Lucene 09 - 什么是Lucene的高亮显示 + Java API实现高亮显示
1 什么是高亮显示
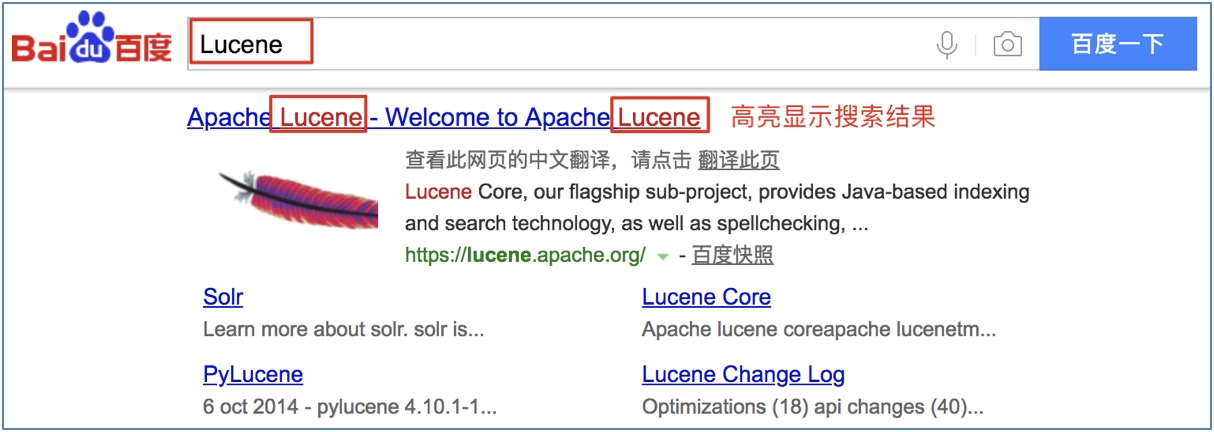
高亮显示是全文检索的一个特点, 指的在搜索结果中对关键词突出显示(加粗和增加颜色).
2 高亮显示实现
Lucene提供了高亮显示组件, 支持高亮显示.
2.1 配置pom.xml文件, 加入高亮显示支持
<project>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- mysql版本 -->
<mysql.version>5.1.30</mysql.version>
<!-- lucene版本 -->
<lucene.version>4.10.3</lucene.version>
<!-- ik分词器版本 -->
<ik.version>2012_u6</ik.version>
</properties>
<dependencies>
// ......
<!--lucene高亮显示 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>${lucene.version}</version>
</dependency>
</dependencies>
</project>
2.2 代码实现
步骤为:
(1) 创建分值对象(QueryScorer), 用于计算高亮显示内容的评分;
(2) 创建输出片段对象(Fragmenter), 用于将高亮显示内容切片;
(3) 创建高亮组件对象(Highlighter), 实现高亮显示;
(4) 创建分析器对象(Analyzer), 用于分词;
(5) 使用TokenSources类, 获取高亮显示内容的流对象(TokenStream);
(6) 使用Highlighter对象, 完成高亮显示.
/**
* 封装搜索方法(高亮显示的方法)
*/
private void searcherHighlighter(Query query) throws Exception {
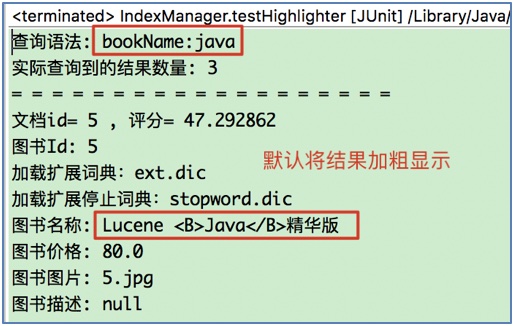
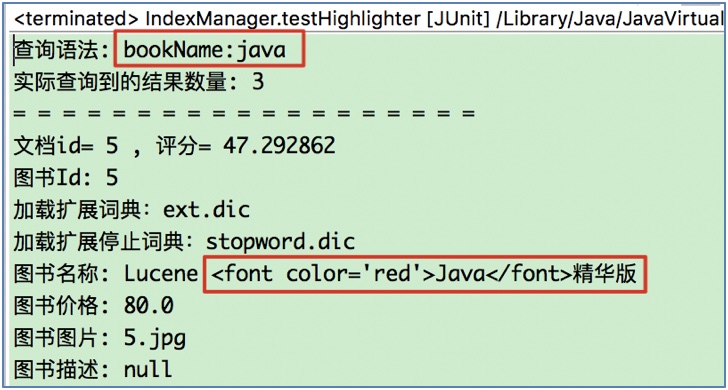
// 打印Query对象生成的查询语法
System.out.println("查询语法: " + query);
// 1.创建索引库目录位置对象(Directory), 指定索引库的位置
Directory directory = FSDirectory.open(new File("/Users/healchow/Documents/index"));
// 2.创建索引读取对象(IndexReader), 用于将索引数据读取到内存中
IndexReader reader = DirectoryReader.open(directory);
// 3.创建索引搜索对象(IndexSearcher), 用于执行搜索
IndexSearcher searcher = new IndexSearcher(reader);
// 4. 使用IndexSearcher对象执行搜索, 返回搜索结果集TopDocs
// 参数一:使用的查询对象, 参数二:指定要返回的搜索结果排序后的前n个
TopDocs topDocs = searcher.search(query, 10);
// 增加高亮显示处理 ============================== start
// 1.建立分值对象(QueryScorer), 用于对高亮显示内容打分
QueryScorer qs = new QueryScorer(query);
// 2.建立输出片段对象(Fragmenter), 用于把高亮显示内容切片
Fragmenter fragmenter = new SimpleSpanFragmenter(qs);
// 3.建立高亮组件对象(Highlighter), 实现高亮显示
Highlighter lighter = new Highlighter(qs);
// 设置切片对象
lighter.setTextFragmenter(fragmenter);
// 4.建立分析器对象(Analyzer), 用于分词
Analyzer analyzer = new IKAnalyzer();
// 增加高亮显示处理 ============================== end
// 5. 处理结果集
// 5.1 打印实际查询到的结果数量
System.out.println("实际查询到的结果数量: " + topDocs.totalHits);
// 5.2 获取搜索的结果数组
// ScoreDoc中有文档的id及其评分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
