Hadoop的介绍、搭建、环境
HADOOP背景介绍
1.1Hadoop产生背景
- HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
- 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。(谷歌为现代技术做了十分大的贡献!!)
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
- Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
1.2 什么是HADOOP
- HADOOP是apache旗下的一套开源软件平台(apache软件几乎都开源)
- HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
- HADOOP的核心组件有
- HDFS(分布式文件系统)
- YARN(运算资源调度系统)
- MAPREDUCE(分布式 运算编程框架)
1.3 HADOOP在大数据、云计算中的位置和关系
1. 云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
2. 现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术。
3. 而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
1.4Hadoop生态系统

HDFS:分布式文件系统(hdfs、MAPREDUCE、yarn)元老级大数据处理技术框架,擅长离线数据分析
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具,使用方便,功能丰富。但基于MR会有很大的延迟。
HBASE:基于HADOOP的分布式海量数据库,离线分析和在线业务通吃, 是 Google Bigtable 的另一套开源实现。
ZOOKEEPER:分布式协调服务基础组件,提供的功能包括:配置维护、名字服务、 分布式同步、心跳、组服务等
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库提供可扩展的计算机学习领域的算法实现,旨在帮助开发人员更加快捷地开发智能 应用程序。
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
Avro: 基于JSON的数据序列化的系统。
Cassandra: 一套分布式,非关系型存储系统,类似Google - BigTable。
Chukwa: 用于监控大型分布式系统的数据采集系统。
Pig:提供一个并行执行的数据流框架。
Spark:类似MapReduce的通用并行框架,继承了其的分布式优势,只是中间输出结果存储 于内存中,提供了相对实时性的处理能力
Tez:新的一套分布式执行框架,主要以开发人员为最终用户构建性能更快、扩展性更强的应 用程序。
1.5Hadoop大数据项目流程图
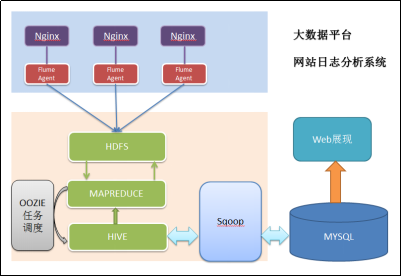
1) 数据采集:定制开发采集程序,或使用开源框架FLUME
2) 数据预处理:定制开发mapreduce程序运行于hadoop集群
3) 数据仓库技术:基于hadoop之上的Hive
4) 数据导出:基于hadoop的sqoop数据导入导出工具
5) 数据可视化:定制开发web程序或使用kettle等产品
6) 整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
Hadoop的介绍、搭建、环境的更多相关文章
- Hadoop笔记之搭建环境
Hadoop的环境搭建分为单机模式.伪分布式模式.完全分布式模式. 因为我的本本比较挫,所以就使用伪分布式模式. 安装JDK 一般Linux自带的Java运行环境都是Open JDK,我们到官网下载O ...
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
- 环境搭建-Hadoop集群搭建
环境搭建-Hadoop集群搭建 写在前面,前面我们快速搭建好了centos的集群环境,接下来,我们就来开始hadoop的集群的搭建工作 实验环境 Hadoop版本:CDH 5.7.0 这里,我想说一下 ...
- 【深入浅出 Yarn 架构与实现】1-2 搭建 Hadoop 源码阅读环境
本文将介绍如何使用 idea 搭建 Hadoop 源码阅读环境.(默认已安装好 Java.Maven 环境) 一.搭建源码阅读环境 一)idea 导入 hadoop 工程 从 github 上拉取代码 ...
- Hadoop学习笔记—1.基本介绍与环境配置
一.Hadoop的发展历史 说到Hadoop的起源,不得不说到一个传奇的IT公司—全球IT技术的引领者Google.Google(自称)为云计算概念的提出者,在自身多年的搜索引擎业务中构建了突破性的G ...
