Lucene 分词
在Lucene中很多数据是通过Attribute进行存储的
步骤是同过TokenStrem获取文本信息流
TokenStream stream = a.tokenStream("content", new StringReader(str)); (a:指的是Analyzer)
而在这里对这个由不同的分词的话之需要实现Analyer,并重写里面的tokenStream 方法
public TokenStream tokenStream(String fieldName, Reader reader) {
Dictionary dic = Dictionary.getInstance("F:\\CheckOut\\Lucene\\03_lucene_analyzer\\mmseg4j-1.8.4\\data");
return new MySameTokenFilter(new MMSegTokenizer(new MaxWordSeg(dic), reader),samewordContext);
}
然后这里获取他的Tokenizer 并可以实现自己的过滤器,以及相应的同义词删减
public class MySameTokenFilter extends TokenFilter{
private CharTermAttribute cta = null;
private PositionIncrementAttribute pia = null;
private AttributeSource.State current = null;
private Stack<String> sames = null;
private SamewordContext samewordContext;
protected MySameTokenFilter(TokenStream input,SamewordContext samewordContext) {
super(input);
cta = this.addAttribute(CharTermAttribute.class);
pia = this.addAttribute(PositionIncrementAttribute.class);
sames = new Stack<String>();
this.samewordContext=samewordContext;
}
/**
* 思想如下:
* 其实每个同义词都要放在CharTermAttribute里面,但是如果直接cta.append("大陆");的话
* 那会直接把原来的词和同义词连接在同一个语汇单元里面[中国大陆],这样是不行的
* 要的是这样的效果[中国][大陆]
* 那么就要在遇到同义词的时候把当前的状态保存一份,并把同义词的数组放入栈中,
* 这样在下一个语汇单元的时候判断同义词数组是否为空,不为空的话把之前的保存的一份状态
* 还原,然后在修改之前状态的值cta.setEmpty(),然后在把同义词的值加入cta.append("大陆")
* 再把位置增量设为0,pia.setPositionIncrement(0),这样的话就表示是同义词,
* 接着把该同义词的语汇单元返回
*/
@Override
public boolean incrementToken() throws IOException {
System.out.println("yaobo");
while(sames.size() > ){
//将元素出栈,并获取这个同义词
String str = sames.pop();
//还原状态
restoreState(current);
cta.setEmpty();
