sklearn中的损失函数
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

原文链接
https://www.cnblogs.com/nolonely/p/7008952.html
各种损失函数
损失函数或代价函数来度量给定的模型(一次)预测不一致的程度
损失函数的一般形式: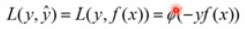
风险函数:度量平均意义下模型预测结果的好坏

损失函数分类:
Zero-one Loss,Square Loss,Hinge Loss,Logistic Loss,Log Loss或Cross-entropy Loss,hamming_loss
分类器中常用的损失函数:
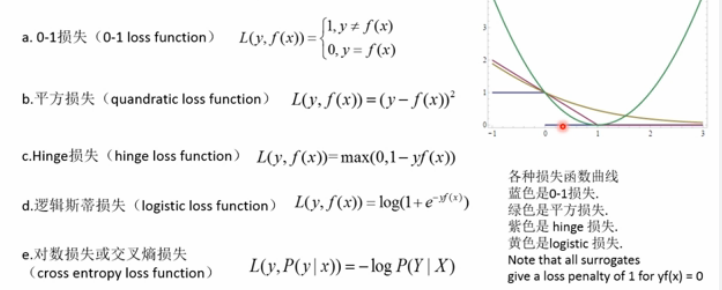
Zero-One Loss
该函数计算nsamples个样本上的0-1分类损失(L0-1)的和或者平均值。默认情况下,返回的是所以样本上的损失的平均损失,把参数normalize设置为False,就可以返回损失值和
在多标签分类问题中,如果预测的标签子集和真实的标签子集严格匹配,zero_one_loss函数给出得分为1,如果没有任何的误差,得分为0
from sklearn.metrics import zero_one_loss
import numpy as np
#二分类问题
y_pred=[1,2,3,4]
y_true=[2,2,3,4]
print(zero_one_loss(y_true,y_pred))
print(zero_one_loss(y_true,y_pred,normalize=False))
#多分类标签问题
print(zero_one_loss(np.array([[0,1],[1,1]]),np.ones((2,2))))
print(zero_one_loss(np.array([[0,1],[1,1]]),np.ones((2,2)),normalize=False)) #结果:
#0.25
#1
#0.5
#1
Hinge Loss
该损失函数通常被用于最大间隔分类器,比如假定类标签+1和-1,y:是真正的类标签,w是decision_function输出的预测到的决策,这样,hinge loss 的定义如下:
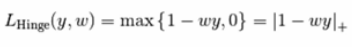
如果标签个数多于2个,hinge_loss函数依据如下方法计算:如果y_w是对真是类标签的预测,并且y_t是对所有其他类标签的预测里边的最大值,multiclass hinge loss定义如下:
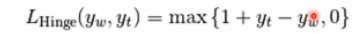
下面的代码展示了用hinge_loss函数度量SVM分类器在二元分类问题中的使用方法:
from sklearn import svm
from sklearn.metrics import hinge_loss
X=[[0],[1]]
y=[-1,1]
est=svm.LinearSVC(random_state=0)
print(est.fit(X,y))
pred_decision=est.decision_function([[-2],[3],[0.5]])
print(pred_decision)
print(hinge_loss([-1,1,1],pred_decision)) #结果
#LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=1000,
multi_class='ovr', penalty='l2', random_state=0, tol=0.0001,
verbose=0)
#[-2.18177262 2.36361684 0.09092211]
#0.303025963688
Log Loss(对数损失)或者Cross-entropy Loss(交叉熵损失)
在二分类时,真是标签集合为{0,1},而分类器预测得到的概率分布为p=Pr(y=1)
每一个样本的对数损失就是在给定真是样本标签的条件下,分类器的负对数思然函数,如下所示:
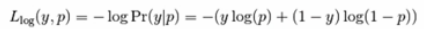
当某个样本的真实标签y=1时,Loss=-log(p),所以分类器的预测概率p=Pr(y=1)的概率越大,则损失越小;如果p=Pr(y=1)的概率越小,则分类损失就越大,对于真是标签y=0,Loss=-log(1-p),所以分类器的预测概率p=Pr(y=1)的概率越大,则损失越大

