吴裕雄--天生自然 人工智能机器学习实战代码:线性判断分析LINEARDISCRIMINANTANALYSIS
import numpy as np
import matplotlib.pyplot as plt from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
from sklearn.model_selection import train_test_split
from sklearn import datasets, linear_model,discriminant_analysis def load_data():
# 使用 scikit-learn 自带的 iris 数据集
iris=datasets.load_iris()
X_train=iris.data
y_train=iris.target
return train_test_split(X_train, y_train,test_size=0.25,random_state=0,stratify=y_train) #线性判断分析LinearDiscriminantAnalysis
def test_LinearDiscriminantAnalysis(*data):
X_train,X_test,y_train,y_test=data
lda = discriminant_analysis.LinearDiscriminantAnalysis()
lda.fit(X_train, y_train)
print('Coefficients:%s, intercept %s'%(lda.coef_,lda.intercept_))
print('Score: %.2f' % lda.score(X_test, y_test)) # 产生用于分类的数据集
X_train,X_test,y_train,y_test=load_data()
# 调用 test_LinearDiscriminantAnalysis
test_LinearDiscriminantAnalysis(X_train,X_test,y_train,y_test)

def plot_LDA(converted_X,y):
'''
绘制经过 LDA 转换后的数据
:param converted_X: 经过 LDA转换后的样本集
:param y: 样本集的标记
'''
fig=plt.figure()
ax=Axes3D(fig)
colors='rgb'
markers='o*s'
for target,color,marker in zip([0,1,2],colors,markers):
pos=(y==target).ravel()
X=converted_X[pos,:]
ax.scatter(X[:,0], X[:,1], X[:,2],color=color,marker=marker,label="Label %d"%target)
ax.legend(loc="best")
fig.suptitle("Iris After LDA")
plt.show() def run_plot_LDA():
'''
执行 plot_LDA 。其中数据集来自于 load_data() 函数
'''
X_train,X_test,y_train,y_test=load_data()
X=np.vstack((X_train,X_test))
Y=np.vstack((y_train.reshape(y_train.size,1),y_test.reshape(y_test.size,1)))
lda = discriminant_analysis.LinearDiscriminantAnalysis()
lda.fit(X, Y)
converted_X=np.dot(X,np.transpose(lda.coef_))+lda.intercept_
plot_LDA(converted_X,Y) # 调用 run_plot_LDA
run_plot_LDA()

def test_LinearDiscriminantAnalysis_solver(*data):
'''
测试 LinearDiscriminantAnalysis 的预测性能随 solver 参数的影响
'''
X_train,X_test,y_train,y_test=data
solvers=['svd','lsqr','eigen']
for solver in solvers:
if(solver=='svd'):
lda = discriminant_analysis.LinearDiscriminantAnalysis(solver=solver)
else:
lda = discriminant_analysis.LinearDiscriminantAnalysis(solver=solver,shrinkage=None)
lda.fit(X_train, y_train)
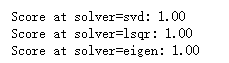
print('Score at solver=%s: %.2f' %(solver, lda.score(X_test, y_test))) # 调用 test_LinearDiscriminantAnalysis_solver
test_LinearDiscriminantAnalysis_solver(X_train,X_test,y_train,y_test)
def test_LinearDiscriminantAnalysis_shrinkage(*data):
'''
测试 LinearDiscriminantAnalysis 的预测性能随 shrinkage 参数的影响
'''
X_train,X_test,y_train,y_test=data
shrinkages=np.linspace(0.0,1.0,num=20)
scores=[]
for shrinkage in shrinkages:
lda = discriminant_analysis.LinearDiscriminantAnalysis(solver='lsqr',shrinkage=shrinkage)
lda.fit(X_train, y_train)
scores.append(lda.score(X_test, y_test))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(shrinkages,scores)
ax.set_xlabel(r"shrinkage")
ax.set_ylabel(r"score")
ax.set_ylim(0,1.05)
ax.set_title("LinearDiscriminantAnalysis")
plt.show()
# 调用 test_LinearDiscr
test_LinearDiscriminantAnalysis_shrinkage(X_train,X_test,y_train,y_test)

吴裕雄--天生自然 人工智能机器学习实战代码:线性判断分析LINEARDISCRIMINANTANALYSIS的更多相关文章
- 吴裕雄--天生自然 人工智能机器学习实战代码:ELASTICNET回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄--天生自然 人工智能机器学习实战代码:LASSO回归
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model from s ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据 import matplotlib import matplotlib.pyplot as plt from numpy import * xcord0 = [] ycord0 ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...
- 吴裕雄--天生自然python机器学习:机器学习简介
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息.例如 ,对于垃圾邮 件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅 以考察邮件长度及其他因素,人们 ...
- 吴裕雄--天生自然python机器学习:基于支持向量机SVM的手写数字识别
from numpy import * def img2vector(filename): returnVect = zeros((1,1024)) fr = open(filename) for i ...
随机推荐
- IaaS SaaS PaaS区别
- h3c 瘦ap无法上线解决办法(WA4320i-ACN)
瘦ap无法上线的原因主要有两个:1.无法获取IP地址 2 .版本 胖ap转瘦ap: 1.使用网线+web对ap进行管理,默认IP地址为:192.168.0.50,用户名:admin 密码:h3capa ...
- Maven高级:01.maven分模块构建&&02.私服的应用
IntelliJ IDEA 2018.3.6 x64 07 Maven高级:01.maven分模块构建(上) 07 Maven高级:01.maven分模块构建(中) 07 Maven高级:01.mav ...
- this, 闭包,箭头函数
闭包写法 //后台每个执行环境都有一个表示变量的对象---变量对象 //例如compare()函数调用 //compare的执行环境而言,其作用域链包含两个变量对象 本地活动对象 全局活动对象 全局变 ...
- MySQL--SHOW TABLE STATUS命令
show table status 获取表的信息 来自:http://blog.csdn.net/java2000_wl/article/details/7935035
- Gson使用指南(二)
注:此系列基于Gson 2.4. 一.Gson的流式反序列化 自动方式 常用的重载方法: Gson.toJson(Object); Gson.fromJson(Reader,Class); Gson. ...
- is,==区别,编码转换
一.is 比较的是内存地址 == 比较的是两边的值 二.编码扩展: 1字节(bytes) = 8 位(bit) 1024byte = 1kb 1024kb = 1MB 1024MB = 1GB 102 ...
- 给创业公司CEO的临别赠言
一别两宽,各生欢喜 2018年2月8日,我在这个公司的最后一天,三年半. 还记得2014年,在三里屯SOHO的某个咖啡厅中,你自信飞扬的脸和眼睛里暗夜星辰般的闪亮的希冀让我久久无法平静.终于在某一个耀 ...
- BeagleboneBlack上u-boot的MLO文件是哪里来的
在玩BeagleboneBlack一段时间之后不可避免地接触到了u-boot,之前的玩耍过程大致上是这样的: 在MATLAB下耍,因为MATLAB提供了它的硬件支持,可以直接在命令行与之交互,也可在s ...
- freeswitch的internal的profile无法启动
服务器断电重启后,导致freeswitch的internal的profile无法启动 在fs_cli执行 sofia profile internal restart 打印如下信息: [ERR] sw ...