SpringBoot 2.0 整合sharding-jdbc中间件,实现数据分库分表
本文源码:GitHub·点这里 || GitEE·点这里
一、水平分割
1、水平分库
1)、概念:
以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中。
2)、结果
每个库的结构都一样;数据都不一样;
所有库的并集是全量数据;
2、水平分表
1)、概念
以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中。
2)、结果
每个表的结构都一样;数据都不一样;
所有表的并集是全量数据;
二、Shard-jdbc 中间件
1、架构图
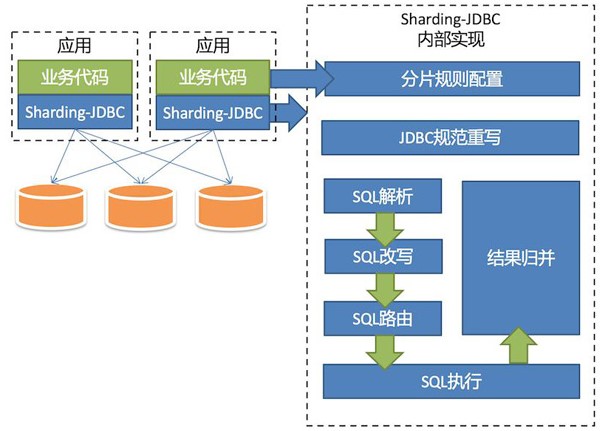
2、特点
1)、Sharding-JDBC直接封装JDBC API,旧代码迁移成本几乎为零。
2)、适用于任何基于Java的ORM框架,如Hibernate、Mybatis等 。
3)、可基于任何第三方的数据库连接池,如DBCP、C3P0、 BoneCP、Druid等。
4)、以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖。
5)、分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
6)、SQL解析功能完善,支持聚合、分组、排序、limit、or等查询。
三、项目演示
1、项目结构
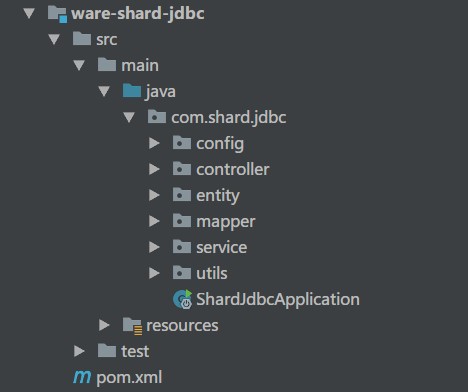
springboot 2.0 版本
druid 1.1.13 版本
sharding-jdbc 3.1 版本
2、数据库配置


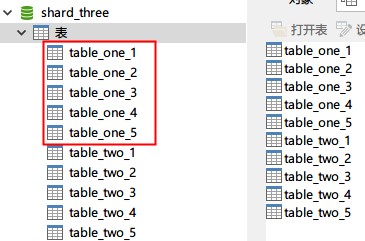
一台基础库映射(shard_one)
两台库做分库分表(shard_two,shard_three)。
表使用:table_one,table_two
3、核心代码块
- 数据源配置文件
spring:
datasource:
# 数据源:shard_one
dataOne:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_one?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 数据源:shard_two
dataTwo:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_two?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 数据源:shard_three
dataThree:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_three?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
- 数据库分库策略
/**
* 数据库映射计算
*/
public class DataSourceAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(DataSourceAlg.class);
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分库算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "ds_" + ((hash % 2) + 2) ;
}
}
- 数据表1分表策略
/**
* 分表算法
*/
public class TableOneAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(TableOneAlg.class);
/**
* 该表每个库分5张表
*/
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分表算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "table_one_" + (hash % 5+1);
}
}
- 数据表2分表策略
/**
* 分表算法
*/
public class TableTwoAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(TableTwoAlg.class);
/**
* 该表每个库分5张表
*/
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分表算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "table_two_" + (hash % 5+1);
}
}
- 数据源集成配置
/**
* 数据库分库分表配置
*/
@Configuration
public class ShardJdbcConfig {
// 省略了 druid 配置,源码中有
/**
* Shard-JDBC 分库配置
*/
@Bean
public DataSource dataSource (@Autowired DruidDataSource dataOneSource,
@Autowired DruidDataSource dataTwoSource,
@Autowired DruidDataSource dataThreeSource) throws Exception {
ShardingRuleConfiguration shardJdbcConfig = new ShardingRuleConfiguration();
shardJdbcConfig.getTableRuleConfigs().add(getTableRule01());
shardJdbcConfig.getTableRuleConfigs().add(getTableRule02());
