用python的requests第三方模块抓取王者荣耀所有英雄的皮肤
本文使用python的第三方模块requests爬取王者荣耀所有英雄的图片,并将图片按每个英雄为一个目录存入文件夹中,方便用作桌面壁纸
下面时具体的代码,已通过python3.6测试,可以成功运行:
对于所要爬取的网页连接可以通过王者荣耀官网找到,
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 13 13:49:52 2017 @author:KillerTwo
"""
import requests
import os
hero_list_url = 'http://pvp.qq.com/web201605/js/herolist.json'
hero_skin_root_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'
skin_base_dir = 'C:\\Users\\lwt27\\Pictures\\image\\heroskin\\' def get_ename(hero_json):#传入获取到的python对象,如hero_list_json
'''获取英雄名称对应英雄编号的一个字典,例如{小乔:106,...}'''
cname_ename = {}
for hero in hero_json:
cname_ename[hero['cname']] = hero['ename']
return cname_ename def get_skin_name(hero_json): #传入从网页获取到的json转换为python字典的对象
'''获取英雄名称对应的皮肤的所有皮肤名称的字典,例如
{'小乔':'恋之微风|万圣前夜|天鹅之梦|纯白花嫁|缤纷独角兽',...}'''
cname_skin_name = {}
for hero in hero_json:
cname_skin_name[hero['cname']] = hero['skin_name']
return cname_skin_name def get_hero_skin_count(cname_skin_name): #传入英雄名称对应皮肤名称的字典
'''获取每个英雄对应的皮肤的个数,例如{'小乔':5,...}'''
cname_skin_count = {}
for item in cname_skin_name.items():
cname_skin_count[item[0]] = len(item[1].split('|'))
return cname_skin_count def get_skin_name_url(skin_base_rul,cname_skin_count,cname_ename):
#传入皮肤根地址和名称对应皮肤数量的字典和名称对应编号的字典
'''返回英雄名称对应的所有皮肤的url地址列表的字典,例如{小乔:[skin_url1,skin_url2],...}'''
cname_url_list = {}
for cname,count in cname_skin_count.items():
#print(cname)
#print(count)
#print(skin_base_rul)
#print(cname_ename[cname])
base_url = skin_base_rul+str(cname_ename[cname])+'/'+str(cname_ename[cname])+'-bigskin-'
#print(base_url)
skin_url_list = [str(base_url)+str(num)+'.jpg' for num in range(1,count+1)]
cname_url_list[cname] = skin_url_list
return cname_url_list #print()
d = get_skin_name_url(hero_skin_root_url,get_hero_skin_count(get_skin_name(hero_list_json)),get_ename(hero_list_json))
#print(d) def get_cname_skin_name(cname_skin_name):#传入名称对应皮肤名称字符串的字典
cname_skin_name_dict = {} #返回名称对应【皮肤名称的列表】的字典
