论文阅读(Lukas Neumann——【ICCV2017】Deep TextSpotter_An End-to-End Trainable Scene Text Localization and Recognition Framework)
Lukas Neumann——【ICCV2017】Deep TextSpotter_An End-to-End Trainable Scene Text Localization and Recognition Framework
目录
- 作者和相关链接
- 方法概括
- 方法细节
- 实验结果
- 总结与收获点
- 参考文献和链接
作者和相关链接
- 作者

方法概括
方法概述
- 该方法将文字检测和识别整合到一个端到端的网络中。检测使用YOLOv2+RPN,并利用双线性采样将文字区域统一为高度一致的变长特征序列,再使用RNN+CTC进行识别。
文章亮点
- 检测+识别在一个网络中端到端训练
- 速度很快(100ms/每张图,注意是检测+识别!)
主要流程
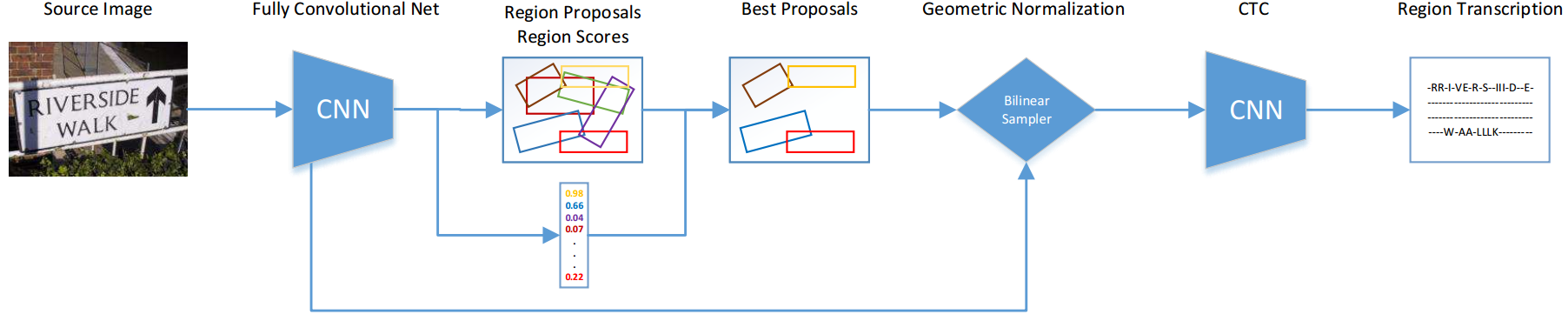
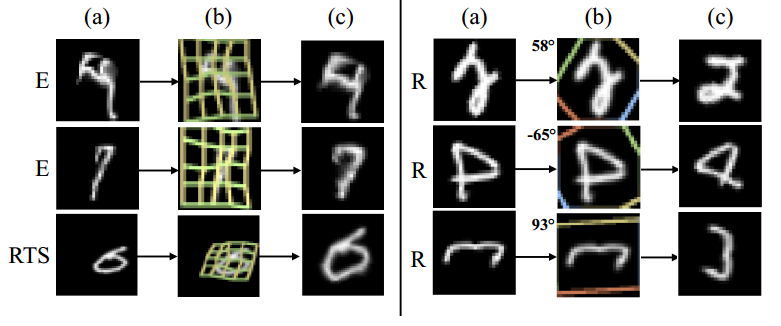
- 如上图,整个端到端识别分为四步:
检测:用去掉全连接层的YOLOv2框架进行fcn+RPN,得到候选文字区域
双线性采样(实际上是一个Spatial Transform module):将大小不同的文字区域统一特征映射为高度一致宽度变长的特征序列
- 识别:将特征序列用rnn得到概率矩阵(带recurrent的fcn),再接CTC得到识别字符串
最后利用识别的打分情况反过来对检测的boundingbox进行nms,得到精确的检测框
- 如上图,整个端到端识别分为四步:
方法细节
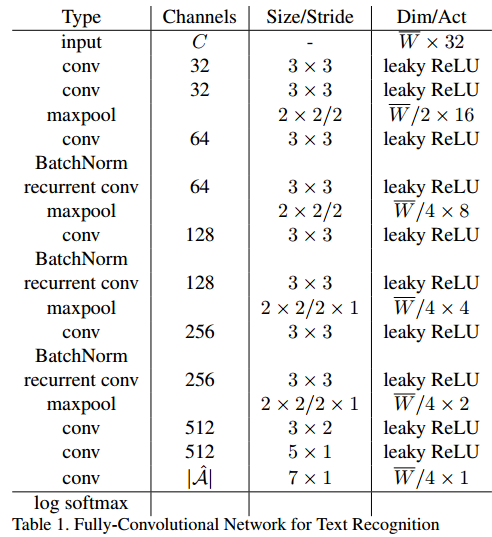
检测的FCN网络
使用YOLOv2的前18个convolution layer和5个max pool layer,去掉了最后的全连接层
最后输出的feature map是:W/32 * H/32 * 1024
Region Proposals
采用类似于RPN的anchor机制
回归参数5个,除了正常的RPN回归的x, y, w, h的相对值,还有角度ɵÎ[-pi/2, pi/2] (这个怎么加入loss?)
