redis 深入理解redis 主从复制原理
redis 主从复制
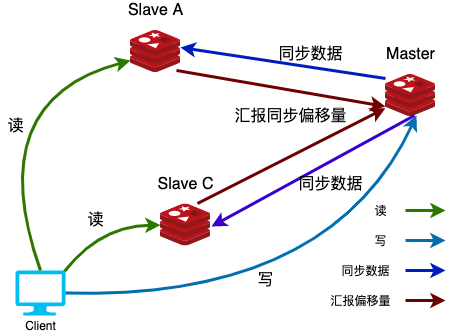
master 节点提供数据,也就是写。slave 节点负责读。
不是说master 分支不能读数据,也能只是我们希望将读写进行分离。
slave 是不能写数据的,只能处理读请求
主从实现
客户端 127.0.0.1:6379 服务器 212.64.89.173:6379
方式一
客户端发送请求同步命令
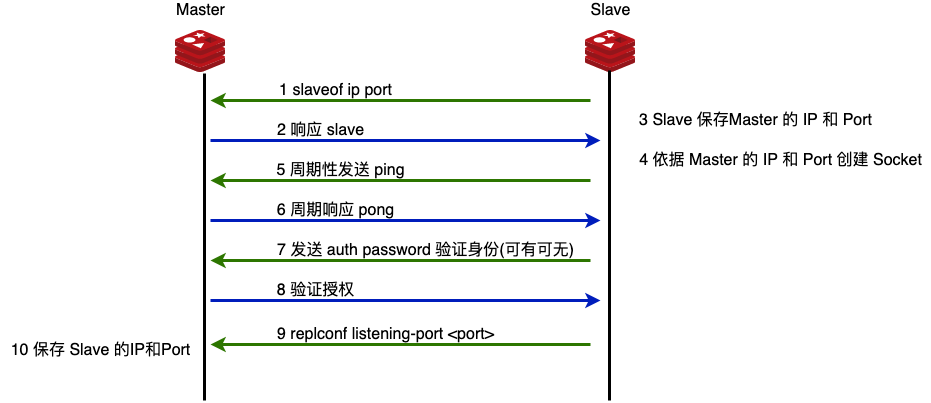
slaveof masterip masterport
slaveof 212.64.89.173 6379
方式二
客户端启动服务器参数
redis-server --slaveof masterip masterport
redis-server --slaveof 212.64.89.173 6379
方式三
在客户端的配置文件中写入 slaveof 信息
redis.conf
slaveof 212.64.89.173 6379
注意 断开主从链接方式: 客户端执行 slaveof no one
设置链接密码
server 端
服务启动后设置
config set requierpass <password>
配置文件添加密码
# redis.conf
requirepass <password>
client 端
命令设置密码
auth <password>
配置文件设置密码
masterauth <password>
启动客户端设置密码
redis-cli -a <password>
建立连接
建立链接的过程就是希望 master 和 slave 都保有对方的 IP 和 Port。
数据同步
数据的同步分两部分,全量同步和增量同步,在增量同步结束后,master 应当保存Slave 同步数据的位置。

复制(积压)缓冲区
它有两部分组成 偏移量 + 字节值
结构

创建
1 当启动AOF 时就会创建 复制积压缓冲区
2 当被选为 master 节点,必须创建积压缓冲区
作用
保存所有的对数据修改或数据库修改的指令,查询指令不会被记录。
数据源
所有的进入master 的对数据修改或数据库修改的指令都会被填充到积压缓冲区中。
偏移量
1 Master 和 Slave 都会记录 offset 值, 每次复制都会对比offset 是否一致。如果一致,Master直接从 offset 处开始传缓冲区数据,如果不一致,那么Master将遵循 Slave 的offset 来传。当然会保证命令是完整的。
2 Master 保存有多个 offset 而 Slave 仅保存自己的。
3 Master发送一次,记录一次, Slave 接受一次记录一次。
关于Master注意
1如果master 数据量过大,应该避免业务高峰期进行数据同步。避免造成 master 阻塞
2 数据缓冲区满, 此时将会丢弃最早的记录(FIFO),如果全量复制的时间开销过大,则可能在开增量复制时候已经存在数据丢失,这会导致Master 和 Slave 数据不一致,为了保证一致性,必须开始新一轮的全量复制,完成后缓冲区又被填满并存在丢弃,则会让Slave进入死循环。
因此数据缓冲区要设置的大小合适(依具体情况而定)。
repl-backlog-size 1mb # 默认的大小为 1MB
3 master 单机内存不应该占用主机内存过多。一般的 50 ~ 70% 预留下 30% ~ 50%来进行bgsave 、 创建复制缓冲区、执行其他业务等。
关于Slave注意
1 为避免slave进行全量复制、部分复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务。
slave-server-stale-data yes|no
2 数据同步阶段,master 发送给 slave 信息可以理解 master 是 slave 的一个客户端,主动向slave发送命令。
