Lucene 04 - 学习使用Lucene的Field(字段)
1 Field的特性
Document(文档)是Field(域)的承载体, 一个Document由多个Field组成. Field由名称和值两部分组成, Field的值是要索引的内容, 也是要搜索的内容.
是否分词(tokenized)
是: 将Field的值进行分词处理, 分词的目的是为了索引. 如: 商品名称, 商品描述. 这些内容用户会通过输入关键词进行查询, 由于内容多样, 需要进行分词处理建立索引.
否: 不做分词处理. 如: 订单编号, 身份证号, 是一个整体, 分词以后就失去了意义, 故不需要分词.
是否索引(indexed)
是: 将Field内容进行分词处理后得到的词(或整体Field内容)建立索引, 存储到索引域. **索引的目的是为了搜索. **如: 商品名称, 商品描述需要分词建立索引. 订单编号, 身份证号作为整体建立索引. **只要可能作为用户查询条件的词, 都需要索引. **
否: 不索引. 如: 商品图片路径, 不会作为查询条件, 不需要建立索引.
是否存储(stored)
是: 将Field值保存到Document中. 如: 商品名称, 商品价格. **凡是将来在搜索结果页面展现给用户的内容, 都需要存储. **
否: 不存储. 如: 商品描述. 内容多格式大, 不需要直接在搜索结果页面展现, 不做存储. 需要的时候可以从关系数据库取.
2 常用的Field类型
以下是企业项目开发中常用的Field类型:
| Field类型 | 数据类型 | 是否分词 | 是否索引 | 是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue, Store.YES) | 字符串 | N | Y | Y/N | 字符串类型Field, 不分词, 作为一个整体进行索引 (如: 身份证号, 订单编号), 是否需要存储由Store.YES或Store.NO决定 |
| LongField(FieldName, FieldValue, Store.YES) | 数值型代表 | Y | Y | Y/N | Long数值型Field代表, 分词并且索引(如: 价格), 是否需要存储由Store.YES或Store.NO决定 |
| StoredField(FieldName, FieldValue) | 重载方法, 支持多种类型 | N | N | Y | 构建不同类型的Field, 不分词, 不索引, 要存储. (如: 商品图片路径) |
| TextField(FieldName, FieldValue, Store.NO) | 文本类型 | Y | Y | Y/N | 文本类型Field, 分词并且索引, 是否需要存储由Store.YES或Store.NO决定 |
3 常用的Field种类使用
3.1 准备环境
复制Lucene 02 - Lucene的入门程序(Java API的简单使用)中的lucene-first项目, 修改名称为lucene-second;
修改pom.xml文件, 将所有的lucene-first修改为lucene-second.
3.2 需求分析
| Field名称 | 是否分词 | 是否索引 | 是否存储 | Field类型 |
|---|---|---|---|---|
| 图书id | 不需要 | 需要(这里可以索引, 也可以不索引) | 需要 | StringField |
| 图书名称 | 需要 | 需要 | 需要 | TextField |
| 图书价格 | 需要 | 需要(数值型的Field, Lucene使用内部分词) | 需要 | FloatField |
| 图书图片 | 不需要 | 不需要 | 需要 | StoredField |
| 图书描述 | 需要 | 需要 | 不需要 | TextField |
3.3 修改代码
public class IndexManager {
/**
* 创建索引功能的测试
* @throws Exception
*/
@Test
public void createIndex() throws IOException{
// 1. 采集数据
BookDao bookDao = new BookDaoImpl();