System.out.println("= = = = = = = = = = = = = = = = = = =");
// 获取文档的id和评分
int docId = scoreDoc.doc;
float score = scoreDoc.score;
System.out.println("文档id= " + docId + " , 评分= " + score);
// 根据文档Id, 查询文档数据 -- 相当于关系数据库中根据主键Id查询数据
Document doc = searcher.doc(docId);
System.out.println("图书Id: " + doc.get("bookId"));
// 实现图书名称的高亮显示
String bookName = doc.get("bookName");
if(bookName != null) {
// 5.使用TokenSources类, 获取高亮显示内容流对象(TokenStream)
// getTokenStream方法: 获取当前文档的流对象
// 参数一: 当前的文档对象
// 参数二: 要高亮显示的域名称
// 参数三: 分析器对象
TokenStream tokenStream = TokenSources.getTokenStream(doc, "bookName", analyzer);
// 6.使用高亮组件对象,完成高亮显示
// getBestFragment方法:获取高亮显示结果内容
// 参数一: 当前文档对象的流对象
// 参数二: 要高亮显示的目标内容
bookName = lighter.getBestFragment(tokenStream, bookName);
}
System.out.println("图书名称: " + bookName);
System.out.println("图书价格: " + doc.get("bookPrice"));
System.out.println("图书图片: " + doc.get("bookPic"));
System.out.println("图书描述: " + doc.get("bookDesc"));
}
// 8. 关闭资源
reader.close();
}
/**
* 测试高亮显示 需求:把搜索结果中,图书名称进行高亮显示(关键词值java)
* @throws Exception
*/
@Test
public void testHighlighter() throws Exception {
//1.创建查询对象
TermQuery tq = new TermQuery(new Term("bookName","java"));
// 2.执行高亮搜索
this.searcherHighlighter(tq);
}
2.3 自定义html标签高亮显示
问题: 实际项目中,如何实现用自定义的HTML标签,进行搜索结果的高亮显示?
① 创建HTML标签格式化对象(SimpleHTMLFormatter);
② 创建高亮显示组件对象(Highlighter), 指定使用SimpleHTMLFormatter对象.
// 增加高亮显示处理 ============================== start
// 1.建立分值对象(QueryScorer), 用于对高亮显示内容打分
QueryScorer qs = new QueryScorer(query);
// 2.建立输出片段对象(Fragmenter), 用于把高亮显示内容切片
Fragmenter fragmenter = new SimpleSpanFragmenter(qs);
// 3.建立高亮组件对象(Highlighter), 实现高亮显示
// 3.1.实现自定义的HTML标签进行高亮显示搜索结果
// 1) 建立高亮显示HTML格式化标签对象(SimpleHTMLFormatter), 参数说明:
// preTag: 指定HTML标签的开始部分(<font color='red'>)
// postTag: 指定HTML标签的结束部分(</font>)
SimpleHTMLFormatter formatter = new SimpleHTMLFormatter("<font color='red'>", "</font>");
// 2) 指定高亮显示组件对象(Highter), 使用SimpleHTMLFormatter对象
Highlighter lighter = new Highlighter(formatter, qs);
// 设置切片对象
lighter.setTextFragmenter(fragmenter);
// 4.建立分析器对象(Analyzer), 用于分词
Analyzer analyzer = new IKAnalyzer();
// 增加高亮显示处理 ============================== end
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.
