函数式编程 - 函数缓存Memoization
函数式编程风格中有一个“纯函数”的概念,纯函数是一种无副作用的函数,除此之外纯函数还有一个显著的特点:对于同样的输入参数,总是返回同样的结果。在平时的开发过程中,我们也应该尽量把无副作用的“纯计算”提取出来实现成“纯函数”,尤其是涉及到大量重复计算的过程,使用纯函数+函数缓存的方式能够大幅提高程序的执行效率。本文的主题即是函数缓存实现的及应用,必须强调的是Memoization起作用的对象只能是纯函数
函数缓存的概念很简单,先来一个最简单的实现来说明一下:
function memoize(func) {
const cache = {};
return function(...args) {
const key = JSON.stringify(args)
return cache[key] || (cache[key] = func.apply(this, args))
}
}
memoize就是一个高阶函数,接受一个纯函数作为参数,并返回一个函数,结合闭包来缓存原纯函数执行的结果,可以简单的测试一下:
function sum(n1, n2) {
const sum = n1 + n2
console.log(`${n1}+${n2}=${sum}`)
return sum
}
const memoizedSum = memoize(sum)
memoizedSum(1, 2) // 会打印出:1+2=3
memoizedSum(1, 2) // 没有输出
memoizedSum在第一次执行时将执行结果缓存在了闭包中的缓存对象cache中,因此第二次执行时,由于输入参数相同,直接返回了缓存的结果。
上面memoize的实现能够满足简单场景下纯函数结果的缓存,但要使其适用于更广的范围,还需要重点考虑两个问题:
- 1.缓存器
cache对象的实现问题 - 2.缓存器对象使用的
key值计算问题
下面着重完善这两个问题。
1.cache对象问题
上述实现版本使用普通对象作为缓存器,这是我们惯用的手法。问题不大,但仍要注意,例如最后返回值的语句,存在一个容易忽略的问题:如果cache[key]为“假值”,比如0、null、false,那会导致每次都会重新计算一次。
return cache[key] || (cache[key] = func.apply(this, args))
因此为了严谨,还是要多做一些判断,
function memoize(func) {
const cache = {};
return function(...args) {
const key = JSON.stringify(args)
if(!cache.hasOwnProperty(key)) {
cache[key] = func.apply(this, args)
}
return cache[key]
}
}
更好的选择是使用ES6+支持的Map对象
function memoize(func) {
const cache = new Map()
return function(...args) {
const key = JSON.stringify(args)
if (cache.has(key)) {
return cache.get(key)
}
const result = func.apply(this, args)
cache.set(key, result)
return result
}
}
2.缓存器对象使用的key值计算问题
ES6+的支持使得第一个问题很容易就完善了,毕竟这年头什么代码不是babel加持;而缓存器对象key的确定却是一个让人脑壳疼的问题。key直接决定了函数计算结果缓存的效果,理想情况下,函数参数与key满足一对一关系,上述实现中我们通过const key = JSON.stringify(args)将参数数组序列化计算key,在大多数情况下已经满足了一对一的原则,用在平时的开发中大概也不会有问题。但是需要注意的是序列化将会丢失JSON中没有等效类型的任何Javascript属性,如函数或Infinity,任何值为undefined的属性都将被JSON.stringify忽略,如果值作为数组元素序列化结果又会有所不同,如下图所示。
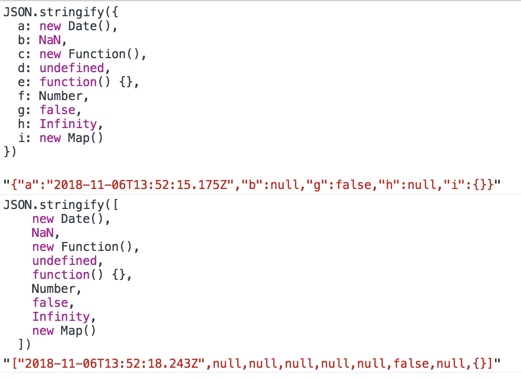 

虽然我们很少将这些特殊类型作为函数参数,但也不能排除这种情况。比如下面的例子,函数calc接收两个普通参数和一个算子,算子则执行具体的计算,如果使用上面的方法缓存函数结果,可以发现第二次输入的是减法函数,但仍然打印出结果3而不是-1,原因是两个参数序列化结果都是[1,2,null],第二次打印的是第一次的缓存结果。
function sum(n1, n2, ) {
const sum = n1 + n2
return sum
}
function sub(n1, n2, ) {
const sub = n1 - n2
return sub
}
function calc(n1, n2, operator){
return operator(n1, n2)
}
const memoizedCalc = memoize(calc)
console.log(memoizedCalc(1, 2, sum)) // 3
console.log(memoizedCalc(1, 2, sub)) // 3