List<Book> books = bookDao.listAll();
// 2. 创建文档对象
List<Document> documents = new ArrayList<Document>();
for (Book book : books) {
Document document = new Document();
// 给文档对象添加域
// add方法: 把域添加到文档对象中, field参数: 要添加的域
// TextField: 文本域, 属性name:域的名称, value:域的值, store:指定是否将域值保存到文档中
// 图书Id --> StringField
document.add(new StringField("bookId", book.getId() + "", Store.YES));
// 图书名称 --> TextField
document.add(new TextField("bookName", book.getBookname(), Store.YES));
// 图书价格 --> FloatField
document.add(new FloatField("bookPrice", book.getPrice(), Store.YES));
// 图书图片 --> StoredField
document.add(new StoredField("bookPic", book.getPic()));
// 图书描述 --> TextField
document.add(new TextField("bookDesc", book.getBookdesc(), Store.NO));
// 将文档对象添加到文档对象集合中
documents.add(document);
}
// 3. 创建分析器对象(Analyzer), 用于分词
Analyzer analyzer = new StandardAnalyzer();
// 4. 创建索引配置对象(IndexWriterConfig), 用于配置Lucene
// 参数一:当前使用的Lucene版本, 参数二:分析器
IndexWriterConfig indexConfig = new IndexWriterConfig(Version.LUCENE_4_10_2, analyzer);
// 5. 创建索引库目录位置对象(Directory), 指定索引库的存储位置
File path = new File("/Users/healchow/Documents/index");
Directory directory = FSDirectory.open(path);
// 6. 创建索引写入对象(IndexWriter), 将文档对象写入索引
IndexWriter indexWriter = new IndexWriter(directory, indexConfig);
// 7. 使用IndexWriter对象创建索引
for (Document doc : documents) {
// addDocement(doc): 将文档对象写入索引库
indexWriter.addDocument(doc);
}
// 8. 释放资源
indexWriter.close();
}
}
3.4 重新建立索引
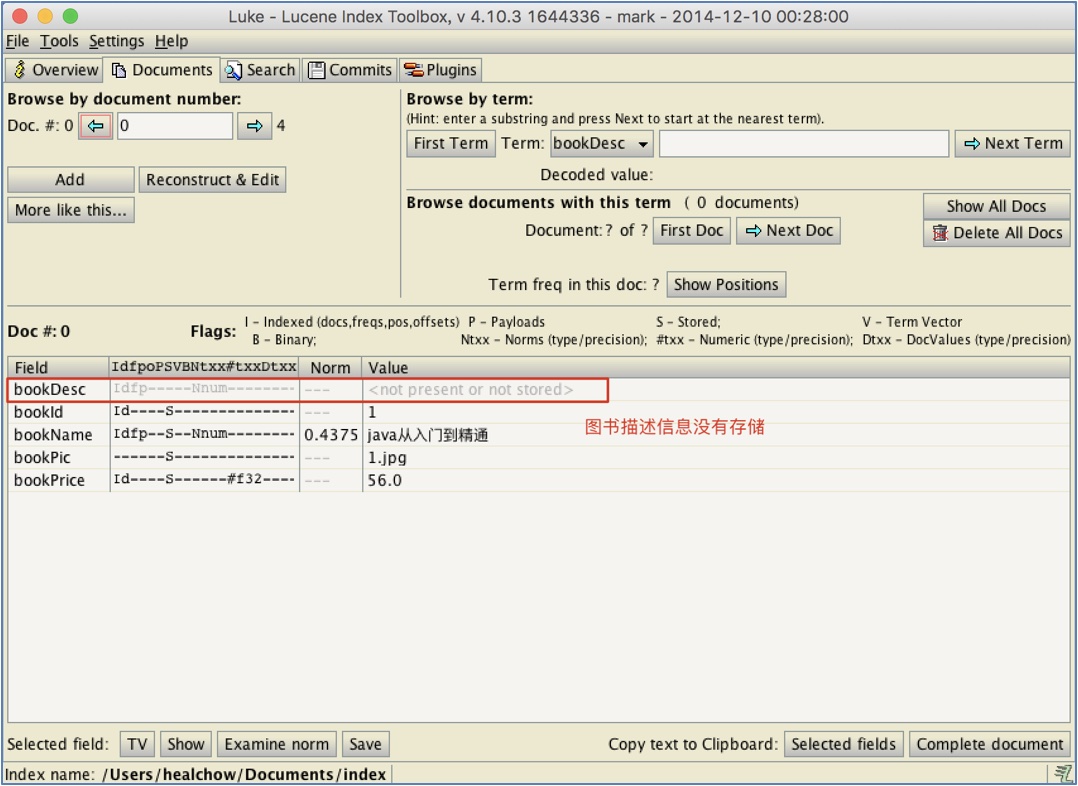
删除之前建立的索引, 再次建立索引. 打开Luke工具查看索引信息, 可看到图书图片不分词, 故没有索引, 图书价格使用了Lucene的内部分词, 故按照UTF-8解码后显示乱码, 如下图示:

图书的描述信息没有存储:
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.
Lucene 04 - 学习使用Lucene的Field(字段)的更多相关文章
- lucene如何通过docId快速查找field字段以及最近距离等信息?
http://www.cnblogs.com/LBSer/p/4419052.html 1 问题描述 我们的检索排序服务往往需要结合个性化算法来进行重排序,一般来说分两步:1)进行粗排序,这一过程由检 ...