每个anchor点有14个anchor box,这14个anchor box的scale、aspects(angle范围怎么设?)通过在训练集上用k-means聚类得到
正负样本选择:IOU最大为正anchor box,其他均为负样本(合理吗?)
- NMS使用:利用识别结果对检测结果进行反馈调整(取识别分数大于阈值的所有框进行nms)
Bilinear Sampling
这步的目的
将前面detection得到的大小不同的region proposal对应的feature统一成固定高度的feature(为了输入到识别的CNN中,识别的CNN有recurrent network,需要固定高度,但宽度可以变长),并且保持特征不会形变太多;
- 这一步为什么不直接用Faster R-CNN中的ROI pooling?
- 答: 第一是因为ROI pooling实际上是固定网格,不论原proposal有多长,最后都会变成比如7*7的网格。而实际的text proposal,文字是变长的,固定网格有可能导致text被拉伸或压缩,造成大的形变;第二(更重要的是)是因为采用ROI pooling只是水平和竖直的grid,无法处理旋转或形变情况。

- Bilinear Sampling是什么?
- 文中用的bilinear sampling 是一个以bilinear interpolation kernel为核的Spatial Transformer。
- Bilinear Sampling是什么?
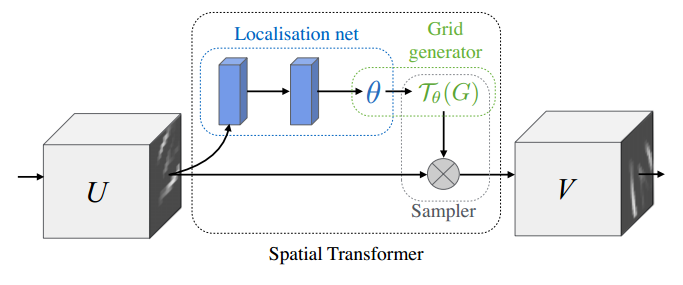
- 一个Spatial Transformer的结构分为三个部分,Localisation net,Grid generator,和Sampler。Localisation net负责学习一组参数(下一步生成网格要用的),其输入为原特征feature map(记为U),输出即参数ɵ。Grid generator负责给定参数ɵ时生成网格Tɵ(G)。最后的Sampler负责把网格Tɵ(G)打在原feature map上,生成最后transform之后的特征(记为V)。
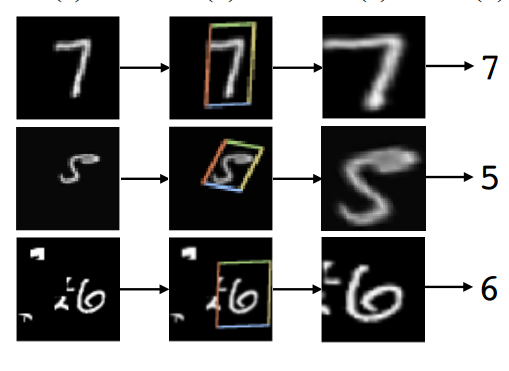
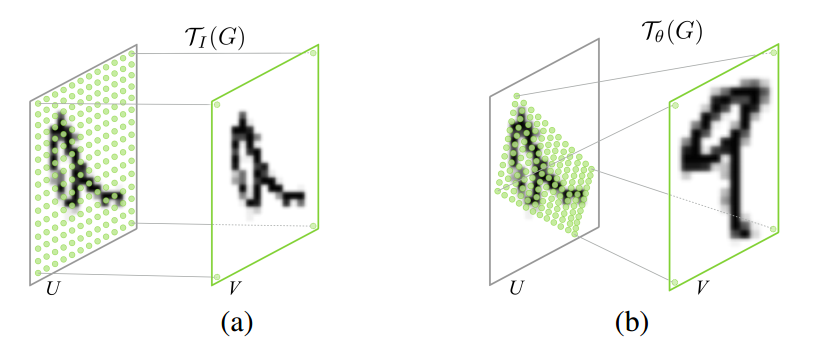
- Spatial Transformer简单来说,实际上是用来做特征变换的,包括扭曲、旋转、平移、尺度变换,它的特点是这个变换的参数不是固定的,而是根据每个样本的不同自己学出来的。
- Bilinear Sampling特征映射公式如下:
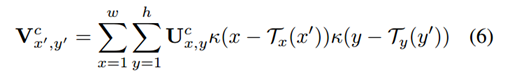
- κ(v) = max(0, 1 - |v|)是一个bilinear sampling kernel,T即为学出来的网格,实际上是一个坐标变换(就是一个矩阵)。
- STN详见论文:Spatial Transformer Networks(参考文献1)
- Bilinear sampling kernel详见论文:Image Fusion Using LEP Filtering and Bilinear Interpolation(参考文献2)
识别
- 传统的变长word识别思路
- 一个超大类分类器(每一个单词就是一类)
- 多个二类分类器(每一个位置预测一下是哪一类,类数=字符的总类数,例如英文就是62类)
- 识别流程
- 识别FCN(带RNN的)+ CTC(Connectionist Temporal Classification)
- 识别FCN
- 一堆conv + pool + recurrent conv + batch norm,最后接一个softmax
- 传统的变长word识别思路
- CTC(Connectionist Temporal Classification)
- CTC的功能在于可以根据一个概率矩阵得到最可能的序列结果。这个输入的概率矩阵设为A(i, j),i Î[1, m],jÎ[1, n],m表示字符的类别总数(包括背景类,英文即为63类),是一个固定值,n与输入的图像长度相关(本文n=w/4)。A(i, j)可以理解为在水平位置i的滑窗里包含第j个字符的概率大小。输出的序列结果例如“text”等即为最终的识别结果。
- CTC(Connectionist Temporal Classification)
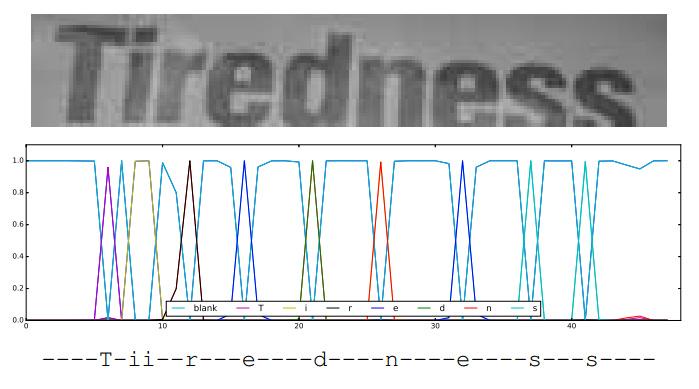
