[转载]WebDriver工作原理
转载自:https://www.cnblogs.com/testermark/p/3546287.html
WebDriver的工作原理:
WebDriver Wire协议是通用的,也就是说不管是FirefoxDriver还是ChromeDriver,启动之后都会在某一个端口启动基于这套协议的Web Service。例如FirefoxDriver初始化成功之后,默认会从http://localhost:7055开始,而ChromeDriver 则大概是http://localhost:46350之类的。接下来,我们调用WebDriver的任何API,都需要借助一个 ComandExecutor发送一个命令,实际上是一个HTTP request给监听端口上的Web Service。在我们的HTTP request的body中,会以WebDriver Wire协议规定的JSON格式的字符串来告诉Selenium我们希望浏览器接下来做什么事情。
1). WebDriver 启动目标浏览器,并绑定到指定端口。该启动的浏览器实例,做为web driver的remote server。
2). Client 端通过CommandExcuter 发送HTTPRequest 给remote server 的侦听端口(通信协议: the webriver wire protocol)
3). Remote server 需要依赖原生的浏览器组件(如:IEDriver.dll,chromedriver.exe),来转化转化浏览器的native调用。
那么remote server端的这些功能是如何实现的呢?答案是浏览器实现了webdriver的统一接口,这样client就可以通过统一的restful的接口去进行浏览器的自动化操作。目前webdriver支持ie, chrome, firefox, opera等主流浏览器,其主要原因是这些浏览器实现了webdriver约定的各种接口。
可以更通俗的理解:由于客户端脚本(java, python, ruby)不能直接与浏览器通信,这时候可以把WebService当做一个翻译器,它可以把客户端代码翻译成浏览器可以识别的代码(比如js).客户端 (也就是测试脚本)创建1个session,在该session中通过http请求向WebService发送restful的请 求,WebService翻译成浏览器懂得脚本传给浏览器,浏览器把执行的结果返回给WebService,WebService把返回的结果做了一些封 装(一般都是json格式),然后返回给client,根据返回值就能判断对浏览器的操作是不是执行成功
摘自官网对于chrome driver的描述:
The ChromeDriver consists of three separate pieces. There is the browser itself ("chrome"), the language bindings provided by the Selenium project ("the driver") and an executable downloaded from the Chromium project which acts as a bridge between "chrome" and the "driver". This executable is called "chromedriver", but we'll try and refer to it as the "server" in this page to reduce confusion.
大概意思就是我们下载的chrome可执行文件(.exe)是为作为浏览器与client(language binding)桥梁的作用,也更印证了对于Web Service(driver)的理解。
举个实际的例子:
下图表示了各种WebDriver的工作原理
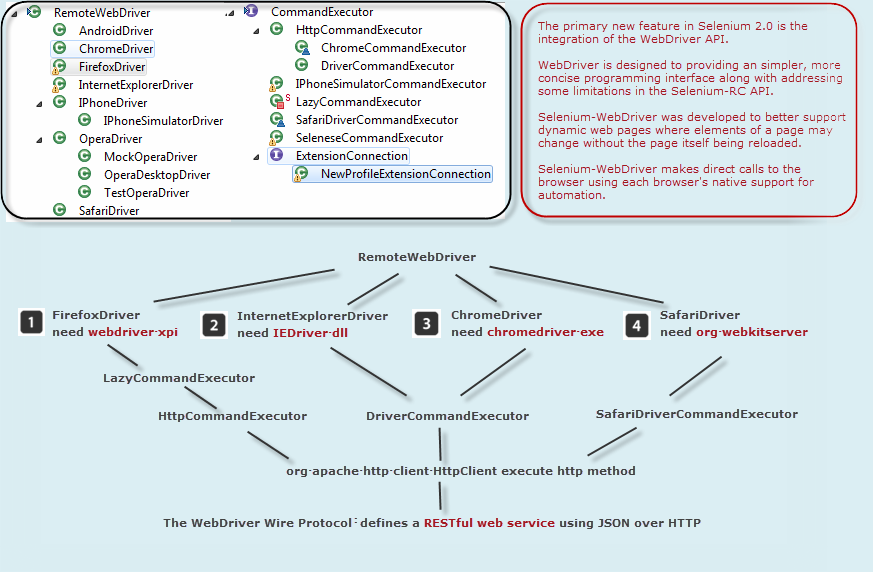
从上图中我们可以看出,不同浏览器的WebDriver子类,都需要依赖特定的浏览器原生组件,例如运行Firefox就需要一个 add-on名字叫webdriver.xpi。而IE的话就需要用到一个dll文件来转化Web Service的命令为浏览器native的调用。另外,图中还标明了WebDriver Wire协议是一套基于RESTful的web service
关于WebDriver Wire协议的细节,比如希望了解这套Web Service能够做哪些事情,可以阅读Selenium官方的协议文档, 在Selenium的源码中,我们可以找到一个HttpCommandExecutor这个类,里面维护了一个Map<String, CommandInfo>,它负责将一个个代表命令的简单字符串key,转化为相应的URL,因为REST的理念是将所有的操作视作一个个状态,每 一个状态对应一个URI。所以当我们以特定的URL发送HTTP request给这个RESTful web service之后,它就能解析出需要执行的操作。截取一段源码如下:

