的值是缺失的.下面将首先介绍如何处理数据集中的数据缺失问题,然 后 再 利 用 Logistic回 归 和随机梯度上升算法来预测 ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据 import matplotlib import matplotlib.pyplot as plt from numpy import * xcord0 = [] ycord0 ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...
- 吴裕雄--天生自然python机器学习:机器学习简介
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息.例如 ,对于垃圾邮 件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅 以考察邮件长度及其他因素,人们 ...
随机推荐
- P2P平台爆雷不断到底是谁的过错?
早在此前,范伟曾经在春晚上留下一句经典台词,"防不胜防啊".而将这句台词用在当下的P2P行业,似乎最合适不过了.就在这个炎热夏季,P2P行业却迎来最冷冽的寒冬. 引发爆雷潮的众多P ...
- 分享一套好看的PyCharm Color Shceme 配色方案
配色方案图1 点击可查看大图 (color shceme 配色文件下载链接已经放在文末) 配色方案图2 配色方案图3 picture1 picture2 整体效果 下载链接 https://files ...
- 如何动态调用WebService
封装WBS类 using System; using System.Collections.Generic; using System.Linq; using System.Web; using Sy ...
- HDU重现赛之2019CCPC-江西省赛
本人蒟蒻,5个小时过了5道,看到好几个大佬AK,%%%%%%% http://acm.hdu.edu.cn/contests/contest_show.php?cid=868 先放大佬的题解(不是我写 ...
- a标签的一些特殊使用
<a href="tel:10086">10086</a> //点击后直接拨打10086 <a href="mailto:c1586@qq ...
- 设置R更新源
命令行设置R更新源 创建文件 R.home()/etc/Rprofile.site 设置更新源 local({r <- getOption("repos") r[" ...
- IIS设置禁止某个IP或IP段访问网站的方法
网站被刷,对话接不过来 打开IIS,选中禁IP的站点,找到“ip地址和域限制”这个功能,如果没有安装,打开服务器管理器,点击角色,窗口右边找到添加角色服务,找到“IP和域限制”并勾选安装. 打开ip地 ...
- Mutation|DNM|
生命组学 DNA序列改变的分子基础 变异来源 据研究对象,可分为两类mutation:个体上的变异和群体上的变异,群体上的变异是关联研究,eg喝酒人群vs非喝酒人群相比. 造成mutation的三类机 ...
- C++ for循环遍历几种写法
最近写for循环,发现以前用过的方法都忘记了,这里整理下几种方法,欢迎大佬补充: 1. for(itnt n =1;n<5;n++) { } 2. for (auto it = list.beg ...
- 在维护项目中的UUID工具类
import java.util.UUID; /** * <p> * Title:uuID生成器 * </p> * <p> * Description:UUID 标 ...