Figure 4. Text recognition using Connectionist Temporal Classification. Input W × 32 region (top), CTC output W 4 × |A| ˆ as the most probable class at given column (middle) and the resulting sequence (bottom)
- CTC操作首先去掉空格和重复的字符(即为化简),然后对化简之后得到同一个单词的串概率求和,最后取总概率最大的字符串即为最终的识别结果。
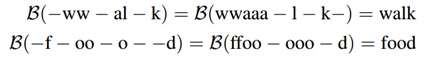
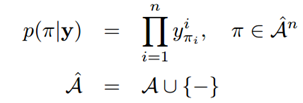

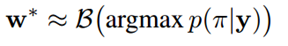
Training
检测和识别单独预训练,然后端到端再合起来训练
检测预训练:SynthText (80万),3epoch,ImageNet预训练模型
识别预训练:Synthetic Word(900万),3epoch,随机初始化N(0,1)
合起来训练:SynthText + Synthetic Word + ICDAR2013-train + ICDAR2015-train, 3epoch,每张图随机crop30%,momentum = 0.9,lr = 0.001,每个epoch将10倍
实验结果
- 速度说明
- Nvidia K80 GPU
- ICDAR2013:图像大小resize成544*544,100ms/每张图
- ICDAR2015:图像大小608*608,110ms/每张图
- ICDAR2013
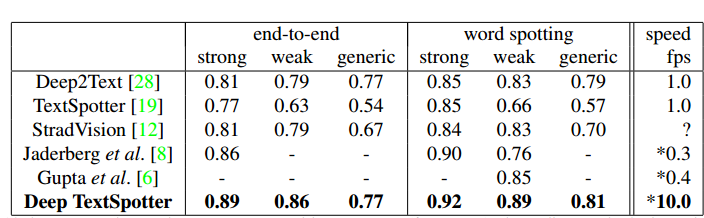
- ICDAR2015

总结与收获
- 检测这边基本上是用yolov2,不一样的点在于:第一,加了角度信息;第二,anchor的选择是通过kmeans确定的,虽然有点trick,但感觉也挺有道理的,虽然作者没有验证这样做的generalization;
- 个人觉得文中最好的点是加入了spatial transform(文中叫bilinear sampling),虽然也不是作者提出的,但作者用在检测+识别中间是第一个,也很有意思。值得一提的是,stn的paper中说stn没有增加多少耗时;
- 识别这边像是自己设计的简化的网络,RNN+CTC是正常的识别方法;
- 端到端训练可以借鉴,先预训练检测+预训练识别+合起来训练。
参考文献
- M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In Advances in Neural Information Processing Systems, pages 2017–2025, 2015. 2, 3
- Raveendran H, Thomas D. Image Fusion Using LEP Filtering and Bilinear Interpolation. International Journal of Engineering Trends and Technology (IJETT) 2014, Volume 12 Number 9
论文阅读(Lukas Neumann——【ICCV2017】Deep TextSpotter_An End-to-End Trainable Scene Text Localization and Recognition Framework)的更多相关文章
- 论文阅读(Lukas Neuman——【ICDAR2015】Efficient Scene Text Localization and Recognition with Local Character Refinement)
Lukas Neuman--[ICDAR2015]Efficient Scene Text Localization and Recognition with Local Character Refi ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- 【论文阅读】HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
转载请注明出处:https://www.cnblogs.com/White-xzx/ 原文地址:https://arxiv.org/abs/1709.09930 Github: https://git ...