cta.append(str);
//设置位置
pia.setPositionIncrement();
return true;
}
if(!input.incrementToken()) return false;
if(addSames(cta.toString())){
//如果有同义词将当前状态先保存
current = captureState();
}
return true;
}
/*
* 使用这种方式是不行的,这种会把的结果是[中国]替换成了[大陆]
* 而不是变成了[中国][大陆]
@Override
public boolean incrementToken() throws IOException {
if(!input.incrementToken()) return false;
if(cta.toString().equals("中国")){
cta.setEmpty();
cta.append("大陆");
}
return true;
}
*/
private boolean addSames(String name){
String[] sws = samewordContext.getSamewords(name);
if(sws != null){
for(String s : sws){
sames.push(s);
}
return true;
}
return false;
}
}
其思想如下

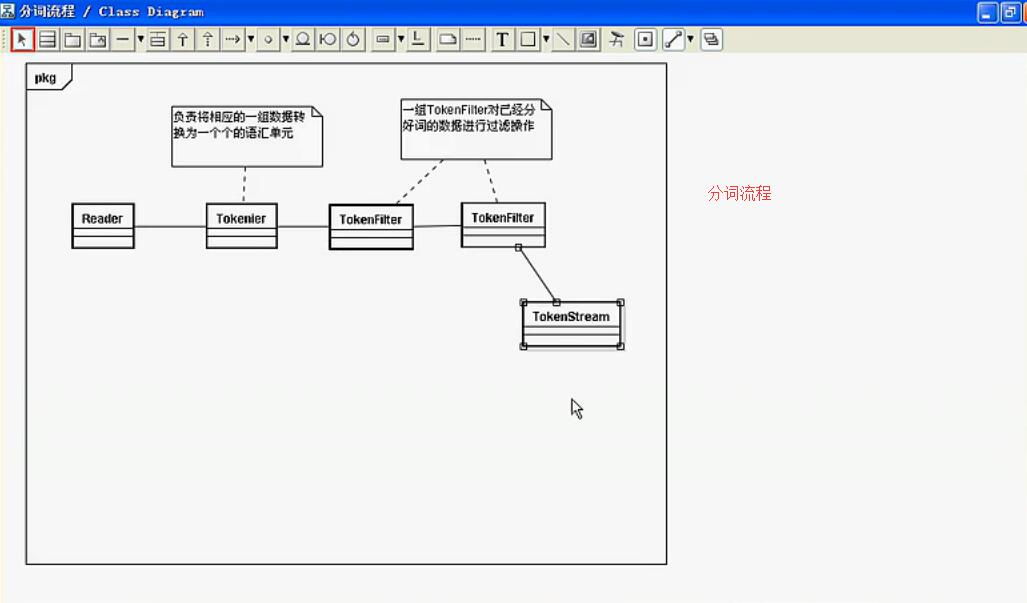
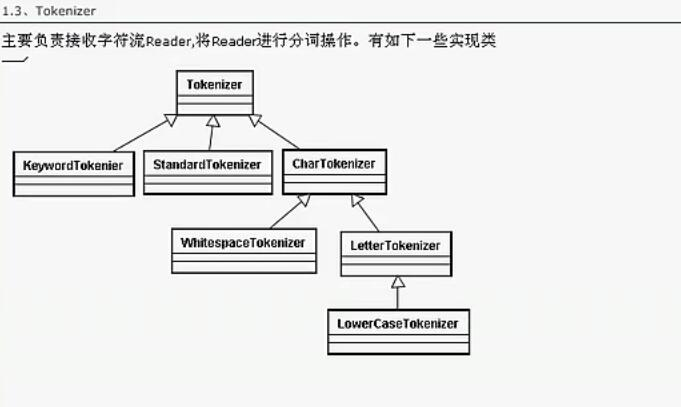

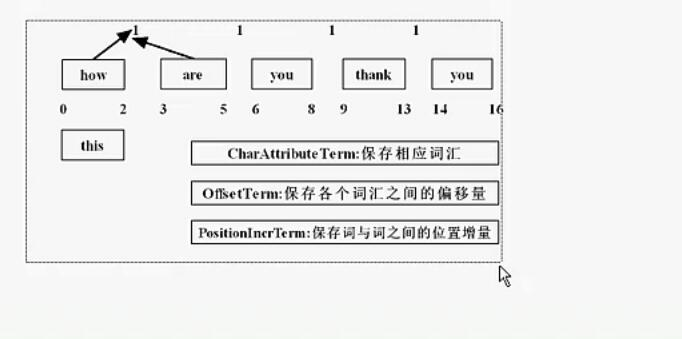
然后通过不同的Attribute进行分割
TokenStream stream = a.tokenStream("content", new StringReader(str));
//位置增量
PositionIncrementAttribute pia = stream.addAttribute(PositionIncrementAttribute.class);
//偏移量
OffsetAttribute oa = stream.addAttribute(OffsetAttribute.class);
//词元
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class);
//分词的类型
TypeAttribute ta = stream.addAttribute(TypeAttribute.class);
Lucene 分词的更多相关文章
- Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息
Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息 在此回复牛妞的关于程序中分词器的问题,其实可以直接很简单的在词库中配置就好了,Lucene中分词的所有信息我们都可以从 ...
- Hibernate Search集与lucene分词查询
lucene分词查询参考信息:https://blog.csdn.net/dm_vincent/article/details/40707857
- Lucene系列三:Lucene分词器详解、实现自己的一个分词器
一.Lucene分词器详解 1. Lucene-分词器API (1)org.apache.lucene.analysi.Analyzer 分析器,分词器组件的核心API,它的职责:构建真正对文本进行分 ...