Lucene 09 - 什么是Lucene的高亮显示 + Java API实现高亮显示的更多相关文章
- Lucene 08 - 什么是Lucene的相关度排序 + Java API调整相关度
目录 1 什么是相关度 2 相关度评分 3 相关度设置 3.1 更改相关度的需求 3.2 实现需求-设置广告 1 什么是相关度 概念: 相关度指两个事物之间的关联关系(相关性). Lucene中指的是 ...
- Lucene 04 - 学习使用Lucene的Field(字段)
目录 1 Field的特性 2 常用的Field类型 3 常用的Field种类使用 3.1 准备环境 3.2 需求分析 3.3 修改代码 3.4 重新建立索引 1 Field的特性 Document( ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- Lucene系列二:Lucene(Lucene介绍、Lucene架构、Lucene集成)
一.Lucene介绍 1. Lucene简介 最受欢迎的java开源全文搜索引擎开发工具包.提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言).Lucene的目的是为软件开发人 ...
- Elasticsearch 2.3.3 JAVA api说明文档
原文地址:https://www.blog-china.cn/template\documentHtml\1484101683485.html 翻译作者:@青山常在人不老 加入翻译:cdcnsuper ...
- ElasticSearch6.0 Java API 使用 排序,分组 ,创建索引,添加索引数据,打分等(一)
ElasticSearch6.0 Java API 使用 排序,分组 ,创建索引,添加索引数据,打分等 如果此文章对你有帮助,请关注一下哦 1.1 搭建maven 工程 创建web工程 ...
- Elastic Stack 笔记(八)Elasticsearch5.6 Java API
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 底层依赖于 Lucene 库,而 Lucene 库完全是 Java 编写的,前面的文章都是发送的 RESTf ...
- Elasticsearch Java API 很全的整理
Elasticsearch 的API 分为 REST Client API(http请求形式)以及 transportClient API两种.相比来说transportClient API效率更高, ...
- 使用Java操作Elasticsearch(Elasticsearch的java api使用)
1.Elasticsearch是基于Lucene开发的一个分布式全文检索框架,向Elasticsearch中存储和从Elasticsearch中查询,格式是json. 索引index,相当于数据库中的 ...
随机推荐
- selenium操作浏览器窗口最大化和刷新
实际测试过程中经常遇到打开一个页面并不是全屏显示,但是却希望它能够全屏显示或者新增一条记录后需要刷新一下看能不能再列表中正常显示. 于是就有了今天的关于对浏览器窗口的最大化和刷新页面.需要说明的一点: ...
- Java 多文件压缩成一个文件工具类
简单修改来自博客园勇闯天涯zfc的博客 一.内容 ①使用 Java 将多个文件打包压缩成一个压缩文件: ②主要使用 java.io 下的类 二.源代码:ZIPUtil .java import jav ...
- Linux网络文件系统的实现与调试
NFS协议 NFS (网络文件系统)不是传统意义上的文件系统,而是访问远程文件系统的网络协议.整个NFS服务的TCP/IP协议栈如下图所示,NFS是应用层协议,表示层是XDR,会话层是RPC,传输层同 ...
- 原生JS制作简易Tabs组件
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- [转].Net-C#的委托(代理)和事件
一.代理 首先我们要弄清代理是个什么东西.别让一串翻译过来的概念把大家搞晕了头.有的文章把代理称委托.代表等,其实它们是一个东西,英文表述都是“Delegate”.由于没有一本权威的书来规范这个概念, ...
- Mem系列函数介绍及案例实现
昨天导师甩给我们一个项目案例,让我们自己去看一看熟悉一下项目内容,我看到了这个项目里面大量使用memset(sBuf,0,sizeof(sBuf));这一块内存填充的代码,于是回想起以前查过Mem ...
- Linux进阶命令用法
1.tr命令 可以对来自标准输入的字符进行替换.压缩和删除.它可以将一组字符变成另一组字符 选项 -c或——complerment:取代所有不属于第一字符集的字符: -d或——delete:删除所有属 ...
- async与defer
<script>元素的几种常见属性: async 异步加载,立即下载,不应妨碍页面其他操作,标记为 async 的异步脚本并不保证按照指定的先后顺序执行,因此异步脚本不应该在加载期间修改 ...
- LeetCode 33 Search in Rotated Sorted Array [binary search] <c++>
LeetCode 33 Search in Rotated Sorted Array [binary search] <c++> 给出排序好的一维无重复元素的数组,随机取一个位置断开,把前 ...
- hadoop源码学习(二)之ZooKeeper
要能够熟练使用hadoop,就得对其原理和源码有些了解.hadoop中比较重要的概念是NameNode,DataNode,去看这些类时,又会发现其使用了ZooKeeper包,这样就可以将hadoop的 ...