多分类跟这个类似,不在重复
#Log Loss
from sklearn.metrics import log_loss
y_true=[0,0,1,1]
y_pred=[[0.9,0.1],[0.8,0.2],[0.3,0.7],[0.01,0.99]]
print(log_loss(y_true,y_pred)) #0.173807336691
Hamming Loss,计算两个样本集合之间的平均汉明距离
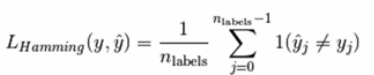
#hamming_loss
from sklearn.metrics import hamming_loss
y_pred=[1,2,3,4]
y_true=[2,2,3,4]
print(hamming_loss(y_true,y_pred)) #0.25
https://study.163.com/provider/400000000398149/index.htm?share=2&shareId=400000000398149( 欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章)

sklearn中的损失函数的更多相关文章
- sklearn中的KMeans算法
1.聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇).这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布. 2.KMeans算法将一 ...
- sklearn中实现随机梯度下降法(多元线性回归)
sklearn中实现随机梯度下降法 随机梯度下降法是一种根据模拟退火的原理对损失函数进行最小化的一种计算方式,在sklearn中主要用于多元线性回归算法中,是一种比较高效的最优化方法,其中的梯度下降系 ...
- sklearn中的Pipeline
在将sklearn中的模型持久化时,使用sklearn.pipeline.Pipeline(steps, memory=None)将各个步骤串联起来可以很方便地保存模型. 例如,首先对数据进行了PCA ...
- Sklearn中的回归和分类算法
一.sklearn中自带的回归算法 1. 算法 来自:https://my.oschina.net/kilosnow/blog/1619605 另外,skilearn中自带保存模型的方法,可以把训练完 ...
- 第十三次作业——回归模型与房价预测&第十一次作业——sklearn中朴素贝叶斯模型及其应用&第七次作业——numpy统计分布显示
第十三次作业——回归模型与房价预测 1. 导入boston房价数据集 2. 一元线性回归模型,建立一个变量与房价之间的预测模型,并图形化显示. 3. 多元线性回归模型,建立13个变量与房价之间的预测模 ...
- sklearn中的模型评估-构建评估函数
1.介绍 有三种不同的方法来评估一个模型的预测质量: estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题. Scor ...
- sklearn中随机森林的参数
一:sklearn中决策树的参数: 1,criterion: ”gini” or “entropy”(default=”gini”)是计算属性的gini(基尼不纯度)还是entropy(信息增益),来 ...
- sklearn中SVM调参说明
写在前面 之前只停留在理论上,没有实际沉下心去调参,实际去做了后,发现调参是个大工程(玄学).于是这篇来总结一下sklearn中svm的参数说明以及调参经验.方便以后查询和回忆. 常用核函数 1.li ...
- 机器学习中的损失函数 (着重比较:hinge loss vs softmax loss)
https://blog.csdn.net/u010976453/article/details/78488279 1. 损失函数 损失函数(Loss function)是用来估量你模型的预测值 f( ...
随机推荐
- react native中一次错误排查 Error:Error: Duplicate resources
最近一直在使用react native中,遇到了很多的坑,同时也学习到了一些移动端的开发经验. 今天在做一个打包的测试时,遇到了一个问题,打包过程中报错“Error:Error: Duplicate ...
- MyDAL - 引用类型对象 .DeepClone() 深度克隆[深度复制] 工具 使用
索引: 目录索引 一.API 列表 .DeepClone() 用于 Model / Entity / ... ... 等引用类型对象的深度克隆 特性说明 1.不需要对对象做任何特殊处理,直接 .Dee ...
- 数据库原理剖析 - 序列1 - B+树
本文节选自<软件架构设计:大型网站技术架构与业务架构融合之道>第6.3章节. 作者微信公众号: 架构之道与术.进入后,可以加入书友群,与作者和其他读者进行深入讨论.也可以在京东.天猫上购买 ...
- c#核心基础 - 浅谈 c# 中的特性 Attribute)
特性(Attribute)是用于在运行时传递程序中各种元素(比如类.方法.结构.枚举.组件等)的行为信息的声明性标签.可以通过使用特性向程序添加声明性信息.一个声明性标签是通过放置在它所应用的元素前面 ...
- SQL SERVER-创建Alwayson
Failover Custer(AlwaysOn) 创建Failover Cluster和启动AlwaysOn 创建Failover Cluster 节点的个数要是奇数如果是偶数则要加一个仲裁磁盘.在 ...
- JS的正则表达式及回文
function palindrome(str) { str = str.replace(/\s/g,"").replace(/[^a-zA-Z0-9]/g,"" ...
- 一:SqlServer中的 CEILING函数和 FLOOR函数以及ROUND()
例如 1.ROUND() 格式为ROUND(y1,y2,y3) y1:要被四舍五入的数字y2:保留的小数位数 y3:为0,可以不写,y1进行四舍五入,不为0则y1不进入四舍五入,如果y1有值就直接根据 ...
- web安全—sql注入漏洞
SQL注入-mysql注入 一.普通的mysql注入 MySQL注入不像注入access数据库那样,不需要猜.从mysql5.0以上的版本,出现一个虚拟的数据库,即:information_schem ...
- 查看redis连接数
在redis-cli命令行使用:info clients可以查看当前的redis连接数. 如下图: config get maxclients 可以查询redis允许的最大连接数. 如下图:
- Python 爬虫基础Selenium
https://blog.csdn.net/weixin_36279318/article/details/79475388