Kappa(cappa)系数只需要看这一篇就够了,算法到python实现
1 定义
百度百科的定义:
它是通过把所有地表真实分类中的像元总数(N)乘以混淆矩阵对角线(Xkk)的和,再减去某一类地表真实像元总数与被误分成该类像元总数之积对所有类别求和的结果,再除以总像元数的平方减去某一类中地表真实像元总数与该类中被误分成该类像元总数之积对所有类别求和的结果所得到的。
这对于新手而言可能比较难理解。什么混淆矩阵?什么像元总数?
我们直接从算式入手:
\]
\(p_0\)是每一类正确分类的样本数量之和除以总样本数,也就是总体分类精度
假设每一类的真实样本个数分别为\(a_1,a_2,...,a_c\)
而预测出来的每一类的样本个数分别为\(b_1,b_2,...,b_c\)
总样本个数为n
则有:\(p_e=a_1×b_1+a_2×b_2+...+a_c×b_c / n×n\)
1.1 简单例子
学生考试的作文成绩,由两个老师给出 好、中、差三档的打分,现在已知两位老师的打分结果,需要计算两位老师打分之间的相关性kappa系数:
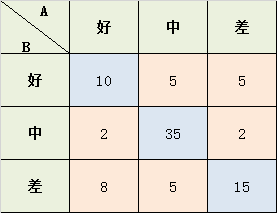
从上面的公式中,可以知道我们其实只需要计算\(p_0 ,p_e\)即可:
Po = (10+35+15) / 87 = 0.689
a1 = 10+2+8 = 20; a2 = 5+35+5 = 45; a3 = 5+2+15 = 22;
b1 = 10+5+5 = 20; b2 = 2+35+2 = 39; b3 = 8+5+15 = 28;
Pe = (a1b1 + a2b2 + a3b3) / (8787) = 0.455
K = (Po-Pe) / (1-Pe) = 0.4293578
例子引用来自博客,可以说提到kappa网上到处都是两个老师的例子,哈哈
2 指标解释
kappa计算结果为[-1,1],但通常kappa是落在 [0,1] 间
第一种分析准则--可分为五组来表示不同级别的一致性:
0.0~0.20极低的一致性(slight)
0.21~0.40一般的一致性(fair)
0.41~0.60 中等的一致性(moderate)
0.61~0.80 高度的一致性(substantial)
0.81~1几乎完全一致(almost perfect)
3 python实现(可直接用于深度网络中)
def eval_qwk_lgb_regr(y_true, y_pred):
# Fast cappa eval function for lgb.
dist = Counter(reduce_train['accuracy_group'])
for k in dist:
dist[k] /= len(reduce_train)
reduce_train['accuracy_group'].hist()
# reduce_train['accuracy_group']将会分成四组
acum = 0
bound = {}
for i in range(3):
acum += dist[i]
bound[i] = np.percentile(y_pred, acum * 100)
def classify(x):
if x <= bound[0]:
return 0
elif x <= bound[1]:
return 1
elif x <= bound[2]:
return 2
else:
return 3
y_pred = np.array(list(map(classify, y_pred))).reshape(y_true.shape)
return 'cappa', cohen_kappa_score(y_true, y_pred, weights='quadratic'), True
以上代码是本人在kaggle比赛中使用的,因为kappa系数的算法非常好写,但是又要根据实际问题进行微小的调整,所以就不修改了。如果能提供帮助自然好,如果没有头绪的话,就去第一二章节好好看看,理解一下kappa系数的算法。
4 总结
其实kappa系数就是一种检验一致性的方法,可以用在深度网络中的metric函数中,也可以用在统计学上的一致性检验上。
Kappa(cappa)系数只需要看这一篇就够了,算法到python实现的更多相关文章
- 贝叶斯优化(Bayesian Optimization)只需要看这一篇就够了,算法到python实现
贝叶斯优化 (BayesianOptimization) 1 问题提出 神经网咯是有许多超参数决定的,例如网络深度,学习率,正则等等.如何寻找最好的超参数组合,是一个老人靠经验,新人靠运气的任务. 穷 ...
- 转载:Docker入门只需看这一篇就够了
最近项目中需要用到 Docker 打包,于是上网查找资料学习了 Docker 的基本命令,记录一下自己遇到的一些错误. 准备开始自己写,结果看到了阮一峰老师的文章,瞬间就没有写下去的动力了,转载大佬的 ...
