Spark SQL大数据处理并写入Elasticsearch
SparkSQL(Spark用于处理结构化数据的模块)
通过SparkSQL导入的数据可以来自MySQL数据库、Json数据、Csv数据等,通过load这些数据可以对其做一系列计算
下面通过程序代码来详细查看SparkSQL导入数据并写入到ES中:
数据集:北京市PM2.5数据
Spark版本:2.3.2
Python版本:3.5.2
mysql-connector-java-8.0.11 下载
ElasticSearch:6.4.1
Kibana:6.4.1
elasticsearch-spark-20_2.11-6.4.1.jar 下载
具体代码:
# coding: utf-8
import sys
import os pre_current_dir = os.path.dirname(os.getcwd())
sys.path.append(pre_current_dir)
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import udf
from settings import ES_CONF current_dir = os.path.dirname(os.path.realpath(__file__)) spark = SparkSession.builder.appName("weather_result").getOrCreate() def get_health_level(value):
"""
PM2.5对应健康级别
:param value:
:return:
"""
if 0 <= value <= 50:
return "Very Good"
elif 50 < value <= 100:
return "Good"
elif 100 < value <= 150:
return "Unhealthy for Sensi"
elif value <= 200:
return "Unhealthy"
elif 200 < value <= 300:
return "Very Unhealthy"
elif 300 < value <= 500:
return "Hazardous"
elif value > 500:
return "Extreme danger"
else:
return None def get_weather_result():
"""
获取Spark SQL分析后的数据
:return:
"""
# load所需字段的数据到DF
df_2017 = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("file://{}/data/Beijing2017_PM25.csv".format(current_dir)) \
.select("Year", "Month", "Day", "Hour", "Value", "QC Name") # 查看Schema
df_2017.printSchema() # 通过udf将字符型health_level转换为column
level_function_udf = udf(get_health_level, StringType()) # 新建列healthy_level 并healthy_level分组
group_2017 = df_2017.withColumn(
"healthy_level", level_function_udf(df_2017['Value'])
).groupBy("healthy_level").count() # 新建列days和percentage 并计算它们对应的值
result_2017 = group_2017.select("healthy_level", "count") \
.withColumn("days", group_2017['count'] / 24) \
.withColumn("percentage", group_2017['count'] / df_2017.count())
result_2017.show() return result_2017 def write_result_es():
"""
将SparkSQL计算结果写入到ES
:return:
"""
result_2017 = get_weather_result()
# ES_CONF配置 ES的node和index
result_2017.write.format("org.elasticsearch.spark.sql") \
.option("es.nodes", "{}".format(ES_CONF['ELASTIC_HOST'])) \
.mode("overwrite") \
.save("{}/pm_value".format(ES_CONF['WEATHER_INDEX_NAME'])) write_result_es()
spark.stop()
将mysql-connector-java-8.0.11和elasticsearch-spark-20_2.11-6.4.1.jar放到Spark的jars目录下,提交spark任务即可。
注意:
(1) 如果提示:ClassNotFoundException Failed to find data source: org.elasticsearch.spark.sql.,则表示spark没有发现jar包,此时需重新编译pyspark:
cd /opt/spark-2.3.2-bin-hadoop2.7/python
python3 setup.py sdist
pip install dist/*.tar.gz
(2) 如果提示:Multiple ES-Hadoop versions detected in the classpath; please use only one ,
则表示ES-Hadoop jar包有多余的,可能既有elasticsearch-hadoop,又有elasticsearch-spark,此时删除多余的jar包,重新编译pyspark 即可
执行效果:
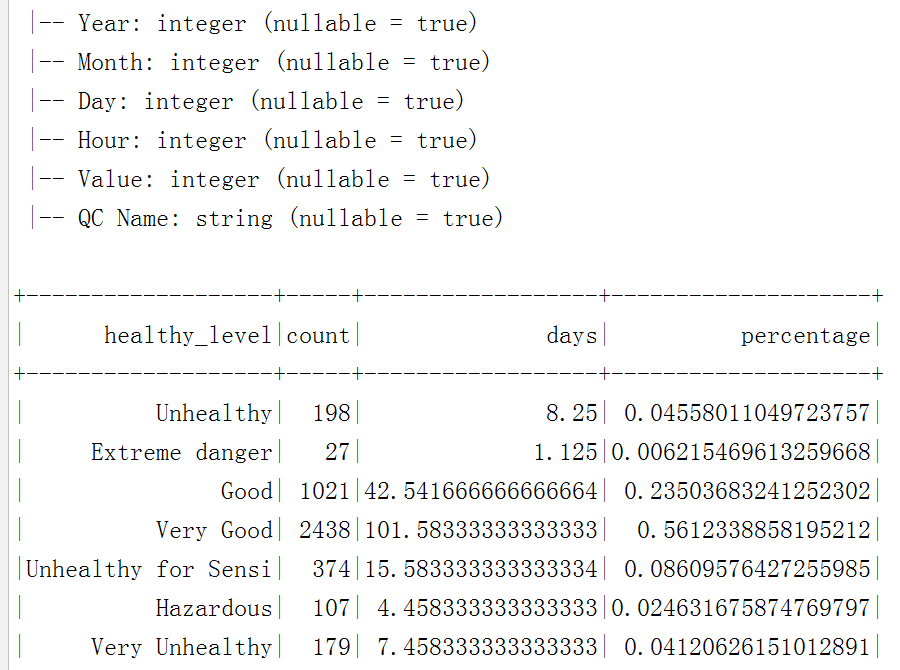
更多源码请关注我的github, https://github.com/a342058040/Spark-for-Python ,Spark相关技术全程用python实现,持续更新
Spark SQL大数据处理并写入Elasticsearch的更多相关文章
- Spark SQL JSON数据处理
背景 这一篇可以说是“Hive JSON数据处理的一点探索”的兄弟篇. 平台为了加速即席查询的分析效率,在我们的Hadoop集群上安装部署了Spark Server,并且与我们的Hive数据仓 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- Spark官方1 ---------Spark SQL和DataFrame指南(1.5.0)
概述 Spark SQL是用于结构化数据处理的Spark模块.它提供了一个称为DataFrames的编程抽象,也可以作为分布式SQL查询引擎. Spark SQL也可用于从现有的Hive安装中读取数据 ...