3 多个slave同时对master请求数据同步,master发送的RDB文件增多,会对带宽造成巨大冲击,如果master宽带不足,因此数据同步需要根据业务需求,适量错峰。
4 slave过多时,应该对拓扑结构进行调整,由一主多从结构变为树状结构,中间结点即是master,也是slave。但是使用树状结构时,因为层级越深,数据同步时延越大,因此将强一致性的数据放在顶层节点,一致性稍弱的数据放在靠底层的节点。
命令传播
当master数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的状态,同步的动作成为命令传播
master将接受到的数据变更命令发送给slave,slave接受命令后执行命令。
网络闪断闪连 忽略
短时间网络中断 部分复制
长时间网络中断 全量复制
服务器运行ID(runid)
每台服务器每次运行都会产生的身份识别码,同一个服务器多次运行产生的runid是不一样的。
形式:runid 由 40 个字符组成 一般是16进制的字符串
info server
run_id:409b6e9ea2e5c32958de8f365711598c98489f13
心跳机制
master
指令 PING
周期 repl-ping-slave-period 默认是 10s
作用 判断 slave 是否在线
查询 INFO replication 获取最后一次 slave 连接时间间隔 lag = 0 / 1 属于正常
slave
指令 REPLCONF{offset}
周期: 1s
作用1: 汇报自己的复制偏移量 获取最新的数据变更指令
作用2: 判断 master 是否存活
心跳注意事项
当 salve多数掉线 或者网络延时过高时,master 会拒绝所有的同步信息。
min-slaves-to-write 2 # 最小的 slave 数量
min-slaves-max-lag 8 # 最长的
当 slave 的数量小于2 ,或者所有的时延都大于等于 8 时,会强 关闭 master 的血功能来停止数据同步。
Slave 的数量和延时由REPLCONF{offset} 命令确认。
完整的主从复制流程

读写分离
在redis主从架构中,Master节点负责处理写请求,Slave节点只处理读请求。对于写请求少,读请求多的场景,例如电商详情页,通过这种读写分离的操作可以大幅提高并发量,通过增加redis从节点的数量可以使得redis的QPS达到10W+。
负载均衡
基于主从结构,配合读写分离,由slave分担master负载,并根据需求的变化,改变slave的数量,通过多个从节点分担数据读取负载,大大提高Redis服务器并发量与数据吞吐量
故障恢复
当master出现问题时,由slave提供服务,实现快速的故障恢复
数据冗余
实现数据热备份,时持久化之外的一种数据冗余方式
高可用基石
基于主从复制,构建哨兵模式与集群,实现redis 的高可用方案。
redis 深入理解redis 主从复制原理的更多相关文章
- Redis高可用之主从复制原理演进分析
Redis高可用之主从复制原理演进分析 在很久之前写过一篇 Redis 主从复制原理的简略分析,基本是一个笔记类文章. 一.什么是主从复制 1.1 什么是主从复制 主从复制,从名字可以看出,至少需要 ...
- Redis主从复制原理总结
和Mysql主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况.为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redi ...
- 深入理解redis复制原理
原文:深入理解redis复制原理 1.复制过程 2.数据间的同步 3.全量复制 4.部分复制 5.心跳 6.异步复制 1.复制过程 从节点执行 slaveof 命令. 从节点只是保存了 slaveof ...