shardJdbcConfig.setDefaultDataSourceName("ds_0");
Map<String,DataSource> dataMap = new LinkedHashMap<>() ;
dataMap.put("ds_0",dataOneSource) ;
dataMap.put("ds_2",dataTwoSource) ;
dataMap.put("ds_3",dataThreeSource) ;
Properties prop = new Properties();
return ShardingDataSourceFactory.createDataSource(dataMap, shardJdbcConfig, new HashMap<>(), prop);
}
/**
* Shard-JDBC 分表配置
*/
private static TableRuleConfiguration getTableRule01() {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("table_one");
result.setActualDataNodes("ds_${2..3}.table_one_${1..5}");
result.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new DataSourceAlg()));
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new TableOneAlg()));
return result;
}
private static TableRuleConfiguration getTableRule02() {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("table_two");
result.setActualDataNodes("ds_${2..3}.table_two_${1..5}");
result.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new DataSourceAlg()));
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new TableTwoAlg()));
return result;
}
}
- 测试代码执行流程
@RestController
public class ShardController {
@Resource
private ShardService shardService ;
/**
* 1、建表流程
*/
@RequestMapping("/createTable")
public String createTable (){
shardService.createTable();
return "success" ;
}
/**
* 2、生成表 table_one 数据
*/
@RequestMapping("/insertOne")
public String insertOne (){
shardService.insertOne();
return "SUCCESS" ;
}
/**
* 3、生成表 table_two 数据
*/
@RequestMapping("/insertTwo")
public String insertTwo (){
shardService.insertTwo();
return "SUCCESS" ;
}
/**
* 4、查询表 table_one 数据
*/
@RequestMapping("/selectOneByPhone/{phone}")
public TableOne selectOneByPhone (@PathVariable("phone") String phone){
return shardService.selectOneByPhone(phone);
}
/**
* 5、查询表 table_one 数据
*/
@RequestMapping("/selectTwoByPhone/{phone}")
public TableTwo selectTwoByPhone (@PathVariable("phone") String phone){
return shardService.selectTwoByPhone(phone);
}
}
四、项目源码
GitHub·地址
https://github.com/cicadasmile/middle-ware-parent
GitEE·地址
https://gitee.com/cicadasmile/middle-ware-parent

SpringBoot 2.0 整合sharding-jdbc中间件,实现数据分库分表的更多相关文章
- (二)基于shard-jdbc中间件,实现数据分库分表
基于shard-jdbc中间件,实现数据分库分表 Sharding-JDBC简介 Sharding配置示意图 1.水平分割 1.1 水平分库 1.2 水平分表 2.Shard-jdbc中间件 2.1 ...
- sharding demo 读写分离 U (分库分表 & 不分库只分表)
application-sharding.yml sharding: jdbc: datasource: names: ds0,ds1,dsx,dsy ds0: type: com.zaxxer.hi ...
- SpringBoot+MybatisPlus+Mysql+Sharding-JDBC分库分表实践
一.序言 在实际业务中,单表数据增长较快,很容易达到数据瓶颈,比如单表百万级别数据量.当数据量继续增长时,数据的查询性能即使有索引的帮助下也不尽如意,这时可以引入数据分库分表技术. 本文将基于Spri ...
- mysql大数据解决方案--分表分库(0)
引言 对于一个大型的互联网应用,海量数据的存储和访问成为了系统设计的瓶颈问题,对于系统的稳定性和扩展性造成了极大的问题.通过数据切分来提高网站性能,横向扩展数据层已经成为架构研发人员首选的方式. •水 ...
