使用scrapy选择器selector解析获取百度结果
0x00 概述
需要成功安装scrapy,安装方法与本文无关,不在这多说。
0x01 配置settings
由于百度对于user-agent进行验证,所以需要添加。
settings.py中找到DEFAULT_REQUEST_HEADERS,设置好后如下:
DEFAULT_REQUEST_HEADERS = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.0.4.3000 Chrome/47.0.2526.73 Safari/537.36',
}
settings.py中找到ROBOTSTXT_OBEY,设置好后如下:
ROBOTSTXT_OBEY = False
0x02 写个爬虫
spider文件夹中建立baidu_spider.py,内容如下:
import scrapy
from scrapy.selector import Selector
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["baidu.com"]
start_urls = [
"https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=1111&rsv_pq=e99a82620002899b&rsv_t=9aeedvIqMvwImRMhMsGBvD%2BjM%2Fd%2Byd10oiaBWGgrEiZ79fKqGUhhZCWWE0w&rqlang=cn&rsv_enter=1&rsv_sug3=4&rsv_sug1=1&rsv_sug7=100"
] def parse(self, response):
sel = Selector(response)
print sel.xpath('//h3[@class="t"]/a/text()')
print sel.xpath('//h3[@class="t"]/a/@href')
0x03 看下结果
运行scrapy crawl dmoz命令。
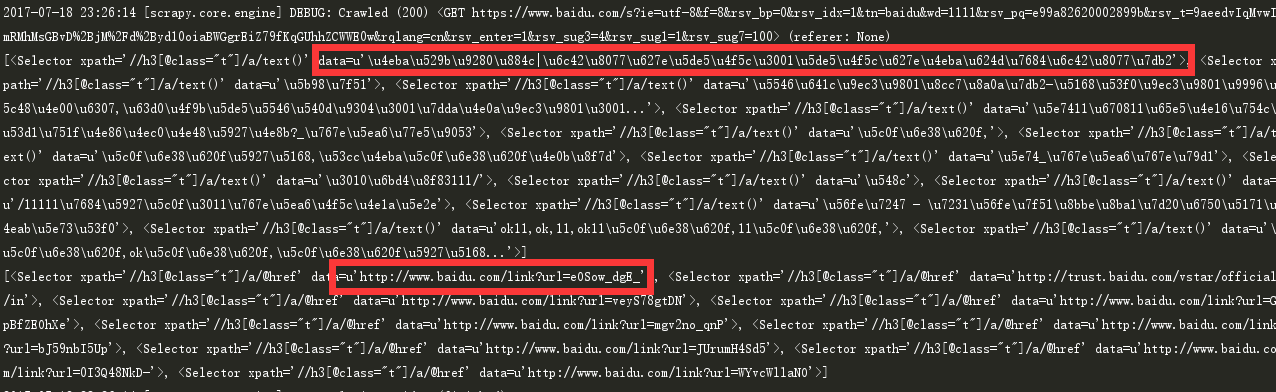
内容和链接已经抓取出来,结果如下:
使用scrapy选择器selector解析获取百度结果的更多相关文章
- scrapy 中用selector来提取数据的用法
一. 基本概念 1. Selector是一个可独立使用的模块,我们可以用Selector类来构建一个选择器对象,然后调用它的相关方法如xpaht(), css()等来提取数据,如下 from sc ...
- scrapy中Selector的使用
scrapy的Selector选择器其实也可以用来解析,今天主要总结下css和xpath的用法,其实我个人最喜欢用css 以慕课网嵩天老师教程中的一个网页为例,python123.io/ws/demo ...
- 获取百度地图POI数据三(模拟关键词搜索)
上一篇博文中讲到如何获取用于搜索的关键词,并且已经准备好了一百五十万的关键词 这其中有门牌号码,餐馆酒店名称,公司名称,道路名称等.有了这些数据,我们就可以通过代码,模拟我们在百度地图的搜索框中搜 ...
- 获取百度地图POI数据二(准备搜索关键词)
上篇讲到 想要获取尽可能多的POI数据 需要准备尽可能多的搜索关键字 那么这些关键字如何得来呢? 本人使用的方法是通过一些网站来获取这些关键词 http://poi.mapbar.com ...