- [转] Spark sql 内置配置(V2.2)
[From] https://blog.csdn.net/u010990043/article/details/82842995 最近整理了一下spark SQL内置配.加粗配置项是对sparkSQL ...
- 第五章 大数据平台与技术 第12讲 大数据处理平台Spark
Spark支持多种的编程语言 对比scala和Java编程上节课的计数程序.相比之下,scala简洁明了. Hadoop的IO开销大导致了延迟高,也就是说任务和任务之间涉及到I/O操作.前一个任务完成 ...
- 流式大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.本文将对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的 ...
- [转载]流式大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.本文将对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的 ...
- 《Spark大数据处理:技术、应用与性能优化 》
基本信息 作者: 高彦杰 丛书名:大数据技术丛书 出版社:机械工业出版社 ISBN:9787111483861 上架时间:2014-11-5 出版日期:2014 年11月 开本:16开 页码:255 ...
- Spark大数据处理技术
全球首部全面介绍Spark及Spark生态圈相关技术的技术书籍 俯览未来大局,不失精细剖析,呈现一个现代大数据框架的架构原理和实现细节 透彻讲解Spark原理和架构,以及部署模式.调度框架.存储管理及 ...
随机推荐
- Java【第一篇】基本语法之--关键字、标识符、变量
关键字 定义:被Java语言赋予了特殊含义,用做专门用途的字符串(单词)特点:关键字中所有字母都为小写 标识符 Java 对各种变量.方法和类等要素命名时使用的字符序列称为标识符凡是自己可以起名字的地 ...
- 用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建三:配置spring并测试
这一部分的主要目的是 配置spring-service.xml 也就是配置spring 并测试service层 是否配置成功 用IntelliJ IDEA 开发Spring+SpringMVC+M ...
- 20175221 2018-2019-2 《Java程序设计》第二周学习总结
20175221 <Java程序设计>第2周学习总结 教材学习内容总结 教材方面 本周学习了第二章的“基本数据类型与数组”的内容,以及粗略地看了一下第三章“运算符.表达式和语句”的内容 ...
- 《数据库MySQL》
<数据库MySQL> 一.题目要求 下载附件中的world.sql.zip, 参考http://www.cnblogs.com/rocedu/p/6371315.html#SECDB,导入 ...
- 【SVN】svn 查看项目的 svn 服务器地址目录(脱机状态下)
#事故现场: 在无法连接到svn服务器地址的情况下,查看本地项目的svn的服务器地址目录: #事故分析 因为无法连接svn服务器,所以只能通过svn在本地存储的信息来获取svn的地址路径信息: #解决 ...
- saltstack主机管理项目:动态调用插件解析-模块解析(五)
一.动态调用插件解析 1.目录结构 1.base_module代码解析: def syntax_parser(self,section_name,mod_name,mod_data): print(& ...
- NET Core 控制台程序读 appsettings.json 、注依赖、配日志、设 IOptions
.NET Core 控制台程序没有 ASP.NET Core 的 IWebHostBuilder 与 Startup.cs ,那要读 appsettings.json.注依赖.配日志.设 IOptio ...
- mysql普通用户本机无法登录的解决办法
背景 mysql和mariadb的用户表里存在匿名用户时,普通用户出现无法登录的情况 分析 先查看下用户表 mysql> select user, host, password from mys ...
- 【OpenGL】搭建opgl环境
*GLFW+GLEW环境. 工具: GLFW库(下载) GLEW库 cMake软件(下载) 用cMake编译GLFW和GLEW成vs工程文件包,运行得到编译后文件. 在编译后文件夹中找到各个必需文件, ...
- 循环语句(for,while,do……while),方法概述
循环结构 分类:for,while,do……while (1)for语句 格式: for(初始化表达式:条件表达式:循环后的操作表达式){ 循环体: } 执行流程: a.执行初始化语句 b.执行判断条 ...