1 .put(NEW_SESSION, post("/session"))
2 .put(QUIT, delete("/session/:sessionId"))
3 .put(GET_CURRENT_WINDOW_HANDLE, get("/session/:sessionId/window_handle"))
4 .put(GET_WINDOW_HANDLES, get("/session/:sessionId/window_handles"))
5 .put(GET, post("/session/:sessionId/url"))
6
7 // The Alert API is still experimental and should not be used.
8 .put(GET_ALERT, get("/session/:sessionId/alert"))
9 .put(DISMISS_ALERT, post("/session/:sessionId/dismiss_alert"))
10 .put(ACCEPT_ALERT, post("/session/:sessionId/accept_alert"))
11 .put(GET_ALERT_TEXT, get("/session/:sessionId/alert_text"))
12 .put(SET_ALERT_VALUE, post("/session/:sessionId/alert_text"))
可以看到实际发送的URL都是相对路径,后缀多以/session/:sessionId开头,这也意味着WebDriver每次启动 浏览器都会分配一个独立的sessionId,多线程并行的时候彼此之间不会有冲突和干扰。例如我们最常用的一个WebDriver的 API,getWebElement在这里就会转化为/session/:sessionId/element这个URL,然后在发出的HTTP request body内再附上具体的参数比如by ID还是CSS还是Xpath,各自的值又是什么。收到并执行了这个操作之后,也会回复一个HTTP response。内容也是JSON,会返回找到的WebElement的各种细节,比如text、CSS selector、tag name、class name等等。以下是解析我们说的HTTP response的代码片段:
1 try {
2 response = new JsonToBeanConverter().convert(Response.class, responseAsText);
3 } catch (ClassCastException e) {
4 if (responseAsText != null && "".equals(responseAsText)) {
5 // The remote server has died, but has already set some headers.
6 // Normally this occurs when the final window of the firefox driver
7 // is closed on OS X. Return null, as the return value _should_ be
8 // being ignored. This is not an elegant solution.
9 return null;
10 }
11 throw new WebDriverException("Cannot convert text to response: " + responseAsText, e);
12 } //...
PS:如果想更深入的了解WebDriver的架构,可以参考该文章http://www.aosabook.org/en/selenium.html。
[转载]WebDriver工作原理的更多相关文章
- [转载] zookeeper工作原理、安装配置、工具命令简介
转载自http://www.cnblogs.com/kunpengit/p/4045334.html 1 Zookeeper简介Zookeeper 是分布式服务框架,主要是用来解决分布式应用中经常遇到 ...
- [转载] MapReduce工作原理讲解
转载自http://www.aboutyun.com/thread-6723-1-1.html 有时候我们在用,但是却不知道为什么.就像苹果砸到我们头上,这或许已经是很自然的事情了,但是牛顿却发现了地 ...
- WebDriver工作原理
http://www.cnblogs.com/timsheng/archive/2012/06/12/2546957.html 通过研究selenium-webdriver的源码,笔者发现其实webd ...
