Pandas常用函数入门
一.Pandas
Python Data Analysis Library或Pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
二.Series
Series是一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型。
1.创建
# 通过list创建Series
s1 = pd.Series([7, 3, 6, 2, 9, 5, 8])
# 通过dict创建Series
s2 = pd.Series({"a":1, "b":2, "c":3})
# 通过list创建Series,并指定index
s3 = pd.Series([5, 2, 7, 4],["a", "b", "c", "b"])

2.选取
# 获取前3个数据
s1.head(3)
# 获取后3个数据
s1.tail(3)
# 获取index为2的数据
s1[2]
# 获取1<=index<4的数据
s1[1:4]
# 获取index>3的数据
s1[s1.index>3]
# 获取数据值>5的数据
s1[s1>5]
3.增加、删除、修改
# 增加数据index=8
s1[8] = -1
# 删除数据index=3,不修改原Series
s1 = s1.drop(3)
# 对1<=index<3的数据赋值30
s1[1:3] = 30
# 对index为4,6的数据赋值50
s1[4, 6] = 50
三.DataFrame
DataFrame是二维的表格型数据结构。可以将DataFrame理解为Series的容器。
1.创建
# 通过dict创建DataFrame
data = {'name':["google", "amazon", "apple", "youtube", "oracle"], 'age':[33, 44, 11, 66, 44], "money" : [400, 200, 100, 800, 500]}
df1 = pd.DataFrame(data, columns = ["name", "age", "money"])

2.时间序列类型index
# 月
dates = pd.date_range('2017-10-08', periods = 10, freq = "M")
# 天
dates = pd.date_range('2017-10-08', periods = 10, freq = "D")
# 时
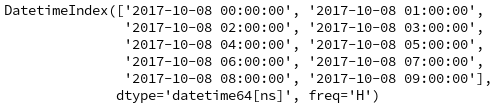
dates = pd.date_range('2017-10-08', periods = 10, freq = "H")
3.选取
# 获取前3行数据
df1.head(3)
# 获取后3行数据
df1.tail(3)
# 获取列
df1.name, df1['name'], df1[["name", "money"]]
# 获取行
df1[0:3], df1.loc[0:3]
# 同时获取行列
df1.loc[0:3, ["name", "money"]]
4.增加、删除、修改
# 增加列
df1["new"] = 6
# 删除列,不修改原DataFrame
df1 = df1.drop("new", axis = 1)
# 增加行,修改原DataFrame
df1.loc[df1.index.max() + 1] = {"name": "microsoft", "age": 70, "money": 300}
# 增加行,不修改原DataFrame
df1 = df1.append([{"name": "facebook", "age": 701, "money": 900}], ignore_index = True)
# 删除行,不修改原DataFrame
df1 = df1.drop([2])
# 修改数据
df1.loc[5,"age"] = 888
df1.loc[8:10, ["age", "money"]] = [11, 222]
5.WHERE
# 过滤数据,使用DataFrame.dtypes查看数据类型
df1[df1["age"] > 30]
df1[(df1["age"] > 30) & (df1["money"] < 600)], df1[(df1.age > 40) & (df1.money < 600)]
df1[df1["name"].isin(["amazon", "youtube"])]
6.DISTINCT
# 去重
df1.age.drop_duplicates()
df1[["age", "money"]].drop_duplicates()
7.JOIN
# 联接
df3 = pd.merge(df1, df2, how="left", left_on = "name", right_on = "name")
df3 = pd.merge(df1, df2, how="right", left_on = "name", right_on = "name")
8.GROUP BY
# 分组
df1.groupby("age")["money"].sum()
df1.groupby(["age", "name"])["money"].count()
9.ORDER BY
# 排序
df1.sort_values("age", ascending=True)
df1.sort_values(["age", "money"], ascending=[True, False])
10.UNION
# 合并
df2 = df1.copy(True)
df3 = pd.concat([df1,df2], ignore_index = True)
df3 = df1.append(df2, ignore_index = True)
11.导入和保存
Excel格式需要安装openpyxl、xlrd包
# 保存为csv格式
df1.to_csv("data.csv", encoding="utf-8")
# 从csv文件读取
df1 = pd.read_csv("data.csv")
# 保存为excel格式
df1.to_excel("data.xlsx", sheet_name = "Sheet1", encoding="utf-8")
# 从excel文件读取
df1 = pd.read_excel("data.xlsx", sheet_name = "Sheet1")
Pandas常用函数入门的更多相关文章
- pandas常用函数之shift
shift函数是对数据进行移动的操作,假如现在有一个DataFrame数据df,如下所示: index value1 A 0 B 1 C 2 D 3 那么如果执行以下代码: df.shift() 就会 ...
