Re-Order Buffer
Re-order Buffer(ROB)是处理器中非常重要的一个模块,它位于renamer与scheduler(RS)之间,并且也是execution unit(EU)的出口。ROB作为指令处理的后端,其主要任务是存储指令经由EU处理后得到的结果,并把该结果按照in-order顺序写回到寄存器文件。
Intel没有给出详细的ROB pipeline,下面的pipeline的描述以及分析主要基于参考资料以及本人的一些推断,不一定准确,仅供参考。
Early ROB
ROB的目的为存储out-of-order的处理结果,并以in-order写回寄存器。不过早期的ROB与现在的ROB相比,虽然目的相同,但是实现却存在较大的区别,并且这部分的区别不仅仅在于ROB本身,还牵扯到out-of-order engine的其它部分。
早期的ROB的实现方式一直延续到Nehalem微处理器,从Sandy Bridge微处理器开始采用新的ROB实现方式。
早期ROB的相关部分的pipeline:
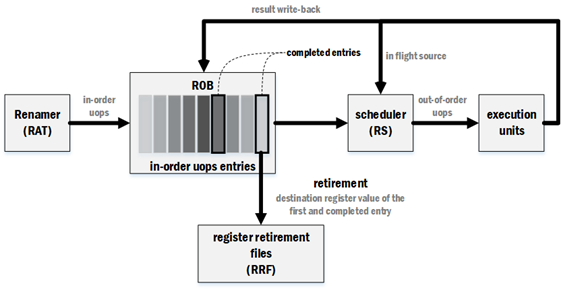
μops流经上述pipeline的过程分为以下几个步骤:
- μops以in-order顺序从renamer传输到RS,途中会经过ROB。
- 每个经过ROB的μop都会占用ROB中的一个项,主要都用于存储μop处理完成时得到的result,并且这些项会以μops经过的先后顺序(in-order)进行排列。
- 经过ROB后,μops会在RS内等待source operand就绪,一旦某μop所有的source都已就绪并且相应的EU可用的时,往EU发送μop。
- EU在处理完成μop后,会把处理的结果写回ROB中相应的那项。
- 同时,如果RS中有其他的μop需要该处理结果作为source,该结果可以直接从EU传输到RS。由于这种数据转移方式不经过front end以及back end(ROB),因此被称为in flight。
- 在ROB中,处理完成的μop需要按照in-order的顺序把执行结果写回寄存器文件,因此会把第一项(最早进入项)按照先后顺序把执行结果写入寄存器文件,这个过程叫做retirement。
另外,有些μops是不需要经过EU的处理的,这些μops可以直接在ROB内等待retirement。
ROB Read Port Stalls
如上面的描述,μop在source就绪前会在RS内等待,在此期间,就绪的source会被传送到RS,一旦所有的source都就绪,并且相应的EU可用时,μop就会被调度过去执行。
source分为memory operand、register operand、immediate operand,其中需要等待的只有memory以及register相关的source,我们这里讨论的是register operand。
RS的source入口有三个:
- in flight。μop从EU处理完成后,执行结果会被写回ROB,如果此时RS也有μop需要该结果,则该执行结果作为source进入RS。一般来说,大部分指令的source都是in flight的,并且intel微处理器也基于这种情况对in flight的source传输进行了优化。
- ROB read。如果在执行结果被写回ROB时,RS中并没有需要该结果的μop,则该执行结果不会进入RS,如果后来有新的μop需要以该执行结果作为source,只能从ROB中获取。不过这种获取source的方式可能会带来一些性能上的下降,我们会在下面进行分析。
- register read。如果在执行结果被写回ROB时,RS中并没有需要该结果的μop,则该执行结果不会进入RS,如果后来有新的μop需要以该执行结果作为source,但是此时执行结果已被写回RRF,则直接从RRF中获取。这种情况的出现的机率较小,以Core微处理器为例,Core微处理器上的ROB有96项,RS有32项,也就是说只有当某个μop所需的source来自位于其之前超过128的μop才会出现这种情况。
in flight与register read在传输数据时都很块,问题在于ROB read。ROB向RS传输source的通道被称为ROB read port,每个read port在一个时钟周期内可以传输一个register operand,在P6上有两个read port,到了Core以及Nehalem时为3个。
以Core微处理器为例,现假设有两条如下的指令,并且edi、esi、esp、ebp都要从ROB获取:
mov [edi + esi], eax
mov [esp + ebp], ebx
它们分解成μops:
tmp1 ← edi + esi
mov [tmp1], eax
tmp2 ← esp + ebp
mov [tmp2], ebx
按由于两条指令之间没有依赖关系,所以如果EU可用的话,按理说第一、第三个μop可以同时被调度到不同的ALU(EU)执行。不过由于Core上只有3个read port,因此无法一次性读取四个source,那么就有一个μop需要延迟执行。
从程序上来说,出现这种情况的原因主要是频繁使用了Based Indexed Addressing以及对寄存器写入后间隔较长才去读取。因此避免出现ROB read port stalls的措施也比较简单:不要频繁使用Based Indexed Addressing以及对寄存器的写后读取读操作尽量别间隔太长。
Recent ROB
从Sandy Bridge微处理器开始,intel就采用了全新的ROB pipeline,其中ROB不再用于存储执行结果,而是只用于记录μops的状态,如下图所示

EU在处理完μop后直接写回物理寄存器(PRF)并改变ROB中μop的状态,然后RAT就可以根据ROB中的状态调整PRF映射,使得用户层看起来指令在以in-order的方式执行。这种ROB实现方式没有了ROB read port的限制,因此ROB read port stalls的现象不复存在。
Reference:
Intel® 64 and IA-32 Architectures Optimization Reference Manual
Agner Fog - The microarchitecture of Intel, AMD and VIA CPUs
David Kanter - Inside Nehalem: Intel’s Future Processor and System
David Kanter - Intel’s Sandy Bridge Microarchitecture
Re-Order Buffer的更多相关文章
- MySQL InnoDB存储引擎
200 ? "200px" : this.width)!important;} --> 介绍 本篇文章是对Innodb存储引擎的概念进行一个整体的概括,innodb存储引擎的 ...