- Selenium WebDriver 工作原理
WebDriver与之前Selenium的js注入实现不同:Selenium通过JS来定位元素处理元素(基本上所有元素都可以定位到)WebDriver通过WebDriver API定位处理元素:通过浏 ...
- [转载]Appium工作原理
[Appium]Appium工作原理 2017-09-13 15:28 sophia194910 阅读(7658) 评论(0) 编辑 收藏 参考:http://www.cnblogs.com/zhjs ...
- 转载: keepalived工作原理和配置说明
转自:http://outofmemory.cn/wiki/keepalived-configuration keepalived是什么 keepalived是集群管理中保证集群高可用的一个服务软件, ...
- (转载)HashMap工作原理
HashMap是近些年来java面试中常问到的知识点,很多人(包括我在内)都知道HashMap的用法,也知道HashMap与HashTable之间的区别,但是却不知其所以然,于是乎,本人开始查阅相关资 ...
- [转载] Lucene 工作原理
转载自http://www.cnblogs.com/dewin/archive/2009/11/24/1609905.html Lucene是一个高性能的java全文检索工具包,它使用的是倒排文件索引 ...
- WebDriver 工作原理
WebDriver是W3C的一个标准,由Selenium主持. 具体的协议标准可以从http://code.google.com/p/selenium/wiki/JsonWireProtocol#Co ...
随机推荐
- PHP-redis英文文档
作为程序员,看英文文档是必备技能,所以尽量还是多看英文版的^^ PhpRedis The phpredis extension provides an API for communicating wi ...
- Dubbo(二) 一次惨痛的流血事故
时间定位到2018年11月某某一天,我正在看看Spring源码的文档,趁着没啥事,忽然想起Dubbo是基于Schema扩展的,所以就翻了下Dubbo的源码. 然后的然后,有活要干了,写完代码后,启动工 ...
- Hibernate 注解(Annotations 四)多对多双向注解
注解(Annotation),也叫元数据.一种代码级别的说明.它是JDK1.5及以后版本引入的一个特性,与类.接口.枚举是在同一个层次.它可以声明在包.类.字段.方法.局部变量.方法参数等的前面,用来 ...
- js中contains()方法的了解
今天第一次碰到了contains()方法,处于好奇了解了一下:发现在某些场合还是挺有用的. contains(),js原生方法,用于判断DOM元素的包含关系: 需要注意的是:它以HTMLElement ...
- csharp: SQL Server 2005 Database Backup and Restore using C#
1.第一种方式: using SQLDMO;//Microsoft SQLDMO Object Library 8.0 /// <summary> /// 数据库的备份 /// 涂聚文注: ...
- ECharts 柱状图顶部显示百分比
1.引入jquery.js和echarts.js <script src="../jquery-1.8.3.min.js" type="text/javascrip ...
- 路飞学城知识点3缓存知识点之一Djang自带的缓存
缓存是暂时把数据放到哪儿的意思,用于提高查询的访问速度用的,mysql等关系型数据库通常用作备份,数据库进行增删改操作一段时间内存同步到缓存(非关系型数据库中) 缓存与内存的区别: 通常把数据放到内存 ...
- mysql中int、bigint、smallint 和 tinyint的区别与长度的含义【转】
最近使用mysql数据库的时候遇到了多种数字的类型,主要有int,bigint,smallint和tinyint.其中比较迷惑的是int和smallint的差别.今天就在网上仔细找了找,找到如下内容, ...
- 打通版微社区(4):微信第三方服务部署——JSP的IIS部署
写在前面: 本机环境2008R2.tomcat8 网上搜了很多JSP的IIS部署,内容大部分是相近的,这些文章最早出现在2012的样子.大概的原理就是通过ISAPI方式对IIS进行扩展(这个扩展是to ...
- Linux入门-3 Linux磁盘及文件系统管理
1. 磁盘基本概念 1.1 磁盘结构:盘片(单碟vs多碟).磁头(读写数据) 1.2 磁盘在Linux中的表示 1.3 分区概念 2 使用fdisk进行磁盘管理 3 Linux文件系统 mke2fs ...