for cname,skin_name_list in cname_skin_name.items():
skin_list = [name for name in skin_name_list.split('|')]
cname_skin_name_dict[cname] = skin_list
return cname_skin_name_dict #s = get_skin_name(hero_list_json)
#print(s)
#f = get_cname_skin_name(s)
#print(f) def get_hero_skin(cname_url_list,cname_skin_name):#传入名称对应【皮肤名称列表】的字典和名称对应皮肤url列表的字典
# """获取每个英雄的图片"""
for cname,skin_url in cname_url_list.items(): if mkdir(skin_base_dir+cname):#创建指定目录
os.chdir(skin_base_dir+cname) #进入到创建的目录 for i in range(len(skin_url)):
file_name = cname_skin_name[cname][i]+'.jpg'
r = requests.get(skin_url[i])
with open(file_name,'wb') as f:
f.write(r.content)
#创建目录
def mkdir(path):
# 引入模块
import os
# 去除首位空格
path=path.strip()
# 去除尾部 \ 符号
path=path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists=os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path+' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path+' 目录已存在')
return False
return if __name__ == '__main__': hero_list_body = requests.get(hero_list_url) #请求英雄列表
hero_list_json = hero_list_body.json() #将英雄列表的获取的json数据转换为python对象 cname_ename = {} #英雄名称对应英雄编号的字典
cname__skin_name = {} #英雄名称对应皮肤名称字符串的字典
cname_skin_count = {} #英雄名称对应皮肤数量的字典 cname_skin_name_str_list = get_skin_name(hero_list_json)
cname_skin_name_list = get_cname_skin_name(cname_skin_name_str_list)
cname_skin_count = get_hero_skin_count(cname_skin_name_str_list)
cname_ename = get_ename(hero_list_json)
cnam_skin_url_list = get_skin_name_url(hero_skin_root_url,cname_skin_count,cname_ename)
get_hero_skin(cnam_skin_url_list,cname_skin_name_list)
下面是保存抓取到的图片的文件夹样例:
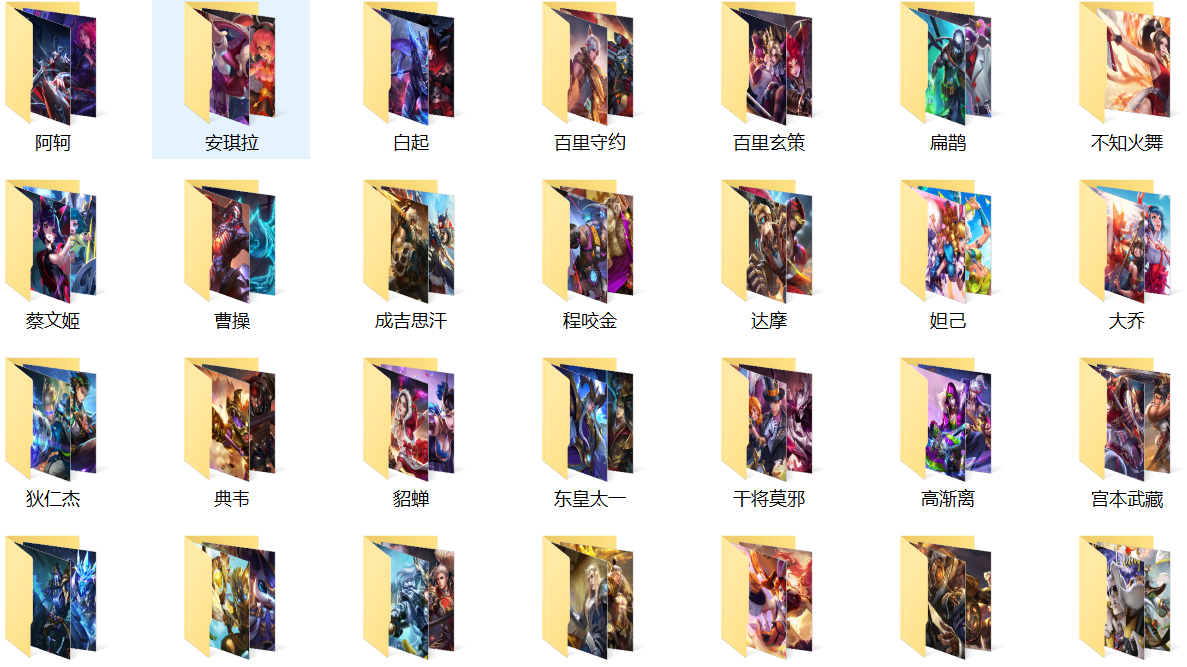
以上就是抓取王者荣耀所有英雄皮肤的简单示例,上述的代码并没有使用python多线程执行抓取图片的函数,所以在执行的时候可能需要花费几分钟的时间,
以后在进行改进,添加使用python多线程执行抓取任务。
用python的requests第三方模块抓取王者荣耀所有英雄的皮肤的更多相关文章
- python安装requests第三方模块
2018-08-28 22:04:51 1 .下载到桌面后解压,放到python的目录下 ------------------------------------------------------- ...
