流式大数据处理的三种框架:Storm,Spark和Samza
Apache Storm

Apache Spark

Apache Samza
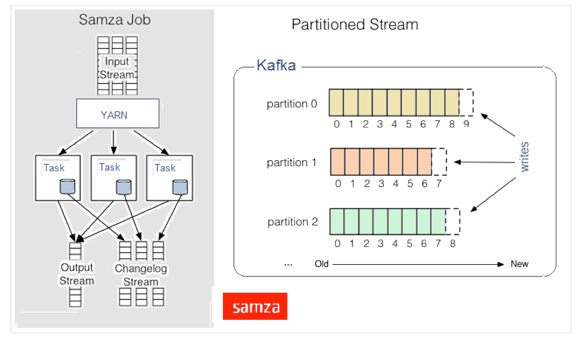
共同之处

对比图
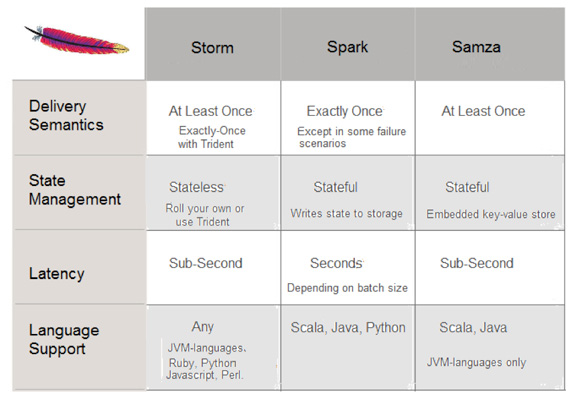
- 最多一次(At-most-once):消息可能会丢失,这通常是最不理想的结果。
- 最少一次(At-least-once):消息可能会再次发送(没有丢失的情况,但是会产生冗余)。在许多用例中已经足够。
- 恰好一次(Exactly-once):每条消息都被发送过一次且仅仅一次(没有丢失,没有冗余)。这是最佳情况,尽管很难保证在所有用例中都实现。
用例

使用Storm的公司有:Twitter,雅虎,Spotify还有The Weather Channel等。
使用Spark的公司有:亚马逊,雅虎,NASA JPL,eBay还有百度等。
使用Samza的公司有:LinkedIn,Intuit,Metamarkets,Quantiply,Fortscale等。
结论
流式大数据处理的三种框架:Storm,Spark和Samza的更多相关文章
- [转载]流式大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.本文将对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的 ...
- 大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.下面对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的图 ...
- 翻译-In-Stream Big Data Processing 流式大数据处理
相当长一段时间以来,大数据社区已经普遍认识到了批量数据处理的不足.很多应用都对实时查询和流式处理产生了迫切需求.最近几年,在这个理念的推动下,催生出了一系列解决方案,Twitter Storm,Yah ...
- storm流式大数据处理流行吗
在如今这个信息高速增长的今天,信息实时计算处理能力已经是一项专业技能了,正是因为有了这些需求的存在才使得分布式,同时具备高容错的实时计算系统Storm才变得如此受欢迎,为什么这么说呢?下面看看新霸哥的 ...
- flink 流式处理中如何集成mybatis框架
flink 中自身虽然实现了大量的connectors,如下图所示,也实现了jdbc的connector,可以通过jdbc 去操作数据库,但是flink-jdbc包中对数据库的操作是以ROW来操作并且 ...
- 流式大数据计算实践(1)----Hadoop单机模式
一.前言 1.从今天开始进行流式大数据计算的实践之路,需要完成一个车辆实时热力图 2.技术选型:HBase作为数据仓库,Storm作为流式计算框架,ECharts作为热力图的展示 3.计划使用两台虚拟 ...
- 国内常用的三种框架:ionic/mui/framework7对比
国内常用的三种框架:ionic/mui/framework7对比 原文连接:http://zhihu.com/question/19558750/answer/91179040
- Struts中的数据处理的三种方式
Struts中的数据处理的三种方式: public class DataAction extends ActionSupport{ @Override public String execute() ...
- 流式大数据计算实践(6)----Storm简介&使用&安装
一.前言 1.这一文开始进入Storm流式计算框架的学习 二.Storm简介 1.Storm与Hadoop的区别就是,Hadoop是一个离线执行的作业,执行完毕就结束了,而Storm是可以源源不断的接 ...
随机推荐
- Android 毛玻璃效果
muzei live wallpaper https://github.com/romannurik/muzei
- lsof
lsof `which httpd` //那个进程在使用apache的可执行文件 lsof /etc/passwd //那个进程在占用/etc/passwd lsof /dev/hda6 //那个进程 ...
- mysql编码设置
一:mysql字符集 mysql的字符集支持(Character Set Support)有两个类型:字符集(Character set)和连接校对(Collation).对于字符集的支持细化到四个层 ...
- mysql的事务处理
事务用于保证数据的一致性,它由一组相关的DML语句组成,该组的DML语句要么全部成功,要么全部失败. 示例: 银行账单 $mysqli=new mysqli("localhost" ...
- Android中Thread和Service的区别zz
1). Thread:Thread 是程序执行的最小单元,它是分配CPU的基本单位.可以用 Thread 来执行一些异步的操作. 2). Service:Service 是android的一种机制,当 ...
- python多进程程序之间交换数据的两种办法--Queue和Pipe
合在一起作的测试. #!/usr/bin/env python # -*- coding: utf-8 -*- import multiprocessing import random import ...
- POJ2762 Going from u to v or from v to u(单连通 缩点)
判断图是否单连通,先用强连通分图处理,再拓扑排序,需注意: 符合要求的不一定是链拓扑排序列结果唯一,即在队列中的元素始终只有一个 #include<cstdio> #include< ...
- hdu 2891 中国剩余定理
从6点看到10点,硬是没算出来,早知道玩游戏去了,艹,明天继续看 不爽,起来再看,终于算是弄懂了,以后超过一个小时的题不会再看了,不是题目看不懂,是水平不够 #include<cstdio> ...
- PMP 第六章 项目时间管理
定义活动 排列活动顺序 估算活动资源 估算活动持续时间 制定进度计划 控制进度计划 1.进度管理计划和进度计划的内容分别是什么,有什么区别? 进度计划:项目各活动计划完成日期的编排. 进度管理计 ...
- ubuntu下整合eclipse和javah生成jni头文件开发android的native程序(转)
本文介绍两种利用javah命令生成jni头文件的方法,第一种为大众所知的javah命令,第二种为整合javah到eclipse里面.推荐第二种方式,方便快捷,随时修改随时生成 0:前提和条件: 1:u ...