- 使用WIF实现单点登录Part I——Windows Identity Foundation介绍及环境搭建
首先先说一下什么是WIF(Windows Identity Foundation).由于各种历史原因,身份验证和标识的管理一般都比较无规律可循.在软件里加入“身份验证”功能意味着要在你的代码里混进处理 ...
- 使用WIF实现单点登录Part I——Windows Identity Foundation介绍及环境搭建 -摘自网络
上个月有一个星期的时间都在研究asp.net mvc统一身份验证及单点登录的实现.经过了一番的探索,最终决定使用微软的Windows Identity Foundation.但是这东西用的人貌似不多, ...
- Linux巩固记录(3) hadoop 2.7.4 环境搭建
由于要近期使用hadoop等进行相关任务执行,操作linux时候就多了 以前只在linux上配置J2EE项目执行环境,无非配置下jdk,部署tomcat,再通过docker或者jenkins自动部署上 ...
- Hadoop介绍和环境配置
原文:http://www.cnblogs.com/edisonchou/ 一.Hadoop的发展历史 说到Hadoop的起源,不得不说到一个传奇的IT公司-全球IT技术的引领者Google.Goog ...
- Hibernate 介绍及其 环境搭建
介绍 数据持久化概念 数据持久化是将内存中的数据模型转换为存储模型,以及将存储模型转换为内存中的数据模型的统称.例如:文件的存储.数据的读取等都是数据持久化操作.数据模型可以是任何数据结构或对象模型, ...
随机推荐
- HTML输入框只能输入数字或数字字母组合
JS判断只能是数字和小数点 1.文本框只能输入数字代码(小数点也不能输入) <input onkeyup="this.value=this.value.replace(/\D/g,'' ...
- M41T11-RTC(实时时钟)
一.理论准备 1. 主要器件:STM8单片机.M41T11时钟IC.32.768kHz晶振等. 2. 外围设备:烧录工具ST-Link/v2.串口.5v供电SATA线. 3. 主要思想:通过单片机对时 ...
- html加javascript和canvas类似超级玛丽游戏
html加javascript和canvas制作 代码来源于网上 复制可用 <!doctype html><html lang="en"> <head ...
- 在ROS中使用花生壳的域名服务
ROS功能强大,也比较复杂,各个版本的脚本可能也大同小异,我现在使用的是6.37.3的版本. 添加Script 进入菜单System->Scripts. 点击加号,像图中这样,添加代码,我给这段 ...
- linux定时任务访问url
这次linux定时任务设置成功,也算是自己学习linux中一个小小的里程碑.:) 撒花撒花--- 以下操作均是在ubuntu 下操作的,亲测有效,其他的linux系统还望亲们自己去查.鞠躬感谢! 1 ...
- zookeeper 应用场景概述
Zookeeper主要可以干哪些事情:配置管理,名字服务,提供分布式同步以及集群管理. 一 .配置管理 在我们的应用中除了代码外,还有一些就是各种配置.比如数据库连接,远程服务访问地址等.一般我们都是 ...
- 行内元素和块级元素的具体区别是什么?行内元素的padding和margin可设置吗?
块级元素(block)特性: 总是独占一行,表现为另起一行开始,而且其后的元素也必须另起一行显示; 宽度(width).高度(height).内边距(padding)和外边距(margin)都可控制; ...
- qt中setStyleSheet导致的内存泄漏
原始日期: 2017-01-05 19:31 现象:程序运行至某一个界面下,内存出现缓慢持续的占用内存增长 原因:经过排查,确定是在事件派发的槽函数中频繁重复调用setStyleSheet导致的 ...
- 跨域访问之JSONP
跨域 在平常的工作中常常会遇到A站点的需要访问B站点的资源. 这时就产生了跨域访问. 跨域是指从一个域名的网页去请求另一个域名的资源.浏览器遵循同源策略,不允许A站点的Javascript 读取B站点 ...
- 从Owin到System.Web.Http.Owin的HttpMessageHandlerAdapter看适配器模式
.mytitle { background: #2B6695; color: white; font-family: "微软雅黑", "宋体", "黑 ...