- Lucene全文检索学习笔记
全文索引 介绍Lucene的作者:Lucene的贡献者Doug Cutting是 一位资深全文索引/检索专家,曾经是V-Twin搜索引擎(Apple的Copland操作系统的成就之一)的主要开发者,后 ...
- 【Todo】Lucene系统学习
之前已经写过一篇关于Lucene安装学习的文章:http://www.cnblogs.com/charlesblc/p/5980525.html 还有一篇关于Solr安装使用的文章:http://ww ...
- Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息
Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息 在此回复牛妞的关于程序中分词器的问题,其实可以直接很简单的在词库中配置就好了,Lucene中分词的所有信息我们都可以从 ...
- lucene&solr学习——创建和查询索引(理论)
1.Lucene基础 (1) 简介 Lucene是apache下的一个开放源代码的全文检索引擎工具包.提供完整的查询引擎和索引引擎:部分文本分析引擎. Lucene的目的是为软件开发人员提供一个简单易 ...
- Lucene的学习及使用实验
实验一下Lucene是怎么使用的. 参考:http://www.importnew.com/12715.html (例子比较简单) http://www.yiibai.com/lucene/lucen ...
- (转)全文检索技术学习(一)——Lucene的介绍
http://blog.csdn.net/yerenyuan_pku/article/details/72582979 本文我将为大家讲解全文检索技术——Lucene,现在这个技术用到的比较多,我觉得 ...
- Lucene系列六:Lucene搜索详解(Lucene搜索流程详解、搜索核心API详解、基本查询详解、QueryParser详解)
一.搜索流程详解 1. 先看一下Lucene的架构图 由图可知搜索的过程如下: 用户输入搜索的关键字.对关键字进行分词.根据分词结果去索引库里面找到对应的文章id.根据文章id找到对应的文章 2. L ...
- Lucene系列五:Lucene索引详解(IndexWriter详解、Document详解、索引更新)
一.IndexWriter详解 问题1:索引创建过程完成什么事? 分词.存储到反向索引中 1. 回顾Lucene架构图: 介绍我们编写的应用程序要完成数据的收集,再将数据以document的形式用lu ...
随机推荐
- python之socketserver实现并发
python之socketserver实现并发 服务端 import socketserver #socketserver模块是用来实现并发 # 我们自己的类里一定要继承socketserver.Ba ...
- 提高在word编辑公式的效率,及快捷键、对齐、编号问题
1. Word中编辑公式简介(重点看) https://jacobz.top/2017-08/WordMath/ 2. 快捷键 https://wenku.baidu.com/view ...
- BZOJ.4212.神牛的养成计划(Trie 可持久化Trie)
BZOJ 为啥hzw的题也是权限题啊 考虑能够匹配\(s1\)这一前缀的串有哪些性质.对所有串排序,能发现可以匹配\(s1\)的是一段区间,可以建一棵\(Trie\)求出来,设为\([l,r]\). ...
- 我的 FPGA 学习历程(12)—— 电子钟项目准备
初学 FPGA 的时候,我们总是存在很多疑问,比如:xilinx 和 altera 的 FPGA 那种比较好.verilog 语言被如何综合成具体硬件电路.RTL 级电路是什么意思等等.现在我们就不会 ...
- CentOS7 VMware-Tools安装与共享文件夹设置
一. VMware-Tools安装 1.加载VMware Tools的光驱:点击"虚拟机"->"安装VMware Tools".这里,由于我已经安装了,所 ...
- c# asp.net mvc使用斑马GK888t打印机打印标签
前言 c#语言,asp.net mvc,南京都昌电子病历模板工具(类似word),斑马GK888t,打印手腕带和标签纸. 实现步骤为:在页面上显示一个或多个都昌模板工具,点击页面上的button,出现 ...
- FCC学习笔记(一)
除了像素,你还可以使用百分比来指定border-radius边框半径的值. 给你的猫咪图片一个50%的border-radius. a元素,也叫anchor(锚点)元素,既可以用来链接到外部地址实现页 ...
- login shell 和 non-login shell 的区别
login shell:去的bash时需要完整的登录流程.就是说通过输入账号和密码登录系统,此时取得的shell称为login shell non-login shell:取得sb ...
- CMD 中常见命令
引自百度经验:https://jingyan.baidu.com/article/67508eb41d44a09cca1ce4f1.html ipConfig:查询ip ping:查询连接速度: pi ...
- 批量引用iconfont字体图标到项目
打开https://www.iconfont.cn/网址登录后选择你需要的图标添加到购物车中 点击下载代码或者添加到项目后再下载代码,再找到之前下载的的文件,拷贝到项目中