- Flume-NG源码阅读之SourceRunner,及选择器selector和拦截器interceptor的执行
在AbstractConfigurationProvider类中loadSources方法会将所有的source进行封装成SourceRunner放到了Map<String, SourceRun ...
- jquery 选择器(selector)和事件(events)
页面加载完成后开始运行do stuff when DOM is ready 中的语句! $(document).ready(function() { // do stuff when DO ...
- 【微信小程序】获取用户地理位置权限,二次请求授权,逆解析获取地址
摘要:微信小程序内获取用户地理位置信息授权,被拒绝后二次获取,获取权限后逆解析得到用户所在省市区等.. 场景:商城类小程序,在首页时需展示附近门店,即用户刚进入小程序时就需要获取到用户位置信息 ste ...
- NIO 选择器 Selector
选择器提供选择执行已经就绪的任务的能力,这使得多元 I/O 成为可能.就像在第一章中描述的那样,就绪选择和多元执行使得单线程能够有效率地同时管理多个 I/O 通道(Channels).C/C++代码的 ...
- 030 Android 第三方开源下拉框:NiceSpinner的使用+自定义Button样式+shape绘制控件背景图+图片选择器(selector)
1.NiceSpinner下拉框控件介绍 Android原生的下拉框Spinner基本上可以满足Android开发对于下拉选项的设计需求,但现在越来越流行的下拉框不满足于Android原生提供的下拉框 ...
随机推荐
- Python 之网络式编程
一 客户端/服务器架构 即C/S架构,包括 1.硬件C/S架构(打印机) 2.软件B/S架构(web服务) C/S架构与Socket的关系: 我们学习Socket就是为了完成C/S的开发 二 OSI七 ...
- LinuxMint(Ubuntu)安装文泉驿家族黑体字
文泉驿黑体字家族在Ubuntu上很有用,可以解决系统字体发虚的问题. 通过下面的三条命令安装: sudo apt-get install ttf-wqy-microhei #文泉驿-微米黑 sudo ...
- R语言学习——图形初阶之散点图
使用R内置的数据框mtcars,绘制车身重量与每加仑汽油行驶的英里数的散点图,要求横轴为车身重量(wt),纵轴为每加仑汽油行驶的英里数(mpg),并添加最优拟合曲线.标题,输出为pdf文件.代码实现如 ...
- 如何配置jenkins 与代理服务器吗?
0 我们面临一些问题使用代理服务器(即缓存服务器)和詹金斯是希望有人可以提供如果他们有类似的设置. Herea年代简要描述的设置: 在主站点反向代理,JTS & CCM服 ...
- Elasticsearch 通关教程(四): 分布式工作原理
前言 通过前面章节的了解,我们已经知道 Elasticsearch 是一个实时的分布式搜索分析引擎,它能让你以一个之前从未有过的速度和规模,去探索你的数据.它被用作全文检索.结构化搜索.分析以及这三个 ...
- Elastic Stack-Elasticsearch使用介绍(四)
一.前言 上一篇说了一下查询和存储机制,接下来我们主要来说一下排序.聚合.分页: 写完文章以后发现之前文章没有介绍Coordinating Node,这个地方补充说明下Coordinating ...
- django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb module: No module named 'MySQLdb'. Did you install mysqlclient or MySQL-python?
Error msg: Unhandled exception in thread started by <function check_errors.<locals>.wrapper ...
- flutter Provide 状态管理篇
Provide是Google官方推出的状态管理模式.官方地址为: https://github.com/google/flutter-provide 现在Flutter的状态管理方案很多,redux. ...
- dva
import React, { PureComponent } from "react"; import { Chart, Geom, Axis, Tooltip, Coord, ...
- Vue实现树形下拉框
Vue自身并没有实现树形下拉框的组件,找了很多资料,最后在Github上找了个插件vue-treeselect,功能还是比较全的,模糊搜索.多选.延迟加载.异步搜索.排序,自定义.Vuex支持等等.这 ...