- WebGIS中兴趣点简单查询、基于Lucene分词查询的设计和实现
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.前言 兴趣点查询是指:输入框中输入地名.人名等查询信息后,地图上可 ...
- lucene 分词实现
一.概念认识 1.常用的Analyer SimpleAnalyzer.StopAnalyzer.WhitespaceAnalyzer.StandardAnalyzer 2.TokenStream 分词 ...
- lucene分词器与搜索
一.分词器 lucene针对不同的语言和虚伪提供了许多分词器,我们可以针对应用的不同的需求使用不同的分词器进行分词.我们需要注意的是在创建索引时使用的分词器与搜索时使用的分词器要保持一致.否则搜索的结 ...
- 全文索引(三)lucene 分词 Analyzer
分词: 将reader通过阅读对象Analyzer字处理,得到TokenStream处理流程被称为分割. 该解释可能是太晦涩.查看示例,这个东西是什么感性的认识. 样品:一段文本"this ...
- lucene分词多种方法
目前最新版本的lucene自身提供的StandardAnalyzer已经具备中文分词的功能,但是不一定能够满足大多数应用的需要.另外网友谈的比较多的中文分词器还有:CJKAnalyzerChinese ...
- Lucene分词详解
分词和查询都是以词项为基本单位,词项是词条化的结果.在Lucene中分词主要依靠Analyzer类解析实现.Analyzer类是一个抽象类,分词的具体规则是由子类实现的,所以对于不同的语言规则,要有不 ...
- 学习笔记(三)--Lucene分词器详解
Lucene-分词器API org.apache.lucene.analysi.Analyzer 分析器,分词器组件的核心API,它的职责:构建真正对文本进行分词处理的TokenStream(分词处理 ...
随机推荐
- 技巧-如何通过hive开发平台上传csv文件
通过数据交换平台上传较大的文件时,经常会出现导入失败情况,换种方式通过新数据开发平台(stark)也可以轻松实现外部数据与hive的数据关联. --第一步.导入csv文件到hive --stark数据 ...
- 【Sklearn系列】KNN算法
最近邻分类 概念讲解 我们使用的是scikit-learn 库中的neighbors.KNeighborsClassifier 来实行KNN. from sklearn import neighbor ...
- django的Cookie-9
设置Cookie 可以通过HttpResponse对象中的set_cookie方法来设置cookie. HttpResponse.set_cookie(cookie名字, value=cookie值, ...
- Python编程小坑
在Pycharm中编辑文本文件,如果使用\r\n会产生两个空行? exit("xxx),会导致Process finished with exit code 1,所以如果要输入信息然后退出, ...
- Vue2.5入门-3
安装和使用 全局安装vue npm install --global vue-cli 创建基于webpack模板的新项目 vue init webpack my-project 安装依赖 cd my- ...
- python的subprocess基本
先在同一个文件夹下创建两个.py文件. 第一个:13.py # -*- coding: utf-8 -*- __author__ = "YuDian" ''' multiproce ...
- 'express'不是内部或外部命令, 也不是可运行的程序, 或批处理文件
1. npm install -g express-generator 安装新的express框架2. express -h 错误提示: 'express'不是内部或外部命令, 也不是可运行的程序, ...
- NodeJS设置Header解决跨域问题
转载: NodeJS设置Header解决跨域问题 app.all('*', function (req, res, next) { res.header('Access-Control-Allow-O ...
- 20155213 2016-2017-2《Java程序设计》第三周学习总结
20155213 2016-2017-2<Java程序设计>第三周学习总结 教材学习内容总结 类与对象 类和对象的关系:类决定对象,对象反映类的性质 定义值域成员:在新建的类中定义变量,可 ...
- 20155217 2016-2017-2 《Java程序设计》第10周学习总结
20155217 2016-2017-2 <Java程序设计>第10周学习总结 教材学习内容总结 网络编程 网络编程就是在两个或两个以上的设备(例如计算机)之间传输数据. 程序员所作的事情 ...