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
- python接口测试中安装whl格式的requests第三方模块
下载 安装 requests第三方模块 下载:http://docs.python-requests.org/en/latest/user/install/#install 我下载是 https:// ...
- Python爬虫【三】利用requests和正则抓取猫眼电影网上排名前100的电影
#利用requests和正则抓取猫眼电影网上排名前100的电影 import requests from requests.exceptions import RequestException imp ...
- python爬虫beta版之抓取知乎单页面回答(low 逼版)
闲着无聊,逛知乎.发现想找点有意思的回答也不容易,就想说要不写个爬虫帮我把点赞数最多的给我搞下来方便阅读,也许还能做做数据分析(意淫中--) 鉴于之前用python写爬虫,帮运营人员抓取过京东的商品品 ...
- Python-Windows下安装BeautifulSoup和requests第三方模块
http://blog.csdn.net/yannanxiu/article/details/50432498 首先给出官网地址: 1.Request官网 2.BeautifulSoup官网 我下载的 ...
- 一次Python爬虫的修改,抓取淘宝MM照片
这篇文章是2016-3-2写的,时隔一年了,淘宝的验证机制也有了改变.代码不一定有效,保留着作为一种代码学习. 崔大哥这有篇>>小白爬虫第一弹之抓取妹子图 不失为学python爬虫的绝佳教 ...
- 利用python脚本(xpath)抓取数据
有人会问re和xpath是什么关系?如果你了解js与jquery,那么这个就很好理解了. 上一篇:利用python脚本(re)抓取美空mm图片 # -*- coding:utf-8 -*- from ...
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
随机推荐
- Python CRM项目二
一.准备工作 如果没有配置基本的项目,请参考 http://www.cnblogs.com/luhuajun/p/7771196.html 当我们配置完成后首先准备我们的app 创建2个app分别对应 ...
- PHP(一)OOP基础
[面向过程&面向对象] 1.面向过程:专注于解决一件事情的过程.最大的特点,是有一个个函数来实现功能需求 2.面向对象:专注于有哪一个对象来实现这个功能,最大的特点,时产生一个个具有属性和方法 ...
- SSH框架的多表查询和增删查改 (方法一)中
原创作品,允许转载,转载时请务必标明作者信息和声明本文章==>http://www.cnblogs.com/zhu520/p/7774144.html 这边文章是接的刚刚前一遍的基础上敲的 ...
- 节点遍历 element traversal
任何一个node节点都可以作为遍历的根(traversal root),然后遍历该节点本身以及后代元素,不能遍历祖先或者兄弟元素,方向可以反转 <div id=”div1”> < ...
- HTML学习笔记 域元素(form表单、textarea文本域、fieldset域集合、input使用) 案例 第四节 (原创)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- c#params应用
params 是C#开发语言中关键字, params主要的用处是在给函数传参数的时候用,就是当函数的参数不固定的时候. 在方法声明中的 params 关键字之后不允许任何其他参数,并且在方法声明中只允 ...
- vim如何显示行号
在 vim 里执行(在普通模式下直接按冒号,并输入下面的命令 :set number 回车后就可以显示行号了,但重启 vim 后又会恢复默认的设置. 要想每次进入 vim 都显示行号就需要配置 vim ...
- Thrift全面介绍
官网:http://thrift.apache.org 简介 Thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发.它结合了功能强大的软件堆栈和代码生成引擎,以构建在 C++, Java ...
- IE6常见CSS解析Bug及hack
IE6常见CSS兼容问题总结 1)图片间隙 A)div中的图片间隙(该bug出现在IE6及更低版本中) 描述:在div中插入图片时,图片会将div下方撑大三像素. hack1:将</div> ...
- 照虎画猫写自己的Spring
从细节跳出来 看了部分Spring的代码,前面用了四篇内容写了一些读书笔记. 回想起来,论复杂度,Spring够喝上好几壶的.他就像一颗枝繁叶茂的大树,远处看,只是一片绿:走近看,他为你撑起一片小天地 ...