- pandas常用函数之diff
diff函数是用来将数据进行某种移动之后与原数据进行比较得出的差异数据,举个例子,现在有一个DataFrame类型的数据df,如下: index value1 A 0 B 1 C 2 D 3 如果执行 ...
- pandas 常用函数整理
pandas常用函数整理,作为个人笔记. 仅标记函数大概用途做索引用,具体使用方式请参照pandas官方技术文档. 约定 from pandas import Series, DataFrame im ...
- 【转载】pandas常用函数
原文链接:https://www.cnblogs.com/rexyan/p/7975707.html 一.import语句 import pandas as pd import numpy as np ...
- pandas常用函数
1. df.head(n): 显示数据前n行,不指定n,df.head则会显示所有的行 2. df.columns.values获取所有列索引的名称 3. df.column_name: 直接获取列c ...
- 整理 pandas 常用函数
1. df.head(n): 显示数据前n行,不指定n,df.head则会显示所有的行 2. df.columns.values获取所有列索引的名称 3. df.column_name: 直接获取列c ...
- 5.2 pandas 常用函数清单
文件读取 df = pd.read_csv(path='file.csv') 参数:header=None 用默认列名,0,1,2,3... names=['A', 'B', 'C'...] 自定义列 ...
- python,pandas常用函数
一.rename,更改df的列名和行索引 df=pd.DataFrame(np.arange(,).reshape(,)) print(df) print(type(df)) 结果为: <cla ...
- pandas 常用函数
随机推荐
- 第5章 不要让线程成为脱缰的野马(Keeping your Threads on Leash) ----初始化一个线程
使用线程的一个常见问题就是如何能够在一个线程开始运行之前,适当地将它初始化.初始化最常见的理由就是为了调整优先权.另一个理由是为了在SMP 系统中设定线程比较喜欢的 CPU.第10 章谈到 MFC 时 ...
- Corn Fields poj3254(状态压缩DP)
Corn Fields Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 6081 Accepted: 3226 Descr ...
- 宝藏(树形DP)
这道题目是十分考验思维的,n^2应该还是比较好想的,主要是如何转移根的问题.转移根,在我看来应该是树形dp最难的一部分了, 一般学会如何转移根,也就差不多考验通吃树形dp了. 下面转一转大佬链接: ...
- redis C接口hiredis 简单函数使用介绍
hiredis是redis数据库的C接口,目前只能在linux下使用,几个基本的函数就可以操作redis数据库了. 函数原型:redisContext *redisConnect(const char ...
- “一切都是消息”--MSF(消息服务框架)之【请求-响应】模式
在前一篇, “一切都是消息”--MSF(消息服务框架)入门简介, 我们介绍了MSF基于异步通信,支持请求-响应通信模式和发布-订阅通信模式,并且介绍了如何获取MSF.今天,我们来看看如何使用MSF来做 ...
- CentOS7.3下部署Rsyslog+LogAnalyzer+MySQL中央日志服务器
一.简介 1.LogAnalyzer 是一款syslog日志和其他网络事件数据的Web前端.它提供了对日志的简单浏览.搜索.基本分析和一些图表报告的功能.数据可以从数据库或一般的syslog文本文件中 ...
- vue-cli 自定义指令directive 添加验证滑块
vue项目注册登录页面遇到了一个需要滑块的功能,网上看了很多插件发现都不太好用,于是自己写了一个插件供大家参考: 用的是vue的自定义指令direcive,只需要在需要的组件里放入对应的标签嵌套即可: ...
- (@WhiteTaken)设计模式学习——代理模式
今天学习了一下代理模式,代理模式分为很多种.目前感觉有两种是需要学习一下的. 静态代理模式 动态代理模式 1. 静态代理模式 需要被代理的类,实现一个或者多个接口. 代理类需要实现被代理类的接口,在此 ...
- win10 uwp 视差效果
本文翻译:http://jamescroft.co.uk/blog/uwp/playing-with-scrolling-parallax-effects-on-ui-elements-in-wind ...
- 新型勒索软件Magniber正瞄准韩国、亚太地区开展攻击
近期,有国外研究人员发现了一种新型的勒索软件,并将其命名为Magniber,值得注意的是,这款勒索软只针对韩国及亚太地区的用户开展攻击.该勒索软件是基于Magnitude exploit kit(简称 ...