- Sharding JDBC整合SpringBoot 2.x 和 MyBatis Plus 进行分库分表
Sharding JDBC整合SpringBoot 2.x 和 MyBatis Plus 进行分库分表 交易所流水表的单表数据量已经过亿,选用Sharding-JDBC进行分库分表.MyBatis-P ...
- 【ShardingSphere技术专题】「ShardingJDBC」SpringBoot之整合ShardingJDBC实现分库分表(JavaConfig方式)
前提介绍 ShardingSphere介绍 ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC.Sharding-Proxy和Shardin ...
- Sharding-JDBC基本使用,整合Springboot实现分库分表,读写分离
结合上一篇docker部署的mysql主从, 本篇主要讲解SpringBoot项目结合Sharding-JDBC如何实现分库分表.读写分离. 一.Sharding-JDBC介绍 1.这里引用官网上的介 ...
- SpringBoot+Mybatis-Plus整合Sharding-JDBC5.1.1实现单库分表【全网最新】
一.前言 小编最近一直在研究关于分库分表的东西,前几天docker安装了mycat实现了分库分表,但是都在说mycat的bug很多.很多人还是倾向于shardingsphere,其实他是一个全家桶,有 ...
- 三、SpringBoot 整合mybatis 多数据源以及分库分表
前言 说实话,这章本来不打算讲的,因为配置多数据源的网上有很多类似的教程.但是最近因为项目要用到分库分表,所以让我研究一下看怎么实现.我想着上一篇博客讲了多环境的配置,不同的环境调用不同的数据库,那接 ...
随机推荐
- Collection of Boot Sector Formats for ISO 9660 Images
http://bazaar.launchpad.net/~libburnia-team/libisofs/scdbackup/view/head:/doc/boot_sectors.txt Colle ...
- The server must be started under an unprivileged user ID to prevent
mysql8 PostgreSQL [root@test local]# postgres -D /usr/local/pgsql/data"root" execution of ...
- Redisson实现Redis分布式锁的N种姿势(转)
Redis几种架构 Redis发展到现在,几种常见的部署架构有: 单机模式: 主从模式: 哨兵模式: 集群模式: 我们首先基于这些架构讲解Redisson普通分布式锁实现,需要注意的是,只有充分了解普 ...
- 【LeetCode】Rotate List
Given a list, rotate the list to the right by k places, where k is non-negative. For example:Given 1 ...
- POSTGRESQL主备部署模式
一.预期目的 主数据库(Primary pg ,假定主机名为A,后文不再赘述)和备用数据库(Standby pg,假定主机名为B,后文不再赘述)之间的数据能够相互备份. 主数据库发生故障时备用数据库可 ...
- js 链接传入中文参数乱码解决
传入时,可能出现中文的参数用encodeURI进行两次转码,如: lethref="http://www.zzdblog.cn?keyword='+encodeURI(encodeURI(k ...
- vue路由总结
vue-router, vue自带的路由,下面是一些简单的操作说明: 一.安装 1.cnpm install vue-router --save 命令进行安装 2.在main.js或者使用vue-r ...
- Hihocoder #1121 二分图一•二分图判定( bfs或者dfs搜索实现 搜索的过程中进行 节点标记 *【模板】)
对于拿到的相亲情况表,我们不妨将其转化成一个图.将每一个人作为一个点(编号1..N),若两个人之间有一场相亲,则在对应的点之间连接一条无向边.(如下图) 因为相亲总是在男女之间进行的,所以每一条边的两 ...
- LightOJ1336 Sigma Function —— 质因子分解、约数和为偶数
题目链接:https://vjudge.net/problem/LightOJ-1336 1336 - Sigma Function PDF (English) Statistics Forum ...
- HDU5965 扫雷 —— dp递推
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5965 题解: 1. 用a[]数组记录第二行的数字,用dp[]记录没一列放的地雷数.如果第一列的地雷数d ...