- JVM内存模型你只要看这一篇就够了
JVM内存模型你只要看这一篇就够了 我是一只孤傲的鱼鹰 让我们不厌其烦的从内存模型开始说起:作为一般人需要了解到的,JVM的内存区域可以被分为:线程栈,堆,静态方法区(实际上还有更多功能的区域,并且这 ...
- windows server 2019 域控批量新增不用,只看这一篇就够了,别的不用看
windows server 2019 域控批量新增不用,只看这一篇就够了,别的不用看 1. 新建excel表格 A B C D E 姓 名 全名 登录名 密码 李 四 李四 李四 test123!@ ...
- 关于 Docker 镜像的操作,看完这篇就够啦 !(下)
紧接着上篇<关于 Docker 镜像的操作,看完这篇就够啦 !(上)>,奉上下篇 !!! 镜像作为 Docker 三大核心概念中最重要的一个关键词,它有很多操作,是您想学习容器技术不得不掌 ...
- Java中的多线程=你只要看这一篇就够了
如果对什么是线程.什么是进程仍存有疑惑,请先Google之,因为这两个概念不在本文的范围之内. 用多线程只有一个目的,那就是更好的利用cpu的资源,因为所有的多线程代码都可以用单线程来实现.说这个话其 ...
- [转帖]nginx学习,看这一篇就够了:下载、安装。使用:正向代理、反向代理、负载均衡。常用命令和配置文件
nginx学习,看这一篇就够了:下载.安装.使用:正向代理.反向代理.负载均衡.常用命令和配置文件 2019-10-09 15:53:47 冯insist 阅读数 7285 文章标签: nginx学习 ...
- 2019-5-25-win10-uwp-win2d-入门-看这一篇就够了
title author date CreateTime categories win10 uwp win2d 入门 看这一篇就够了 lindexi 2019-5-25 20:0:52 +0800 2 ...
- 什么是 DevOps?看这一篇就够了!
本文作者:Daniel Hu 个人主页:https://www.danielhu.cn/ 目录 一.前因 二.记忆 三.他们说-- 3.1.Atlassian 回答"什么是 DevOps?& ...
随机推荐
- PHP(ThinkPHP5.0) + PHPMailer 进行邮箱发送验证码
GitHub下载最新版第三方类库PHPMailer: 第一步: 打开网址https://github.com/PHPMailer/PHPMailer/ 下载PHPMailer,PHPMailer 需要 ...
- Ubuntu 18.04更换apt-get源
使用apt-get安装时,会很慢,更换了国内的源后,就可以解决这个问题了. 1. 备份sources.list文件 sudo cp /etc/apt/sources.list /etc/apt/sou ...
- Cobbler自动装机试验
Cobbler自动装机简介:Cobbler是一个使用Python开发的开源项目,通过将部署系统所涉及的所有服务集中在一起,来提供一个全自动的批量快速建立Linux系统的网络安装环境.Cobbler提供 ...
- 数学--数论--HDU 2136(素数筛选法)
Everybody knows any number can be combined by the prime number. Now, your task is telling me what po ...
- 图论--最短路--SPFA模板(能过题,真没错的模板)
[ACM常用模板合集] #include<iostream> #include<queue> #include<algorithm> #include<set ...
- unittest 管理用例生成测试报告
# 登录方法的封装 from appium import webdriver from time import sleep from python_selenium.Slide import swip ...
- python(open 文件)
一.open 文件 1.open('file','mode')打开一个文件 file 要打开的文件名,需加路径(除非是在当前目录) mode 文件打开的模式 需要手动关闭 close 2.with o ...
- Android控件重叠显示小记
方案一 利用布局控件显示优先级 在xml中RelativeLayout,FrameLayout,靠后的控件显示在上层. 利用margin属性 margin属性可以控制控件间的距离,属性值为正值时,越大 ...
- 在Vue中使用iview的Select控件实现一个多级选项列表
前言 今天项目要实现一个多级选项列表,发现iview官网上没有写这个例子,于是自己就实现了,如果对你有帮助请点个赞 ‘ * ’!! 解决方法:下面我们就来使用V-for 来定义一个二级选项列表 ,代码 ...
- C#对象初始化器
1.对象初始化器 Student objStu2 = new Student() { StudentId=, //属性之间使用","分隔 StudentName="小明& ...