- TextureView+SurfaceTexture+OpenGL ES来播放视频(三)
引自:http://www.jianshu.com/p/291ff6ddc164 做好的Demo截图 opengl-video 前言 讲了这么多,可能有人要问了,播放视频用个android封装的Vid ...
- Method and apparatus for speculative execution of uncontended lock instructions
A method and apparatus for executing lock instructions speculatively in an out-of-order processor ar ...
- PatentTips - Compare and exchange operation using sleep-wakeup mechanism
BACKGROUND Typically, a multithreaded processor or a multi-processor system is capable of processing ...
- Java 内存映射文件
import java.io.*; import java.nio.MappedByteBuffer; import java.nio.channels.FileChannel; import jav ...
- Intel Ivy Bridge Microarchitecture Events
This is a list of all Intel Ivy Bridge Microarchitecture performance counter event types. Please see ...
- Intel Sandy Bridge Microarchitecture Events
This is a list of all Intel Sandy Bridge Microarchitecture performance counter event types. Please s ...
- 【基础知识】Intel CPU体系结构|x86是什么意思
看了<计算机系统结构>.<深入理解计算机系统>.<大话处理器>等经典书籍,也在google上搜了一大堆资料,前前后后.断断续续的折腾了一个多月,终于想通了,现在把自 ...
- nodejs(三)Buffer module & Byte Order
一.目录 ➤ Understanding why you need buffers in Node ➤ Creating a buffer from a string ➤ Converting a b ...
- JAVA NIO Buffer
所谓的输入,输出,就是把数据移除或移入缓冲区. 硬件不能直接访问用户控件(JVM). 基于存储的硬件设备操控的是固定大小的数据块儿,用户请求的是任意大小的或非对齐的数据块儿. 虚拟内存:使用虚 ...
随机推荐
- 【1414软工助教】团队作业4——第一次项目冲刺(Alpha版本) 得分榜
题目 团队作业4--第一次项目冲刺(Alpha版本) 作业提交情况情况 所有团队都在规定时间内完成了七次冲刺. 往期成绩 个人作业1:四则运算控制台 结对项目1:GUI 个人作业2:案例分析 结对项目 ...
- 201521123091 《Java程序设计》第12周学习总结
Java 第十一周总结 第十一周的作业. 目录 1.本章学习总结 2.Java Q&A 3.码云上代码提交记录及PTA实验总结 4.课后阅读 1.本章学习总结 1.1 以你喜欢的方式(思维导图 ...
- Swing-JRadioButton用法-入门
JRadioButton是Swing中的单选框.所谓单选框是指,在同一个组内虽然有多个单选框存在,然而同一时刻只能有一个单选框处于选中状态.它就像收音机的按钮,按下一个时此前被按下的会自动弹起,故因此 ...
- 团队作业4——第一次项目冲刺(Alpha版本)日志集合处
Day 1: http://www.cnblogs.com/TeamOf/p/6754373.html Day 2: http://www.cnblogs.com/TeamOf/p/6754410.h ...
- Java201521123071《Java程序设计》第八周学习总结
第八周-集合与泛型 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结集合与泛型相关内容. 1. <T extends Comparable>表示T是绑定类型(Compa ...
- 201521123070 《JAVA程序设计》第6周学习总结
1. 本章学习总结 1.1 面向对象学习暂告一段落,请使用思维导图,以封装.继承.多态为核心概念画一张思维导图,对面向对象思想进行一个总结. 注1:关键词与内容不求多,但概念之间的联系要清晰,内容覆盖 ...
- java201521123118《java程序设计》第5周总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关多态与接口的知识点. 2. 书面作业 1. 代码阅读:Child压缩包内源代码 1.1 com.parent包中Child.java文件能否编译通过 ...
- 201521123054《Java程序设计》第1周学习总结
#1. 本章学习总结 你对于本章知识的学习总结 本章我们学习了各种java相关文件的使用,能够进行基本的程序操作: 学会使用博客.码云与PTA管理java: #2. 书面作业 1.为什么java程序可 ...
- 201521123024 java 第十周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常与多线程相关内容. 2. 书面作业 本次PTA作业题集异常.多线程 finally 题目4-2 1.1 截图你的提交结果(出现学 ...
- Nim函数调用的几种形
Nim函数调用的几种形式 Nim 转载条件:如果你需要转载本文,你需要做到完整转载本文所有的内容,不得删改文内的作者名字与链接.否则拒绝转载. 关于nim的例行介绍: Nim 是一门静态编译型的系统级 ...