既然JSON.stringify不能产生一对一的key,那么有什么办法可以实现真正的一对一关系呢,参考Lodash的源码,其使用了WeakMap对象作为缓存器对象,其好处是WeakMap对象的key只能是对象,这样如果能够保持参数对象的引用相同,对应的key也就相同。
function memoize(func) {
const cache = new WeakMap()
return function(...args) {
const key = args[0]
if (cache.has(key)) {
return cache.get(key)
}
const result = func.apply(this, args)
cache.set(key, result)
return result
}
}
function sum(n1, n2) {
const sum = n1 + n2
console.log(`${n1}+${n2}:`, sum)
return sum
}
function sub(n1, n2, ) {
const sub = n1 - n2
console.log(`${n1}-${n2}:`, sub)
return sub
}
function calc(param){
const {n1, n2, operator} = param
return operator(n1, n2)
}
const memoizedCalc = memoize(calc)
const param1 = {n1: 1, n2: 2, operator: sum}
const param2 = {n1: 1, n2: 2, operator: sub}
console.log(memoizedCalc(param1))
console.log(memoizedCalc(param2))
console.log(memoizedCalc(param2))
执行打印的结果为
1+2: 3
3
1-2: -1 // 只在第一次做减法运算时打印
-1
-1 // 第二次执行减法直接打印出结果
使用WeakMap作为缓存对象还是有很多局限性,首选参数必须是对象,再比如我们把上例最后几行代码改成下面的代码,会发现后面减法的输出还是错误的,因为前后参数引用的对象都是param1,因此对应的key是相同的,而且在开发过程中我们不太可能一直保存参数的引用,大对数重读计算的场景下,我们都会构造新的参数对象,即使有些参数对象看起来长的一样,但却对应不同的引用,也就对应不同的key,这就失去了缓存的效果。
console.log(memoizedCalc(param1)) // 3
param1.operator = sub
console.log(memoizedCalc(param1)) // 3
console.log(memoizedCalc(param1)) // 3
为了使开发具有最高的灵活性,在Memoization过程中,key的计算最好由开发者自己决定使用何种规则产生与函数结果一一对应的关系,实际上Lodash和Ramda都提供了类似的实现。
function memoize(func, resolver) {
if (typeof func != 'function' || (resolver != null && typeof resolver != 'function')) {
throw new TypeError('Expected a function')
}
const cache = new Map() //可以根据实际情况使用WeakMap或者{}
return function(...args) {
const key = resolver ? resolver.apply(this, args) : args[0]
if (cache.has(key)) {
return cache.get(key)
}
const result = func.apply(this, args)
cache.set(key, result)
return result
}
}
上述代码memoize除了接收需要缓存的函数,还接收一个resolver函数,方便用户自行决定如果计算key。
函数式编程 - 函数缓存Memoization的更多相关文章
- 翻译连载 | 附录 C:函数式编程函数库-《JavaScript轻量级函数式编程》 |《你不知道的JS》姊妹篇
原文地址:Functional-Light-JS 原文作者:Kyle Simpson-<You-Dont-Know-JS>作者 关于译者:这是一个流淌着沪江血液的纯粹工程:认真,是 HTM ...
- [一] java8 函数式编程入门 什么是函数式编程 函数接口概念 流和收集器基本概念
本文是针对于java8引入函数式编程概念以及stream流相关的一些简单介绍 什么是函数式编程? java程序员第一反应可能会理解成类的成员方法一类的东西 此处并不是这个含义,更接近是数学上的 ...
- 函数式编程—函数的关系—is-a、has-a、use-a
is-a:函数的实现与函数类型的关系: has-a:匿名(闭包)函数的创建者与匿名函数的关系:匿名函数与环境和上下文(函数)的关系: use-a:高阶函数与参量函数的关系: 函数式编程的基本功之一就是 ...