- 论文阅读 | Towards a Robust Deep Neural Network in Text Domain A Survey
摘要 这篇文章主要总结文本中的对抗样本,包括器中的攻击方法和防御方法,比较它们的优缺点. 最后给出这个领域的挑战和发展方向. 1 介绍 对抗样本有两个核心:一是扰动足够小:二是可以成功欺骗网络. 所有 ...
- [论文阅读] ImageNet Classification with Deep Convolutional Neural Networks(传说中的AlexNet)
这篇文章使用的AlexNet网络,在2012年的ImageNet(ILSVRC-2012)竞赛中获得第一名,top-5的测试误差为15.3%,相比于第二名26.2%的误差降低了不少. 本文的创新点: ...
- 【论文阅读】An Anchor-Free Region Proposal Network for Faster R-CNN based Text Detection Approaches
懒得转成文字再写一遍了,直接把做过的PPT放出来吧. 论文连接:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1804.09003v1. ...
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 【医学图像】3D Deep Leaky Noisy-or Network 论文阅读(转)
文章来源:https://blog.csdn.net/u013058162/article/details/80470426 3D Deep Leaky Noisy-or Network 论文阅读 原 ...
随机推荐
- 【AtCoder】【模型转化】【二分答案】Median Pyramid Hard(AGC006)
题意: 给你一个排列,有2*n-1个元素,现在进行以下的操作: 每一次将a[i]替换成为a[i-1],a[i],a[i+1]三个数的中位数,并且所有的操作是同时进行的,也就是说这一次用于计算的a[], ...
- [Error]Python虚拟环境报错 OSError: setuptools pip wheel failed with error code 2
mkvirtualenv py35 python新建虚拟环境报错,setuptools pip wheel failed with error code 2 刚好昨天在CentOS安装的时候也总是报s ...
- Ackerman
Ackerman 递归算法 一 . 问题描述及分析 图1 二 . 代码实现 package other; import java.io.BufferedWriter; import java.io.F ...
- jquery复制图片
<div class="img-div"> <a href="javascript:void(0);"><im ...
- CSS3_线性渐变_径向渐变----背景
渐变的本质: 绘制一张背景图片,所以使用 background 或者 background-image background 的诸多属性,渐变都是可以使用的(repeat,position) 百分比: ...
- (66)Wangdao.com第十一天_JavaScript 数组Array
数组 Array 本质上,数组属于一种特殊的对象.typeof 运算符会返回数组的类型是 object 数组的特殊性体现在,它的键名是按次序排列的一组整数(0,1,2...) // Object.ke ...
- [LeetCode] Bricks Falling When Hit 碰撞时砖头掉落
We have a grid of 1s and 0s; the 1s in a cell represent bricks. A brick will not drop if and only i ...
- centos7下NFS使用与配置
NFS是Network File System的缩写,即网络文件系统.客户端通过挂载的方式将NFS服务器端共享的数据目录挂载到本地目录下. nfs为什么需要RPC?因为NFS支持的功能很多,不同功能会 ...
- 纯js自动批量引入js、css插件,支持自定义参数
//autoload.js ;! function(e) { var autoload = e.autoload || {}; e.autoload = autoload; e.autoload = ...
- float和double的最大值和最小值