- Redis 主从复制原理及雪崩 穿透问题
定义: Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API.从2010年3月15日起,Redis的开发工作由VMw ...
- 深入Redis 主从复制原理
原文:深入Redis 主从复制原理 1.复制过程 2.数据间的同步 3.全量复制 4.部分复制 5.心跳 6.异步复制 1.复制过程 从节点执行 slaveof 命令. 从节点只是保存了 slaveo ...
- 深入理解Redis主键失效原理及实现机制(转)
原文:深入理解Redis主键失效原理及实现机制 作为一种定期清理无效数据的重要机制,主键失效存在于大多数缓存系统中,Redis 也不例外.在 Redis 提供的诸多命令中,EXPIRE.EXPIREA ...
- Redis系列(四):Redis持久化和主从复制原理
一.持久化 所谓的持久化就是把内存中的数据写到磁盘中去,防止服务宕机后内存数据丢失.Redis4.0之前提供了两种持久化方式:RDB(默认) 和AOF,Redis4.x之后新增了一种混合持久化(本文所 ...
- 5.如何保证 redis 的高并发和高可用?redis 的主从复制原理能介绍一下么?redis 的哨兵原理能介绍一下么?
作者:中华石杉 面试题 如何保证 redis 的高并发和高可用?redis 的主从复制原理能介绍一下么?redis 的哨兵原理能介绍一下么? 面试官心理分析 其实问这个问题,主要是考考你,redis ...
- redis主从复制原理与优化-高可用
一 什么是主从复制 机器故障:容量瓶颈:QPS瓶颈 一主一从,一主多从 做读写分离 做数据副本 扩展数据性能 一个maskter可以有多个slave 一个slave只能有一个master 数据流向是单 ...
随机推荐
- 二、工具类ImageUtil——图片处理
这个工具类完成的工作如下: 1.第一个static方法,完成图片格式的转换.统一转换成.jpg格式. package util; import java.awt.Toolkit; import jav ...
- Pyqt5_QMessageBox
QMessageBox header:会话窗标题 info:会话窗内容 #弹出5种不同类型的消息框 reply1=QMessageBox.information(self,"title&qu ...
- 【学习】Python os模块常用方法 记录
记录一些工作中常用到的用法 os.walk() 模块os中的walk()函数可以遍历文件夹下所有的文件. os.walk(top, topdown=Ture, onerror=None, follow ...
- Python操作Word与Excel并打包
安装模块 # Word操作库 pip install docx # Excel操作库 pip install openpyxl # 打包exe工具 pip install pyinstaller Wo ...
- shell日期格式化、加减运算
#!/bin/bash echo i love you输出:i love you =======================================反引号的作用============== ...
- Golang基础教程——map使用篇
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是golang专题的第7篇文章,我们来聊聊golang当中map的用法. map这个数据结构我们经常使用,存储的是key-value的键 ...
- Beta冲刺——5.26
这个作业属于哪个课程 软件工程 这个作业要求在哪里 Beta冲刺 这个作业的目标 Beta冲刺 作业正文 正文 github链接 项目地址 其他参考文献 无 一.会议内容 1.组员一起学习Git分支管 ...
- Chisel3 - bind - Binding
https://mp.weixin.qq.com/s/2318e6VJ4wFGpWwBOmTikA Chisel数据类型(Data)与Module的绑定关系,根据Data的使用方式不同,而有多种绑 ...
- Java实现 蓝桥杯 算法训练 Number Challenge(暴力)
试题 算法训练 Number Challenge 资源限制 时间限制:3.0s 内存限制:512.0MB 问题描述 定义d(n)为n的约数个数.现在,你有三个数a,b,c.你的任务是计算下面式子mod ...
- Java实现 蓝桥杯VIP 基础练习 时间转换
问题描述 给定一个以秒为单位的时间t,要求用"h️s" 的格式来表示这个时间.H表示时间,M表示分钟,而s表示秒,它们都是整数且没有前导的"0".例如,若t=0 ...