- C#函数式编程之缓存技术
缓存技术 该节我们将分成两部分来讲解,第一部分为预计算,第二部分则为缓存.缓存这个技术对应从事开发的人员来说是非常熟悉的,从页面缓存到数据库缓存无处不在,而其最重要的特点就是在第一次查询后将数据缓存, ...
- C#函数式编程-高阶函数
随笔分类 -函数式编程 C#函数式编程之标准高阶函数 2015-01-27 09:20 by y-z-f, 344 阅读, 收藏, 编辑 何为高阶函数 大家可能对这个名词并不熟悉,但是这个名词所表达的 ...
- Python进阶:函数式编程(高阶函数,map,reduce,filter,sorted,返回函数,匿名函数,偏函数)...啊啊啊
函数式编程 函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计.函数就是面向过程的程序设计 ...
- (转)Python进阶:函数式编程(高阶函数,map,reduce,filter,sorted,返回函数,匿名函数,偏函数)
原文:https://www.cnblogs.com/chenwolong/p/reduce.html 函数式编程 函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数 ...
- Python---12函数式编程------12.1高阶函数
函数式编程 函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计.函数就是面向过程的程序设计 ...
- 函数与函数式编程(生成器 && 列表解析 && map函数 && filter函数)-(四)
在学习python的过程中,无意中看到了函数式编程.在了解的过程中,明白了函数与函数式的区别,函数式编程的几种方式. 函数定义:函数是逻辑结构化和过程化的一种编程方法. 过程定义:过程就是简单特殊没有 ...
随机推荐
- bzoj3168 钙铁锌硒维生素 (矩阵求逆+二分图最小字典序匹配)
设第一套为A,第二套为B 先对于每个B[i]判断他能否替代A[j],即B[i]与其他的A线性无关 设$B[i]=\sum\limits_{k}{c[k]*A[k]}$,那么只要看c[j]是否等于零即可 ...
- visp库中解决lapack库的问题
解决的办法是——绕过去,不要用这个库: 使用中发现如下代码抛出异常: //vpTemplateTracker.cpp try { initHessienDesired(I); ptTemplateSu ...
- 基于Redis缓存几十万条记录的快速模糊检索的功能实现(c#)
在开发一套大型的信息系统中,发现很多功能需要按公司查询,各个模块在实现时都是直接查数据库进行模糊检索,虽然对表进行向各个应用的库中进行了同步,但是在使用中发现,模糊检索公司时还是比较卡,原始的查询数据 ...
- pytest 15 fixture之autouse=True
前言 平常写自动化用例会写一些前置的fixture操作,用例需要用到就直接传该函数的参数名称就行了.当用例很多的时候,每次都传这个参数,会比较麻烦.fixture里面有个参数autouse,默认是Fa ...
- JS学习笔记Day21
一.mySQL数据库 (一)数据库的概念 1.概念:可以存储数据的一个仓库 2.结构化数据:以表格的形式展现,结构更清晰,这样的数据称之为结构化数据 (二)数据库管理软件 1.一种对数据库文件进行管理 ...
- CH4INRULZ从渗透到提权
下载了镜像后查看了ip http://192.168.16.128/ 然后用nmap扫描了一波 sudo nmap -vv -sV 192.168.16.128 访问80端口发现是个个人博客 访问80 ...
- nginx配置vue项目部署访问无问题,刷新出现404问题
现象: 在浏览器中直接访问www.test.com/api1/login会404.但如果你先访问www.test.com后再点“登录" 跳转到www.test.com/api1/login是 ...
- 《JAVA并发编程实战》示例程序第一、二章
第一章:简介 程序清单1-1非线程安全的数值序列生成器 import net.jcip.annotations.NotThreadSafe; @NotThreadSafe public class U ...
- jquery弹出窗口选择回写值
$(document).ready(function(){ $('.sel').dblclick(function(){ var nowid=$(this).attr('id'); window.op ...
- Git分支实战入门详细图解
现在我们模拟一个简单的分支和合并案例,其中工作流可供真实项目借鉴. (1)在master开展工作 (2)为新的需求创建分支 (3)在新的分支上展开工作 这时,你接到一个电话,说项目有一个严重的问题需要 ...